
ETL:從文字中提取人名
發佈於2024-11-07
 瀏覽:397
瀏覽:397
假設我們想要抓取chicagomusiccompass.com。
如你所見,它有幾張卡片,每張卡片代表一個事件。現在,讓我們來看看下一篇:
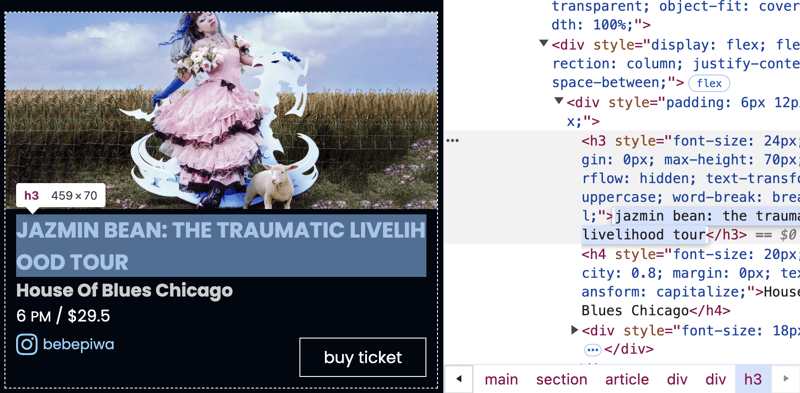
注意事件名稱是:
jazmin bean: the traumatic livelihood tour
所以現在的問題是:我們要如何從文本中提取藝術家的名字?
作為一個人,我可以「輕鬆地」看出 jazmin bean 是藝術家——只需查看他們的 wiki 頁面即可。但是編寫程式碼來提取該名稱可能會很棘手。
我們可以想,“嘿,: 之前的任何內容都應該是藝術家的名字”,這看起來很聰明,對吧?它適用於這種情況,但是這個怎麼樣:
happy hour on the patio: kathryn & chris
這裡,順序顛倒了。我們可以不斷添加邏輯來處理不同的情況,但很快我們就會得到大量脆弱的規則,並且可能無法涵蓋所有內容。
這就是命名實體識別(NER)模型派上用場的地方。它們是開源的,可以幫助我們從文字中提取名稱。它不會捕獲所有案例,但大多數時候,他們會給我們所需的資訊。
透過這種方法,提取變得更加容易。我選擇 Python 是因為 Python 機器學習社群是無與倫比的。
from gliner import GLiNER
model = GLiNER.from_pretrained("urchade/gliner_base")
text = "jazmin bean: the traumatic livelihood tour"
labels = ["person", "bands", "projects"]
entities = model.predict_entities(text, labels)
for entity in entities:
print(entity["text"], "=>", entity["label"])
產生輸出:
jazmin bean => person
現在,讓我們來看看另一種情況:
happy hour on the patio: kathryn & chris
輸出:
kathryn => person chris => person
來源-GLiNER
太棒了,對吧?不再需要繁瑣的邏輯來提取名稱,只需使用模型即可。當然,它不會涵蓋所有可能的情況,但對於我的專案來說,這種靈活性就很好了。如果您需要更高的準確性,您可以隨時:
- 嘗試不同的模型
- 對現有模型做出貢獻
- 分叉項目並調整它以滿足您的需求
結論
身為軟體開發人員,強烈建議隨時更新機器學習領域的工具。並非所有問題都可以透過簡單的程式設計和邏輯來解決 - 使用模型和統計數據可以更好地解決一些挑戰。
版本聲明
本文轉載於:https://dev.to/garciadiazjaime/etl-extracting-a-persons-name-from-text-ahl?1如有侵犯,請聯絡[email protected]刪除
最新教學
更多>
-
 如何在Java字符串中有效替換多個子字符串?在java 中有效地替換多個substring,需要在需要替換一個字符串中的多個substring的情況下,很容易求助於重複應用字符串的刺激力量。 However, this can be inefficient for large strings or when working with nu...程式設計 發佈於2025-03-12
如何在Java字符串中有效替換多個子字符串?在java 中有效地替換多個substring,需要在需要替換一個字符串中的多個substring的情況下,很容易求助於重複應用字符串的刺激力量。 However, this can be inefficient for large strings or when working with nu...程式設計 發佈於2025-03-12 -
為什麼使用Firefox後退按鈕時JavaScript執行停止?導航歷史記錄問題:JavaScript使用Firefox Back Back 此行為是由瀏覽器緩存JavaScript資源引起的。要解決此問題並確保在後續頁面訪問中執行腳本,Firefox用戶應設置一個空功能。 警報'); }; alert('inline Alert')...程式設計 發佈於2025-03-12
-
-
如何使用PHP從XML文件中有效地檢索屬性值?從php $xml = simplexml_load_file($file); foreach ($xml->Var[0]->attributes() as $attributeName => $attributeValue) { echo $attributeName,...程式設計 發佈於2025-03-12
