
評估機器學習分類模型
 瀏覽:694
瀏覽:694
大纲
- 模型评估的目标是什么?
- 模型评估的目的是什么,有哪些 常见的评估程序?
- 分类准确率有什么用,它的作用是什么 限制?
- 混淆矩阵如何描述一个 分类器?
- 可以从混淆矩阵计算哪些指标?
T模型评估的目标是回答问题;
不同型号如何选择?
评估机器学习的过程有助于确定模型的应用可靠性和有效性。这涉及评估不同的因素,例如其性能、指标以及预测或决策的准确性。
无论您选择使用什么模型,您都需要一种在模型之间进行选择的方法:不同的模型类型、调整参数和功能。此外,您还需要模型评估程序来估计模型对未见过的数据的泛化能力。最后,您需要一个评估程序来与其他程序配合以量化您的模型性能。
在我们继续之前,让我们回顾一下一些不同的模型评估程序及其运作方式。
模型评估程序及其运作方式。
-
对相同数据进行训练和测试
- 奖励过于复杂的模型,这些模型“过度拟合”训练数据并且不一定具有泛化能力
-
训练/测试分割
- 将数据集分成两部分,以便模型可以在不同的数据上进行训练和测试
- 更好地估计样本外表现,但仍然是“高方差”估计
- 因其速度、简单性和灵活性而有用
-
K 折交叉验证
- 系统地创建“K”个训练/测试分组并将结果平均在一起
- 更好地估计样本外表现
- 运行速度比训练/测试拆分慢“K”倍。
从上面我们可以推断出:
对相同数据进行训练和测试是过度拟合的一个典型原因,在这种情况下,您构建的模型过于复杂,无法泛化到新数据,而且实际上没有用。
Train_Test_Split 可以更好地估计样本外性能。
通过系统地进行 K 次训练测试分割并将结果平均在一起,K 折交叉验证效果更好。
总而言之,train_tests_split 由于其速度和简单性,对于交叉验证来说仍然是有利可图的,这就是我们将在本教程中使用的内容。
模型评估指标:
您始终需要一个评估指标来配合您选择的程序,并且您对指标的选择取决于您要解决的问题。对于分类问题,可以使用分类精度。但我们将在本指南中重点关注其他重要的分类评估指标。
在我们学习任何新的评估指标之前'让我们回顾一下分类准确性,并讨论它的优点和缺点。
分类准确率
我们为本教程选择了 Pima Indians Diabetes 数据集,其中包括 768 名患者的健康数据和糖尿病状况。
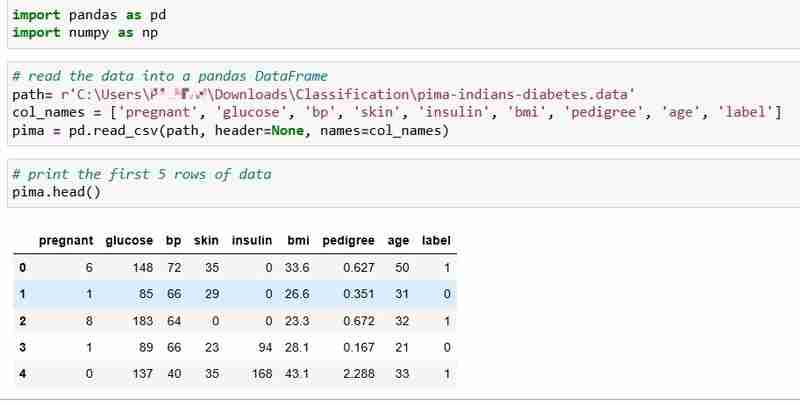
让我们读取数据并打印前5行数据。如果患者患有糖尿病,则标签列表示为 1,如果患者没有患有糖尿病,则标签列表示为 0,我们要回答的问题是:
问题: 我们可以根据患者的健康测量结果预测其糖尿病状况吗?
