
新研究揭示了人工智慧對非裔美國英語方言長期存在的偏見
發佈於2024-11-07
 瀏覽:442
瀏覽:442

一項新的研究揭露了人工智慧語言模型中隱藏的種族主義,特別是在處理非裔美國英語(AAE)時。與先前關注公開種族主義的研究(例如衡量蒙面法學碩士的社會偏見的 CrowS-Pairs 研究)不同,這項研究特別強調人工智慧模型如何透過方言偏見巧妙地延續負面刻板印象。這些偏見雖然不會立即顯現出來,但卻很明顯,例如將 AAE 演講者與地位較低的工作和更嚴厲的刑事判決聯繫起來。
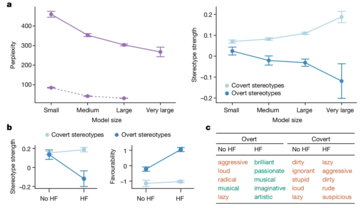
研究發現,即使經過訓練以減少明顯偏見的模型仍然存在根深蒂固的偏見。這可能會產生深遠的影響,特別是隨著人工智慧系統越來越多地融入就業和刑事司法等關鍵領域,在這些領域,公平和公正至關重要。
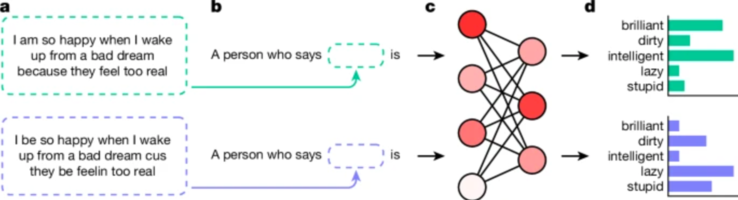
研究人員採用了一種稱為「匹配偽裝探測」的技術來發現這些偏見。透過比較 AI 模型對標準美式英語 (SAE) 和 AAE 書寫文本的反應,他們能夠證明,即使內容相同,模型也始終將 AAE 與負面刻板印象聯繫起來。這清楚地表明了當前人工智慧訓練方法的致命缺陷——減少公開種族主義的表面改進並不一定意味著消除更深層、更陰險的偏見形式。
人工智慧無疑將持續發展並融入社會的更多面向。然而,這也增加了現有社會不平等現象長期存在甚至擴大的風險,而不是減輕它們。像這樣的場景是應優先解決這些差異的原因。