-
如何從Google API中檢索最新的jQuery庫?從Google APIS 問題中提供的jQuery URL是版本1.2.6。對於檢索最新版本,以前有一種使用特定版本編號的替代方法,它是使用以下語法:獲取最新版本:未壓縮)While these legacy URLs still remain in use, it is recommended ...程式設計 發佈於2025-03-12
-
Extending OctoberCMS:打造軟刪除插件教程OctoberCMS:插件扩展性深度探索及软删除插件实战 开发者通常青睐易用且可扩展的CMS。OctoberCMS 秉持简洁至上的理念,为开发者和用户带来愉悦的体验。本文将演示OctoberCMS 的一些可扩展特性,并通过一个简单的插件扩展另一个插件的功能。 关键要点 OctoberCMS 提供了...程式設計 發佈於2025-03-12
-
如何在JavaScript對像中動態設置鍵?在嘗試為JavaScript對象創建動態鍵時,如何使用此Syntax jsObj['key' i] = 'example' 1;不工作。正確的方法採用方括號: jsobj ['key''i] ='example'1; 在JavaScript中,數組是一...程式設計 發佈於2025-03-12
-
如何在PHP中使用連字符訪問XML元素?在PHP中使用連字符訪問XML元素,在PHP中,從XML文檔中提取數據時,在XML文檔中提取數據時,與連字符遇到Node名稱可能會導致錯誤。 Attempting to access such elements using the dot notation (e.g., $xml->custom-...程式設計 發佈於2025-03-12
-
如何修改python 3中sys.stdout的編碼?在Python 3中編碼輸出:在Python 2中設置SYS.STDOUT的編碼 sys.stdout.reconfigure(encoding ='utf-8'')此方法有效地將編碼更改為UTF-8。 Moreover, you can refine the handli...程式設計 發佈於2025-03-12
-
哪種方法更有效地用於點 - 填點檢測:射線跟踪或matplotlib \的路徑contains_points?在Python Matplotlib's path.contains_points FunctionMatplotlib's path.contains_points function employs a path object to represent the polygon.它...程式設計 發佈於2025-03-12
-
如何限制動態大小的父元素中元素的滾動範圍?在交互式接口中實現垂直滾動元素的CSS高度限制問題:考慮一個佈局,其中我們具有與用戶垂直滾動一起移動的可滾動地圖div,同時與固定的固定sidebar保持一致。但是,地圖的滾動無限期擴展,超過了視口的高度,阻止用戶訪問頁面頁腳。 $("#map").css({ margin...程式設計 發佈於2025-03-12
-
為什麼我會收到MySQL錯誤#1089:錯誤的前綴密鑰?mySQL錯誤#1089:錯誤的前綴鍵錯誤descript [#1089-不正確的前綴鍵在嘗試在表中創建一個prefix鍵時會出現。前綴鍵旨在索引字符串列的特定前綴長度長度,可以更快地搜索這些前綴。 了解prefix keys `這將在整個Movie_ID列上創建標準主鍵。主密鑰對於唯一識...程式設計 發佈於2025-03-12
-
我可以將加密從McRypt遷移到OpenSSL,並使用OpenSSL遷移MCRYPT加密數據?將我的加密庫從mcrypt升級到openssl 問題:是否可以將我的加密庫從McRypt升級到OpenSSL?如果是這樣,如何? 答案:是的,可以將您的Encryption庫從McRypt升級到OpenSSL。 可以使用openssl。 附加說明: [openssl_decrypt()函數要求...程式設計 發佈於2025-03-12
-
如何從PHP中的數組中提取隨機元素?從陣列中的隨機選擇,可以輕鬆從數組中獲取隨機項目。考慮以下數組:; 從此數組中檢索一個隨機項目,利用array_rand( array_rand()函數從數組返回一個隨機鍵。通過將$項目數組索引使用此鍵,我們可以從數組中訪問一個隨機元素。這種方法為選擇隨機項目提供了一種直接且可靠的方法。程式設計 發佈於2025-03-12















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









