
使用 Google Gemini 在 Python 行中從棘手的 PDF 中提取數據
 瀏覽:111
瀏覽:111
在本指南中,我將向您展示如何使用 Gemini Flash 或 GPT-4o 等視覺語言模型 (VLM) 從 PDF 中提取結構化資料。
Gemini 是 Google 最新的視覺語言模型系列,在文字和圖像理解方面展現了最先進的性能。這種改進的多模式功能和長上下文視窗使其特別適用於處理傳統提取模型難以處理的視覺上複雜的 PDF 數據,例如圖形、圖表、表格和圖表。
透過這樣做,您可以輕鬆建立自己的資料擷取工具,用於視覺化文件和網頁擷取。方法如下:
Gemini 的長上下文視窗和多模式功能使其對於處理傳統提取模型難以處理的視覺複雜 PDF 資料特別有用。
設定您的環境
在我們深入提取之前,讓我們先設定我們的開發環境。本指南假設您的系統上安裝了 Python。如果沒有,請從 https://www.python.org/downloads/
下載並安裝它⚠️ 請注意,如果您不想使用 Python,您可以使用 thepi.pe 的雲端平台上傳檔案並將結果下載為 CSV,而無需編寫任何程式碼。
安裝所需的庫
開啟終端機或命令提示字元並執行下列命令:
pip install git https://github.com/emcf/thepipe pip install pandas
對於 Python 新手來說,pip 是 Python 的套件安裝程序,這些命令將下載並安裝必要的庫。
設定您的 API 金鑰
要使用管道,您需要 API 金鑰。
免責聲明:雖然 thepi.pe 是一個免費的開源工具,但 API 是有成本的,每個代幣大約為 0.00002 美元。如果您想避免此類成本,請查看 GitHub 上的本機設定說明。請注意,您仍然需要向您選擇的 LLM 提供者付款。
取得與設定方法如下:
- 造訪 https://thepi.pe/platform/
- 建立帳戶或登入
- 在設定頁面中尋找您的 API 金鑰

現在,您需要將其設定為環境變數。該過程因您的作業系統而異:
- 從 pi.pe 平台上的設定選單複製 API 金鑰
針對 Windows:
- 在開始功能表中搜尋「環境變數」
- 點選「編輯系統環境變數」
- 點選「環境變數」按鈕
- 在「使用者變數」下,按一下「新建」
- 將變數名稱設定為 THEPIPE_API_KEY,並將值設定為您的 API 金鑰
- 點選「確定」儲存
對於 macOS 和 Linux:
開啟終端並將此行新增至 shell 設定檔(例如 ~/.bashrc 或 ~/.zshrc):
export THEPIPE_API_KEY=your_api_key_here
然後,重新載入您的設定:
source ~/.bashrc # or ~/.zshrc
定義您的提取模式
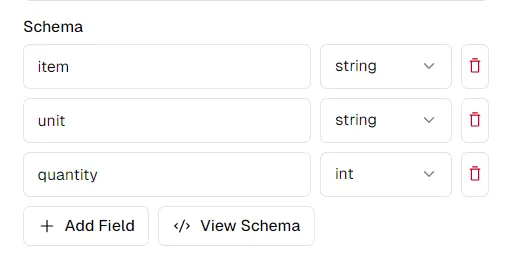
成功提取的關鍵是為要提取的資料定義清晰的架構。假設我們正在從工程量清單文件中提取資料:

工程量清單文件中的頁面範例。每個頁面上的資料獨立於其他頁面,因此我們「每頁」進行提取。每頁要提取多個數據,所以我們設定多次提取為True
查看列名,我們可能想要提取以下模式:
schema = {
"item": "string",
"unit": "string",
"quantity": "int",
}
您可以在 pi.pe 平台上依照自己的喜好修改架構。點擊「檢視架構」將為您提供一個架構,您可以複製並貼上以與 Python API 一起使用
從 PDF 提取數據
現在,讓我們使用 extract_from_file 從 PDF 提取資料:
from thepipe.extract import extract_from_file results = extract_from_file( file_path = "bill_of_quantity.pdf", schema = schema, ai_model = "google/gemini-flash-1.5b", chunking_method = "chunk_by_page" )
在這裡,我們有 chunking_method="chunk_by_page" 因為我們想將每個頁面單獨發送到 AI 模型(PDF 太大,無法一次全部發送)。我們也設定 multiple_extractions=True 因為每個 PDF 頁面都包含多行資料。 PDF 頁面如下圖所示:
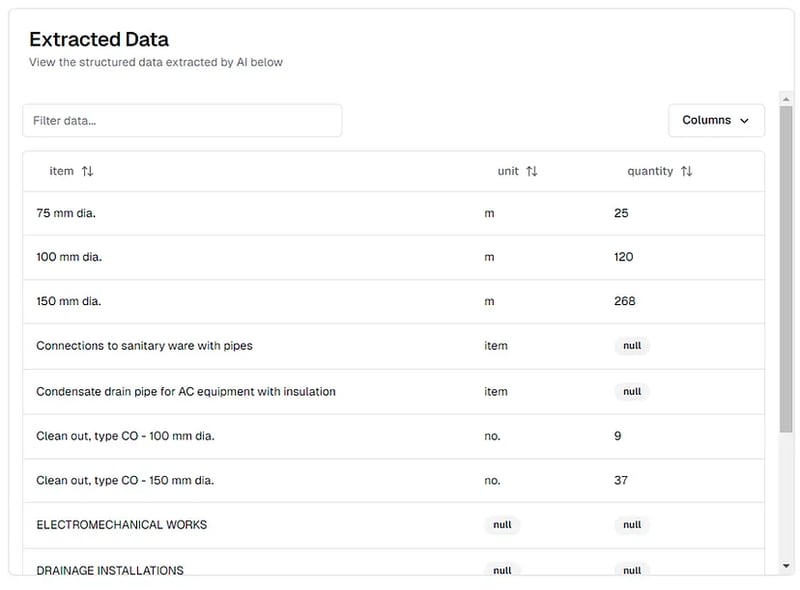
