
使用 faker 和 pandas Python 庫建立用於測試的綜合數據
 瀏覽:556
瀏覽:556
介绍:
全面的测试对于数据驱动的应用程序至关重要,但它通常依赖于拥有正确的数据集,而这些数据集可能并不总是可用。无论您是开发 Web 应用程序、机器学习模型还是后端系统,真实且结构化的数据对于正确验证和确保稳健的性能至关重要。由于隐私问题、许可限制或仅仅是相关数据的不可用,获取真实世界数据可能会受到限制。这就是合成数据变得有价值的地方。
在本博客中,我们将探讨如何使用Python为不同场景生成合成数据,包括:
- 相关表:表示一对多关系。
- 分层数据:常用于组织结构。
- 复杂关系:如招生系统中的多对多关系。
我们将利用 faker 和 pandas 库为这些用例创建真实的数据集。
示例 1:为客户和订单创建综合数据(一对多关系)
在许多应用中,数据存储在具有外键关系的多个表中。让我们为客户及其订单生成综合数据。一个客户可以下多个订单,代表一对多的关系。
生成客户表
Customers 表包含基本信息,例如 CustomerID、姓名和电子邮件地址。
import pandas as pd
from faker import Faker
import random
fake = Faker()
def generate_customers(num_customers):
customers = []
for _ in range(num_customers):
customer_id = fake.uuid4()
name = fake.name()
email = fake.email()
customers.append({'CustomerID': customer_id, 'CustomerName': name, 'Email': email})
return pd.DataFrame(customers)
customers_df = generate_customers(10)
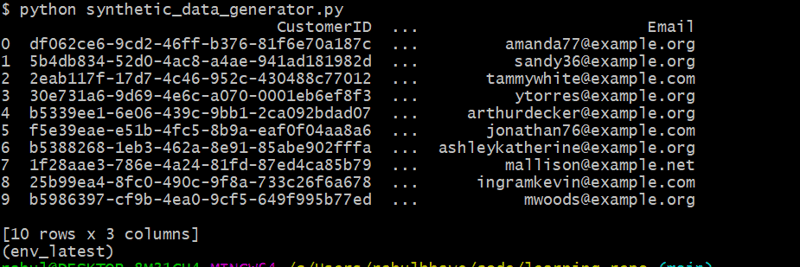
此代码使用 Faker 生成 10 个随机客户,以创建真实的姓名和电子邮件地址。
生成订单表
现在,我们生成 Orders 表,其中每个订单通过 CustomerID 与客户关联。
def generate_orders(customers_df, num_orders):
orders = []
for _ in range(num_orders):
order_id = fake.uuid4()
customer_id = random.choice(customers_df['CustomerID'].tolist())
product = fake.random_element(elements=('Laptop', 'Phone', 'Tablet', 'Headphones'))
price = round(random.uniform(100, 2000), 2)
orders.append({'OrderID': order_id, 'CustomerID': customer_id, 'Product': product, 'Price': price})
return pd.DataFrame(orders)
orders_df = generate_orders(customers_df, 30)
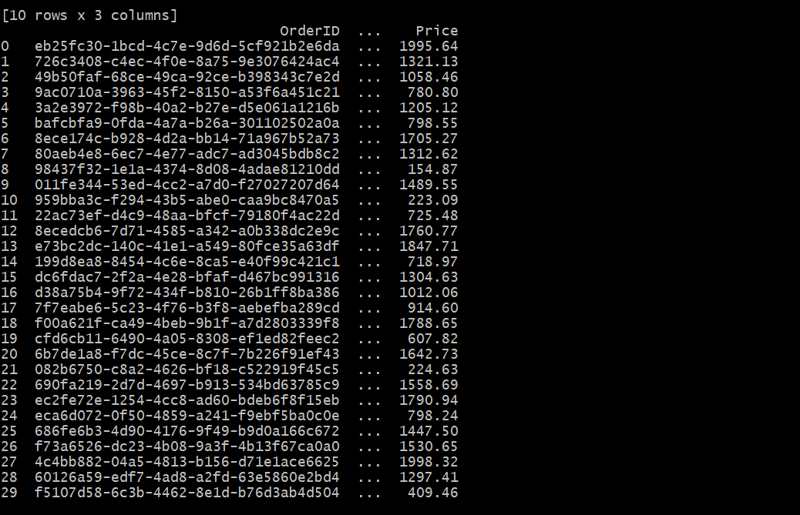
在本例中,Orders 表使用 CustomerID 将每个订单链接到客户。每个客户可以下多个订单,形成一对多的关系。
示例 2:生成部门和员工的层次结构数据
层次结构数据通常用于部门有多名员工的组织环境中。让我们模拟一个具有部门的组织,每个部门都有多名员工。
生成部门表
Departments 表包含每个部门唯一的 DepartmentID、名称和经理。
def generate_departments(num_departments):
departments = []
for _ in range(num_departments):
department_id = fake.uuid4()
department_name = fake.company_suffix()
manager = fake.name()
departments.append({'DepartmentID': department_id, 'DepartmentName': department_name, 'Manager': manager})