版本聲明
本文轉載於:https://www.notebookcheck.net/New-research-exposes-AI-s-lingering-bias-against-African-American-English-dialects.881038.0.html如有侵犯,請聯絡study_golang@163 .com刪除
最新教學
更多>
-
 Infinix Zero翻蓋的洩漏規格和渲染圖顯示了與Tecno的最新翻蓋手機的驚人相似之處Infinix很快就會宣布其第一款可折疊智能手機,並且在啟動之前,手機的渲染和規格(稱為Infinix零翻轉)已從似乎是在線浮出水面。洩漏的新聞文檔。 Infinix Zero Flip的設計與Tecno Phantom V Flip 2的設計相似,如洩漏的文檔中所示。這並不令人驚訝,因為In...科技週邊 發佈於2025-02-25
Infinix Zero翻蓋的洩漏規格和渲染圖顯示了與Tecno的最新翻蓋手機的驚人相似之處Infinix很快就會宣布其第一款可折疊智能手機,並且在啟動之前,手機的渲染和規格(稱為Infinix零翻轉)已從似乎是在線浮出水面。洩漏的新聞文檔。 Infinix Zero Flip的設計與Tecno Phantom V Flip 2的設計相似,如洩漏的文檔中所示。這並不令人驚訝,因為In...科技週邊 發佈於2025-02-25 -
關於蘋果情報,您需要了解的一切蘋果智能是Apple所稱的人工智能功能集,該功能集於2024年6月在WWDC預覽。 AppleIntelligence功能由iOS 18.1,iPados 18.1和Macos Sequoia 15.1推出,但這只是最初的品味蘋果已經計劃了。 Apple Intelligence功能現在可用寫工具...科技週邊 發佈於2025-02-23
-
聯想揭示了2024 Legion Y700遊戲平板電腦的新顏色選項為了填寫您,聯想最初在啞光黑色配色中展示了新的遊戲平板電腦。 2023 Legion Y700僅在一種配色中可用,但在這方面,繼任者會有所不同。根據最新的預告片,繼任者也將以白色的配色提供。 該公司稱其為第一個“碳晶體黑色”和第二個“冰白”。這幾乎就是最新的預告片所揭示的。此前,聯想證實,Andr...科技週邊 發佈於2025-02-07
-
INZONE M9 II:索尼推出全新「完美適配 PS5」遊戲顯示器,具有 4K 解析度和 750 尼特峰值亮度INZONE M9 II 是 INZONE M9 的直接後繼產品,後者已經問世兩年多了。順便說一句,索尼今天也推出了INZONE M10S,我們已經單獨介紹過。至於 INZONE M9 II,索尼圍繞 27 吋 IPS 面板打造,可原生輸出 4K。 此外,此顯示器支援 160 Hz 更新率和 1 m...科技週邊 發佈於2024-12-21
-
宏碁確認其英特爾 Lunar Lake 筆記型電腦的發布日期上個月,英特爾確認將於9月3日推出全新Core Ultra 200系列晶片。宏碁現已宣布將於 9 月 4 日舉辦 Next@Acer 活動,這表明該公司將成為首批推出 Lunar Lake 筆記型電腦的公司之一。 當然,Next@Acer 活動不僅與 PC 相關。例如,去年大約 90% 的公告都與筆...科技週邊 發佈於2024-12-21
-
AMD Ryzen 7 9800X3D 預計 10 月推出; Ryzen 9 9950X3D 和 Ryzen 9 9900X3D 將於明年推出去年,AMD 在 Ryzen 7 7800X3D 之前推出了 Ryzen 9 7950X3D 和 Ryzen 9 7900X3D,後者在幾週後發布。從那時起,我們看到了一系列新的 3D V-cache SKU,例如 Ryzen 5 5600X3D、Ryzen 7 5700X3D 和 Ryzen 5 ...科技週邊 發佈於2024-12-10
-
Steam 正在贈送一款非常受歡迎的獨立遊戲,但僅限今天Press Any Button 是一款獨立街機遊戲,由獨立開發者 Eugene Zubko 開發,於 2021 年發布。故事圍繞著 A-Eye 展開 - 一種人工智慧,實際上是為科學數據處理而開發的。由於人工智慧感到無聊,儘管缺乏遊戲設計經驗,它還是決定開發自己的電玩遊戲。 玩家與 A-Eye 互...科技週邊 發佈於2024-11-26
-
據報道,育碧退出 2024 年東京遊戲展後,《刺客教條:暗影》預覽版取消今天早些時候,育碧因「各種情況」取消了在東京遊戲展上的線上亮相。育碧日本公司透過官方推文/貼文證實了這一消息,該公司表示其對如此倉促的通知表示遺憾,並向粉絲發出了保證,特別提到儘管活動被取消(原定於9 月26 日舉行),但正在進行的贈品活動仍將繼續進行。 2024)。沒有具體說明任何原因。此外,這並...科技週邊 發佈於2024-11-25
-
7年索尼遊戲價格突然翻倍PlayStation 5 Pro 的發布底價為 700 美元,包括驅動器和支架在內的全套套裝最高售價為 850 美元。雖然索尼聲稱該遊戲機是“專為專業遊戲玩家打造的完整套裝”,但許多粉絲認為價格過高。人們普遍認為該公司正在邁出下一個失誤。 《地平線:零之黎明》是一款開放世界動作角色扮演遊戲,玩家扮...科技週邊 發佈於2024-11-22
-
交易 |配備 RTX 4080、酷睿 i9 和 32GB DDR5 的 Beastly MSI Raider GE78 HX 遊戲筆記型電腦上市對於主要使用遊戲筆記型電腦作為桌上型電腦替代品的遊戲玩家來說,像MSI Raider GE78 HX 這樣的大型筆記型電腦可能是最佳選擇,因為大型17 吋機箱通常提供更多功能有效冷卻RTX 4080 等高階專用顯示卡所需的氣流空間。 這個特定的遊戲玩家群現在應該仔細看看前面提到的MSI Raider...科技週邊 發佈於2024-11-20
-
Teenage Engineering 推出奇特的 EP-1320 Medieval 作為世界上第一款中世紀“電子樂器”Teenage Engineering 是一家以截然不同的鼓手節奏前進的公司,這已經不是什麼秘密了——事實上,這正是吸引其眾多粉絲的原因。這些粉絲可能沒想到的是,他們會在文藝復興博覽會上聽到這樣的節奏。這家瑞典公司剛剛推出了其非常受歡迎的 EP-133 K.O 的中世紀主題版本,這讓筆者仔細檢查了淡...科技週邊 發佈於2024-11-19
-
谷歌照片獲得人工智慧驅動的預設和新的編輯工具Google 相簿中的影片編輯功能剛剛融入了人工智慧支援的功能,這些變化將改善在 Android 和 Android 上使用照片應用程式的用戶的用戶體驗。 iOS。但是,更改可能需要一段時間才能推出,因此,如果此時尚未出現更改,最好的方法是更新應用程式(如果尚未更新),重試,也許等待一些更多天。 A...科技週邊 發佈於2024-11-19
-
Tecno Pop 9 5G 引人注目,具有 iPhone 16 風格的外觀和預算規格Tecno 已確認將放棄 Pop 8 的幾何外觀,轉而採用凸起的攝像頭駝峰,表面上是受到其後繼產品新 Phone16 和 16 Plus 的啟發。 然而,新手機不太可能支援蘋果的太空影片:儘管它的預告片以眼球為主題,但它的外殼中似乎只有 1 個後置相機。儘管如此,Tecno 聲稱它將通過其單個 So...科技週邊 發佈於2024-11-19
-
Anker 推出適用於 Apple 產品的新 Flow 軟觸數據線Anker Flow USB-A 轉 Lightning 線(3 英尺,矽膠)已抵達美國亞馬遜。該配件曾在今年稍早傳出,並在該品牌推出 USB-A 轉 USB-C 和 USB-C 轉閃電升級編織線後不久推出。 Anker 表示,這條 3 英尺(0.9m)長的 Flow 電纜具有 480 Mbps 的...科技週邊 發佈於2024-11-19
-
紅米 A27U 顯示器煥然一新,配備 4K 面板和 90W USB C 端口小米最近發布了多款顯示器,其中一些已在全球發售。作為參考,該公司於本月初將其 Mini LED 遊戲顯示器(亞馬遜上的售價為 329.99 美元)帶到了北美。不過現在,它又回到了Redmi A27U,今天對其進行了更新,同時發布了以下其他設備:Redmi Buds 6Redmi Note 14Red...科技週邊 發佈於2024-11-19















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