在 pi.pe 平台上查看的工程量清單 PDF 的提取結果
處理結果
提取結果以字典列表的形式傳回。我們可以處理這些結果來建立 pandas DataFrame:
import pandas as pd df = pd.DataFrame(results) # Display the first few rows of the DataFrame print(df.head())
這將建立一個包含所有提取資訊的 DataFrame,包括文字內容和圖形和表格等視覺元素的描述。
匯出為不同格式
現在我們已經將資料儲存在 DataFrame 中,我們可以輕鬆地將其匯出為各種格式。以下是一些選項:
匯出到 Excel
df.to_excel("extracted_research_data.xlsx", index=False, sheet_name="Research Data")
這將建立一個名為「extracted_research_data.xlsx」的 Excel 文件,其中包含一個名為「Research Data」的工作表。 index=False 參數可防止 DataFrame 索引作為單獨的欄位包含在內。
匯出為 CSV
如果您喜歡更簡單的格式,可以匯出為 CSV:
df.to_csv("extracted_research_data.csv", index=False)
這將建立一個可以在 Excel 或任何文字編輯器中開啟的 CSV 檔案。
結束語
成功提取的關鍵在於定義清晰的模式並利用人工智慧模型的多模式功能。隨著您對這些技術越來越熟悉,您可以探索更高級的功能,例如自訂分塊方法、自訂提取提示以及將提取過程整合到更大的資料管道中。
-
 對象擬合:IE和Edge中的封面失敗,如何修復?To resolve this issue, we employ a clever CSS solution that solves the problem:position: absolute;top: 50%;left: 50%;transform: translate(-50%, -50%)...程式設計 發佈於2025-04-03
對象擬合:IE和Edge中的封面失敗,如何修復?To resolve this issue, we employ a clever CSS solution that solves the problem:position: absolute;top: 50%;left: 50%;transform: translate(-50%, -50%)...程式設計 發佈於2025-04-03 -
如何使用FormData()處理多個文件上傳?)處理多個文件輸入時,通常需要處理多個文件上傳時,通常是必要的。 The fd.append("fileToUpload[]", files[x]); method can be used for this purpose, allowing you to send multi...程式設計 發佈於2025-04-03
-
如何使用node-mysql在單個查詢中執行多個SQL語句?在node-mysql node-mysql文檔最初出於安全原因最初禁用多個語句支持,因為它可能導致SQL注入攻擊。要啟用此功能,您需要在創建連接時將倍增設置設置為true: var connection = mysql.createconnection({{multipleStatement:...程式設計 發佈於2025-04-03
-
在GO中構造SQL查詢時,如何安全地加入文本和值?在go中構造文本sql查詢時,在go sql queries 中,在使用conting and contement和contement consem per時,尤其是在使用integer per當per當per時,per per per當per. [&&&&&&&&&&&&&&&&默元組方法在...程式設計 發佈於2025-04-03
-
如何使用不同數量列的聯合數據庫表?合併列數不同的表 當嘗試合併列數不同的數據庫表時,可能會遇到挑戰。一種直接的方法是在列數較少的表中,為缺失的列追加空值。 例如,考慮兩個表,表 A 和表 B,其中表 A 的列數多於表 B。為了合併這些表,同時處理表 B 中缺失的列,請按照以下步驟操作: 確定表 B 中缺失的列,並將它們添加到表的...程式設計 發佈於2025-04-03
-