return pd.DataFrame(departments)
departments_df = generate_departments(10)
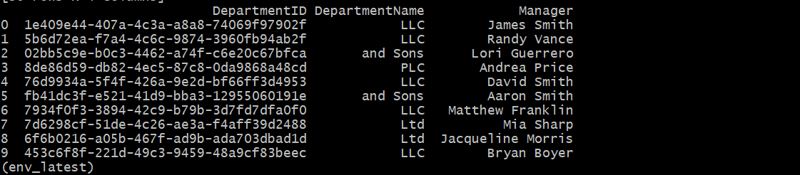
生成员工表
接下来,我们生成Employees表,其中每个员工通过DepartmentID与一个部门相关联。
def generate_employees(departments_df, num_employees):
employees = []
for _ in range(num_employees):
employee_id = fake.uuid4()
employee_name = fake.name()
email = fake.email()
department_id = random.choice(departments_df['DepartmentID'].tolist())
salary = round(random.uniform(40000, 120000), 2)
employees.append({
'EmployeeID': employee_id,
'EmployeeName': employee_name,
'Email': email,
'DepartmentID': department_id,
'Salary': salary
})
return pd.DataFrame(employees)
employees_df = generate_employees(departments_df, 100)
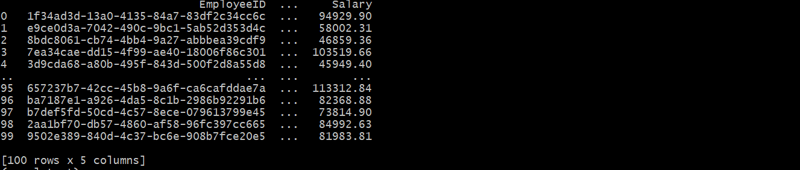
这种层次结构通过DepartmentID将每个员工与一个部门联系起来,形成父子关系。
示例 3:模拟课程注册的多对多关系
在某些场景中,存在多对多关系,其中一个实体与许多其他实体相关。让我们用注册多个课程的学生来模拟这一点,其中每个课程都有多个学生。
生成课程表
def generate_courses(num_courses):
courses = []
for _ in range(num_courses):
course_id = fake.uuid4()
course_name = fake.bs().title()
instructor = fake.name()
courses.append({'CourseID': course_id, 'CourseName': course_name, 'Instructor': instructor})
return pd.DataFrame(courses)
courses_df = generate_courses(20)
生成学生表
def generate_students(num_students):
students = []
for _ in range(num_students):
student_id = fake.uuid4()
student_name = fake.name()
email = fake.email()
students.append({'StudentID': student_id, 'StudentName': student_name, 'Email': email})
return pd.DataFrame(students)
students_df = generate_students(50)
print(students_df)
生成课程报名表
CourseEnrollments 表捕获学生和课程之间的多对多关系。
def generate_course_enrollments(students_df, courses_df, num_enrollments):
enrollments = []
for _ in range(num_enrollments):
enrollment_id = fake.uuid4()
student_id = random.choice(students_df['StudentID'].tolist())
course_id = random.choice(courses_df['CourseID'].tolist())
enrollment_date = fake.date_this_year()
enrollments.append({
'EnrollmentID': enrollment_id,