我们定义特征度量 X 和响应向量 Y。我们使用 train_test_split 将 X 和 Y 分成训练集和测试集。
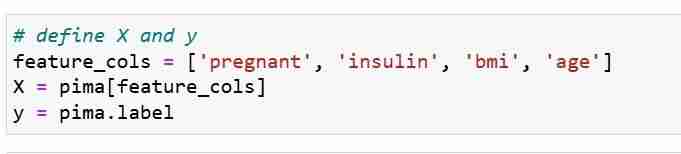
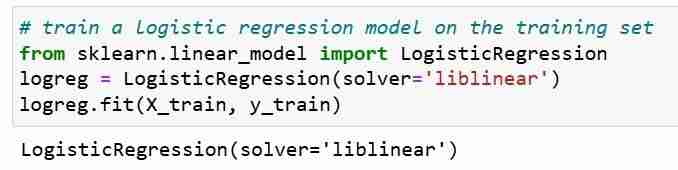
接下来,我们在训练集上训练逻辑回归模型。在拟合步骤中,logreg 模型对象正在学习 X_train 和 Y_train 之间的关系。最后我们对测试集进行类别预测。

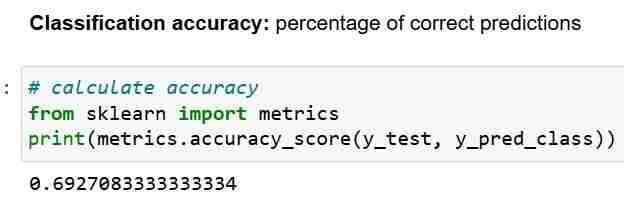
现在,我们已经对测试集进行了预测,我们可以计算分类准确率,简单来说就是正确预测的百分比。
但是,每当您使用分类准确性作为评估指标时,将其与空准确性进行比较非常重要,后者是通过始终预测最频繁的类别可以获得的准确性。

空准确率回答了问题;如果我的模型能够 100% 地预测主要类别,那么它正确的概率是多少?在上面的场景中,y_test 的 32% 为 1(个)。换句话说,预测患者患有糖尿病的愚蠢模型的正确率是 68%(即零)。这提供了一个基线,我们可能希望根据该基线来衡量逻辑回归模型。
当我们比较 68% 的 Null 准确率和 69% 的模型准确率时,我们的模型看起来不太好。这表明分类准确性作为模型评估指标的一个弱点。分类准确性并不能告诉我们有关测试测试的基本分布的任何信息。
总之:
- 分类准确率是最容易理解的分类指标
- 但是,它不会告诉您响应值的潜在分布
- 并且,它不会告诉您分类器正在产生什么“类型”错误。
现在让我们看看混淆矩阵。
混淆矩阵
混淆矩阵是描述分类模型性能的表格。
它有助于帮助您了解分类器的性能,但它不是模型评估指标;所以你不能告诉 scikit learn 选择具有最佳混淆矩阵的模型。然而,有很多指标可以从混淆矩阵中计算出来,并且可以直接用于在模型之间进行选择。
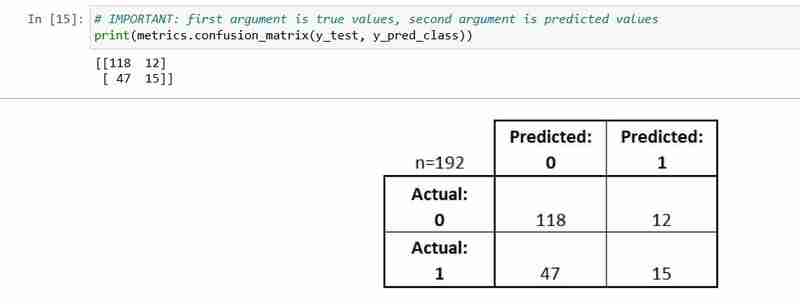
- 测试集中的每个观察结果都在恰好一个框中表示
- 这是一个 2x2 矩阵,因为有 2 个响应类别
- 此处显示的格式不是通用
让我们解释一下它的一些基本术语。
- 真阳性(TP):我们正确预测他们确实患有糖尿病
- 真阴性(TN):我们正确预测他们没有患有糖尿病
- 误报 (FP):我们错误地预测他们确实患有糖尿病(“I 型错误”)
- 假阴性(FN):我们错误地预测他们没有患有糖尿病(“II型错误”)
让我们看看如何计算指标
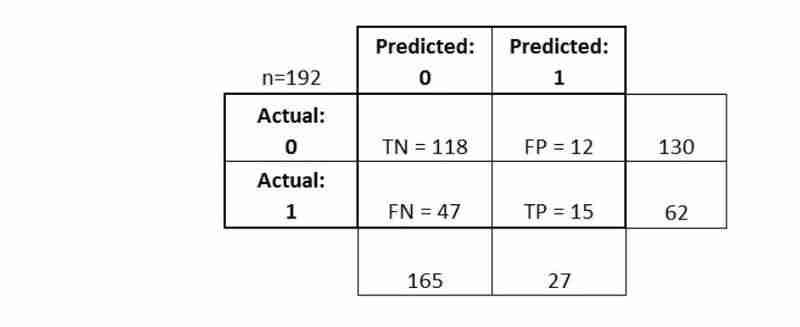


综上所述:
- 混淆矩阵为您提供更完整的图片您的分类器的执行情况
- 还允许您计算各种分类指标,这些指标可以指导您的模型选择
-
 如何使用Java.net.urlConnection和Multipart/form-data編碼使用其他參數上傳文件?使用http request 上傳文件上傳到http server,同時也提交其他參數,java.net.net.urlconnection and Multipart/form-data Encoding是普遍的。 Here's a breakdown of the process:Mu...程式設計 發佈於2025-04-12
如何使用Java.net.urlConnection和Multipart/form-data編碼使用其他參數上傳文件?使用http request 上傳文件上傳到http server,同時也提交其他參數,java.net.net.urlconnection and Multipart/form-data Encoding是普遍的。 Here's a breakdown of the process:Mu...程式設計 發佈於2025-04-12 -
如何在Java字符串中有效替換多個子字符串?在java 中有效地替換多個substring,需要在需要替換一個字符串中的多個substring的情況下,很容易求助於重複應用字符串的刺激力量。 However, this can be inefficient for large strings or when working with nu...程式設計 發佈於2025-04-12
-
如何在JavaScript對像中動態設置鍵?在嘗試為JavaScript對象創建動態鍵時,如何使用此Syntax jsObj['key' i] = 'example' 1;不工作。正確的方法採用方括號: jsobj ['key''i] ='example'1; 在JavaScript中,數組是一...程式設計 發佈於2025-04-12
-
Yii框架快速搭建CRUD應用,PHP高手必備Yii框架:快速构建高效CRUD应用的指南 Yii是一个高性能的PHP框架,以其速度、安全性以及对Web 2.0应用的良好支持而闻名。它遵循“约定优于配置”的原则,这意味着只要遵循其规范,就能编写比其他框架少得多的代码(更少的代码意味着更少的bug)。此外,Yii还提供了许多开箱即用的便捷功能,例如...程式設計 發佈於2025-04-12