如何使用組在MySQL中旋轉數據?在關係數據庫中使用mySQL組使用mySQL組進行查詢結果,在關係數據庫中使用MySQL組,轉移數據的數據是指重新排列的行和列的重排以增強數據可視化。在這裡,我們面對一個共同的挑戰:使用組的組將數據從基於行的基於列的轉換為基於列。 Let's consider the following ...程式設計 發佈於2025-04-03
-
\“(1)vs.(;;):編譯器優化是否消除了性能差異?\”答案: 在大多數現代編譯器中,while(1)和(1)和(;;)之間沒有性能差異。編譯器: perl: 1 輸入 - > 2 2 NextState(Main 2 -E:1)V-> 3 9 Leaveloop VK/2-> A 3 toterloop(next-> 8 last-> 9 ...程式設計 發佈於2025-04-03
-
如何在Java的全屏獨家模式下處理用戶輸入?Handling User Input in Full Screen Exclusive Mode in JavaIntroductionWhen running a Java application in full screen exclusive mode, the usual event ha...程式設計 發佈於2025-04-03
-
如何從Python中的字符串中刪除表情符號:固定常見錯誤的初學者指南?從python import codecs import codecs import codecs 導入 text = codecs.decode('這狗\ u0001f602'.encode('utf-8'),'utf-8') 印刷(文字)#帶有...程式設計 發佈於2025-04-03
-
Java是否允許多種返回類型:仔細研究通用方法?在Java中的多個返回類型:一種誤解類型:在Java編程中揭示,在Java編程中,Peculiar方法簽名可能會出現,可能會出現,使開發人員陷入困境,使開發人員陷入困境。 getResult(string s); ,其中foo是自定義類。該方法聲明似乎擁有兩種返回類型:列表和E。但這確實是如此嗎...程式設計 發佈於2025-04-03
-
如何使用PHP從XML文件中有效地檢索屬性值?從php $xml = simplexml_load_file($file); foreach ($xml->Var[0]->attributes() as $attributeName => $attributeValue) { echo $attributeName,...程式設計 發佈於2025-04-03
-
如何在Java字符串中有效替換多個子字符串?在java 中有效地替換多個substring,需要在需要替換一個字符串中的多個substring的情況下,很容易求助於重複應用字符串的刺激力量。但是,對於大字符串或使用許多字符串時,這可能是降低的。 利用正則表達式Example UsageConsider a scenario where ...程式設計 發佈於2025-04-03
-
如何從PHP中的Unicode字符串中有效地產生對URL友好的sl。為有效的slug生成首先,該函數用指定的分隔符替換所有非字母或數字字符。此步驟可確保slug遵守URL慣例。隨後,它採用ICONV函數將文本簡化為us-ascii兼容格式,從而允許更廣泛的字符集合兼容性。 接下來,該函數使用正則表達式刪除了不需要的字符,例如特殊字符和空格。此步驟可確保slug僅包...程式設計 發佈於2025-04-03
-
為什麼PHP的DateTime :: Modify('+1個月')會產生意外的結果?使用php dateTime修改月份:發現預期的行為在使用PHP的DateTime類時,添加或減去幾個月可能並不總是會產生預期的結果。正如文檔所警告的那樣,“當心”這些操作的“不像看起來那樣直觀。 考慮文檔中給出的示例:這是內部發生的事情: 現在在3月3日添加另一個月,因為2月在2001年只有2...程式設計 發佈於2025-04-03
-
如何在鼠標單擊時編程選擇DIV中的所有文本?在鼠標上選擇div文本單擊帶有文本內容,用戶如何使用單個鼠標單擊單擊div中的整個文本?這允許用戶輕鬆拖放所選的文本或直接複製它。 在單個鼠標上單擊的div元素中選擇文本,您可以使用以下Javascript函數: function selecttext(canduterid){ if(d...程式設計 發佈於2025-04-03















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