'StudentID': student_id,
'CourseID': course_id,
'EnrollmentDate': enrollment_date
})
return pd.DataFrame(enrollments)
enrollments_df = generate_course_enrollments(students_df, courses_df, 200)
在此示例中,我们创建一个链接表来表示学生和课程之间的多对多关系。
结论:
使用 Python 以及 Faker 和 Pandas 等库,您可以生成真实且多样化的合成数据集,以满足各种测试需求。在此博客中,我们介绍了:
- 相关表:展示客户和订单之间的一对多关系。
- 分层数据:说明部门和员工之间的父子关系。
- 复杂关系:模拟学生和课程之间的多对多关系。
这些示例为生成适合您需求的合成数据奠定了基础。进一步的增强功能,例如创建更复杂的关系、为特定数据库定制数据或扩展数据集以进行性能测试,可以将合成数据生成提升到一个新的水平。
这些示例为生成合成数据提供了坚实的基础。然而,可以进行进一步的增强以增加复杂性和特异性,例如:
- 数据库特定数据:为不同数据库系统定制数据生成(例如,SQL 与 NoSQL)。
- 更复杂的关系:创建额外的相互依赖关系,例如时间关系、多级层次结构或唯一约束。
- 扩展数据:生成更大的数据集以进行性能测试或压力测试,确保系统能够大规模处理现实世界的条件。 通过生成根据您的需求定制的合成数据,您可以模拟开发、测试和优化应用程序的实际条件,而无需依赖敏感或难以获取的数据集。
如果您喜欢这篇文章,请与您的朋友和同事分享。您可以在 LinkedIn 上与我联系,讨论任何进一步的想法。
-
 Python中嵌套函數與閉包的區別是什麼嵌套函數與python 在python中的嵌套函數不被考慮閉合,因為它們不符合以下要求:不訪問局部範圍scliables to incling scliables在封裝範圍外執行範圍的局部範圍。 make_printer(msg): DEF打印機(): 打印(味精) ...程式設計 發佈於2025-04-27
Python中嵌套函數與閉包的區別是什麼嵌套函數與python 在python中的嵌套函數不被考慮閉合,因為它們不符合以下要求:不訪問局部範圍scliables to incling scliables在封裝範圍外執行範圍的局部範圍。 make_printer(msg): DEF打印機(): 打印(味精) ...程式設計 發佈於2025-04-27 -
如何使用Depimal.parse()中的指數表示法中的數字?在嘗試使用Decimal.parse(“ 1.2345e-02”中的指數符號表示法表示的字符串時,您可能會遇到錯誤。這是因為默認解析方法無法識別指數符號。 成功解析這樣的字符串,您需要明確指定它代表浮點數。您可以使用numbersTyles.Float樣式進行此操作,如下所示:[&& && && ...程式設計 發佈於2025-04-27
-
在Python中如何創建動態變量?在Python 中,動態創建變量的功能可以是一種強大的工具,尤其是在使用複雜的數據結構或算法時,Dynamic Variable Creation的動態變量創建。 Python提供了幾種創造性的方法來實現這一目標。 利用dictionaries 一種有效的方法是利用字典。字典允許您動態創建密鑰並...程式設計 發佈於2025-04-27
-
\“(1)vs.(;;):編譯器優化是否消除了性能差異?\”答案: 在大多數現代編譯器中,while(1)和(1)和(;;)之間沒有性能差異。編譯器: perl: 1 輸入 - > 2 2 NextState(Main 2 -E:1)V-> 3 9 Leaveloop VK/2-> A 3 toterloop(next-> 8 last-> 9 ...程式設計 發佈於2025-04-27
-
在JavaScript中如何並發運行異步操作並正確處理錯誤?同意操作execution 在執行asynchronous操作時,相關的代碼段落會遇到一個問題,當執行asynchronous操作:此實現在啟動下一個操作之前依次等待每個操作的完成。要啟用並發執行,需要進行修改的方法。 第一個解決方案試圖通過獲得每個操作的承諾來解決此問題,然後單獨等待它們: c...程式設計 發佈於2025-04-27
-