-
如何有效地轉換PHP中的時區?在PHP 利用dateTime對象和functions DateTime對象及其相應的功能別名為時區轉換提供方便的方法。例如: //定義用戶的時區 date_default_timezone_set('歐洲/倫敦'); //創建DateTime對象 $ dateTime = ne...程式設計 發佈於2025-04-12
-
如何使用PHP將斑點(圖像)正確插入MySQL?essue VALUES('$this->image_id','file_get_contents($tmp_image)')";This code builds a string in PHP, but the function call fil...程式設計 發佈於2025-04-12
-
為什麼我的CSS背景圖像出現?故障排除:CSS背景圖像未出現 ,您的背景圖像儘管遵循教程說明,但您的背景圖像仍未加載。圖像和样式表位於相同的目錄中,但背景仍然是空白的白色帆布。 而不是不棄用的,您已經使用了CSS樣式: bockent {背景:封閉圖像文件名:背景圖:url(nickcage.jpg); 如果您的html,cs...程式設計 發佈於2025-04-12
-
如何為PostgreSQL中的每個唯一標識符有效地檢索最後一行?postgresql:為每個唯一標識符提取最後一行,在Postgresql中,您可能需要遇到與在數據庫中的每個不同標識相關的信息中提取信息的情況。考慮以下數據:[ 1 2014-02-01 kjkj 在數據集中的每個唯一ID中檢索最後一行的信息,您可以在操作員上使用Postgres的有效效率: ...程式設計 發佈於2025-04-12
-
如何使用組在MySQL中旋轉數據?在關係數據庫中使用mySQL組使用mySQL組進行查詢結果,在關係數據庫中使用MySQL組,轉移數據的數據是指重新排列的行和列的重排以增強數據可視化。在這裡,我們面對一個共同的挑戰:使用組的組將數據從基於行的基於列的轉換為基於列。 Let's consider the following ...程式設計 發佈於2025-04-12
-
如何使用替換指令在GO MOD中解析模塊路徑差異?在使用GO MOD時,在GO MOD 中克服模塊路徑差異時,可能會遇到衝突,其中可能會遇到一個衝突,其中3派對軟件包將另一個帶有導入套件的path package the Imptioned package the Imptioned package the Imported tocted pac...程式設計 發佈於2025-04-12
-
Properties.Settings.Default應用設置存儲位置揭秘[2 理解properties.settings.default存儲位置 c#'s properties.settings.default 對像簡化了定義,訪問和保存應用程序設置的過程。 知道存儲位置對於手動配置調整和調試等任務至關重要。 這些存儲在特定於用戶的應用程序設置文件夾中...程式設計 發佈於2025-04-12
-
如何使用不同數量列的聯合數據庫表?合併列數不同的表 當嘗試合併列數不同的數據庫表時,可能會遇到挑戰。一種直接的方法是在列數較少的表中,為缺失的列追加空值。 例如,考慮兩個表,表 A 和表 B,其中表 A 的列數多於表 B。為了合併這些表,同時處理表 B 中缺失的列,請按照以下步驟操作: 確定表 B 中缺失的列,並將它們添加到表的...程式設計 發佈於2025-04-12
-
可以在純CS中將多個粘性元素彼此堆疊在一起嗎?[2这里: https://webthemez.com/demo/sticky-multi-header-scroll/index.html </main> <section> { display:grid; grid-template-...程式設計 發佈於2025-04-12
-
如何將MySQL數據庫添加到Visual Studio 2012中的數據源對話框中?在Visual Studio 2012 儘管已安裝了MySQL Connector v.6.5.4,但無法將MySQL數據庫添加到實體框架的“ DataSource對話框”中。為了解決這一問題,至關重要的是要了解MySQL連接器v.6.5.5及以後的6.6.x版本將提供MySQL的官方Visual...程式設計 發佈於2025-04-12
-
如何在Java的全屏獨家模式下處理用戶輸入?Handling User Input in Full Screen Exclusive Mode in JavaIntroductionWhen running a Java application in full screen exclusive mode, the usual event ha...程式設計 發佈於2025-04-12















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