PHP SimpleXML解析帶命名空間冒號的XML方法在php 很少,請使用該限制很大,很少有很高。例如:這種技術可確保可以通過遍歷XML樹和使用兒童()方法()方法的XML樹和切換名稱空間來訪問名稱空間內的元素。程式設計 發佈於2025-04-27
-
如何將多種用戶類型(學生,老師和管理員)重定向到Firebase應用中的各自活動?Red: How to Redirect Multiple User Types to Respective ActivitiesUnderstanding the ProblemIn a Firebase-based voting app with three distinct user type...程式設計 發佈於2025-04-27
-
解決MySQL插入Emoji時出現的\\"字符串值錯誤\\"異常Resolving Incorrect String Value Exception When Inserting EmojiWhen attempting to insert a string containing emoji characters into a MySQL database us...程式設計 發佈於2025-04-27
-
我可以將加密從McRypt遷移到OpenSSL,並使用OpenSSL遷移MCRYPT加密數據?將我的加密庫從mcrypt升級到openssl 問題:是否可以將我的加密庫從McRypt升級到OpenSSL?如果是這樣,如何? 答案:是的,可以將您的Encryption庫從McRypt升級到OpenSSL。 可以使用openssl。 附加說明: [openssl_decrypt()函數要求...程式設計 發佈於2025-04-27
-
反射動態實現Go接口用於RPC方法探索在GO 使用反射來實現定義RPC式方法的界面。例如,考慮一個接口,例如:鍵入myService接口{ 登錄(用戶名,密碼字符串)(sessionId int,錯誤錯誤) helloworld(sessionid int)(hi String,錯誤錯誤) } 替代方案而不是依靠反射...程式設計 發佈於2025-04-27
-
`console.log`顯示修改後對象值異常的原因foo = [{id:1},{id:2},{id:3},{id:4},{id:id:5},],]; console.log('foo1',foo,foo.length); foo.splice(2,1); console.log('foo2', foo, foo....程式設計 發佈於2025-04-27
-
Python不會對超範圍子串切片報錯的原因在python中用索引切片範圍:二重性和空序列索引單個元素不同,該元素會引起錯誤,切片在序列的邊界之外沒有。 這種行為源於索引和切片之間的基本差異。索引一個序列,例如“示例” [3],返回一個項目。但是,切片序列(例如“示例” [3:4])返回項目的子序列。 索引不存在的元素時,例如“示例” [9...程式設計 發佈於2025-04-27
-
如何簡化PHP中的JSON解析以獲取多維陣列?php 試圖在PHP中解析JSON數據的JSON可能具有挑戰性,尤其是在處理多維數組時。 To simplify the process, it's recommended to parse the JSON as an array rather than an object.To do...程式設計 發佈於2025-04-27
-
如何將PANDAS DataFrame列轉換為DateTime格式並按日期過濾?Transform Pandas DataFrame Column to DateTime FormatScenario:Data within a Pandas DataFrame often exists in various formats, including strings.使用時間數據時...程式設計 發佈於2025-04-27
-
人臉檢測失敗原因及解決方案:Error -215錯誤處理:解決“ error:( - 215)!empty()in Function openCv in Function MultSiscale中的“檢測”中的錯誤:在功能檢測中。”當Face Cascade分類器(即面部檢測至關重要的組件)未正確加載時,通常會出現此錯誤。 要解決此問題,必...程式設計 發佈於2025-04-27















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









