
透過靜態分析、映像初始化和堆疊快照提高效能
 瀏覽:772
瀏覽:772
从整体结构到分布式系统世界,应用程序开发已经走过了漫长的道路。云计算和微服务架构的大规模采用极大地改变了服务器应用程序的创建和部署方式。我们现在拥有独立、单独部署的服务,而不是巨大的应用程序服务器
当需要时。
然而,可能影响这种平稳运行的新玩家可能是“冷启动”。当第一个请求在新产生的工作进程上处理时,冷启动就会启动。这种情况需要在处理实际请求之前进行语言运行时初始化和服务配置初始化。与冷启动相关的不可预测性和执行速度较慢可能会违反云服务的服务级别协议。那么,如何应对这种日益增长的担忧呢?
本机映像:优化启动时间和内存占用
为了解决冷启动的低效率问题,我们开发了一种新颖的方法,涉及点分析、构建时的应用程序初始化、堆快照和提前(AOT)编译。此方法在封闭世界假设下运行,要求所有 Java 类在构建时都已预先确定并可访问。在此阶段,全面的点分析确定所有可访问的程序元素(类、方法、字段),以确保仅编译必要的 Java 方法。
应用程序的初始化代码可以在构建过程中执行,而不是在运行时执行。这允许预先分配 Java 对象并构建复杂的数据结构,然后在运行时通过“映像堆”提供这些数据结构。该映像堆集成在可执行文件中,在应用程序启动时提供立即可用性。这
持续迭代执行点分析和快照,直到达到稳定状态(定点),从而优化启动时间和资源消耗。
详细工作流程
我们系统的输入是 Java 字节码,它可能源自 Java、Scala 或 Kotlin 等语言。该过程统一处理应用程序、其库、JDK 和 VM 组件,以生成特定于操作系统和体系结构的本机可执行文件 - 称为“本机映像”。构建过程包括迭代点分析和堆快照,直到达到固定点,从而允许应用程序通过注册的回调主动参与。这些步骤统称为本机映像构建过程 (图 1)
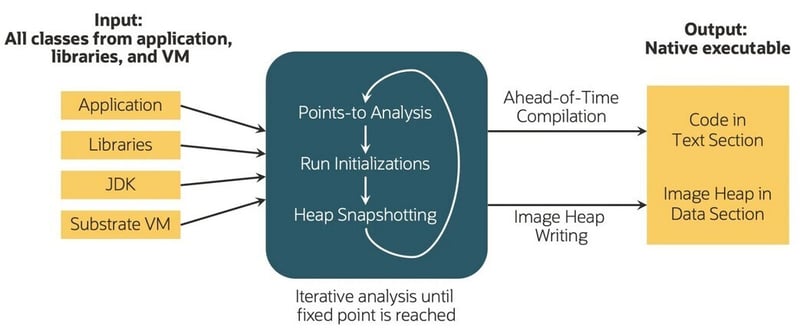
图 1 – 本机映像构建过程(来源:redhat.com)
点分析
我们采用点分析来确定运行时类、方法和字段的可达性。点到分析从所有入口点(例如应用程序的主要方法)开始,迭代遍历所有可传递可达的方法,直到到达固定点(图2)。
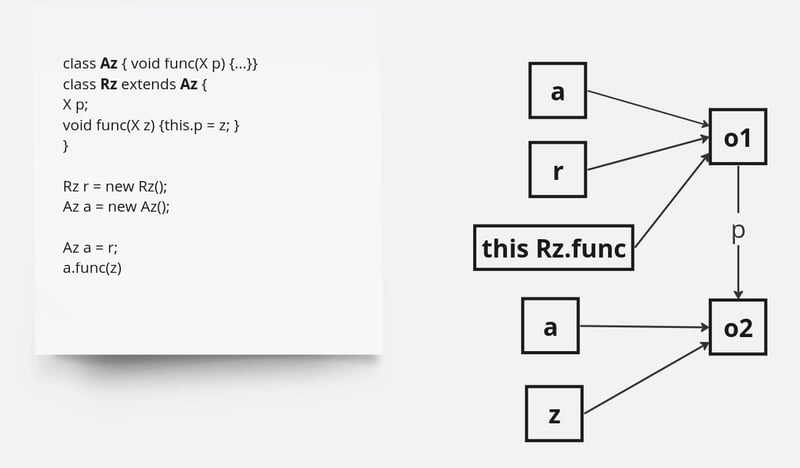
图 2 – 分析点
我们的指向分析利用编译器的前端将 Java 字节码解析为编译器的高级中间表示(IR)。随后,IR 被转换为类型流图。在此图中,节点表示对对象类型进行操作的指令,而边表示节点之间的定向使用边,从定义指向使用。每个节点维护一个类型状态,由可以到达该节点的类型列表和空值信息组成。类型状态通过使用边传播;如果节点的类型状态发生变化,则此更改将传播到所有用途。重要的是,类型状态只能扩展;新类型可以添加到类型状态,但现有类型永远不会被删除。该机制确保
分析最终收敛到一个固定点,导致终止。
运行初始化代码
指向分析在到达局部固定点时指导初始化代码的执行。该代码起源于两个不同的来源:类初始值设定项和在构建时通过功能接口批量执行的自定义代码:
类初始值设定项: 每个 Java 类都可以有一个由
方法指示的类初始值设定项,该方法初始化静态字段。开发人员可以选择在构建时和运行时初始化哪些类。 显式回调:开发者可以通过我们系统提供的钩子实现自定义代码,在分析阶段之前、期间或之后执行。
这里提供了用于与我们的系统集成的API。
被动API(查询当前分析状态)
boolean isReachable(Class> clazz); boolean isReachable(Field field); boolean isReachable(Executable method);
更多信息,请参阅QueryReachabilityAccess
Active API(注册分析状态更改的回调):
void registerReachabilityHandler(Consumercallback, Object... elements); void registerSubtypeReachabilityHandler(BiConsumer > callback, Class> baseClass); void registerMethodOverrideReachabilityHandler(BiConsumer callback, Executable baseMethod);
更多信息,请参阅BeforeAnalysisAccess
在此阶段,应用程序可以执行自定义代码,例如对象分配和较大数据结构的初始化。重要的是,初始化代码可以访问当前的分析状态点,从而启用有关类型、方法或字段的可达性的查询。这是使用DuringAnalysisAccess 提供的各种isReachable() 方法来完成的。利用此信息,应用程序可以构建针对应用程序的可到达段优化的数据结构。
堆快照
最后,堆快照通过像静态字段一样跟随根指针构建对象图,以构建所有可访问对象的全面视图。然后该图填充本机图像的
图像堆,确保应用程序的初始状态在启动时有效加载。
为了生成可达对象的传递闭包,该算法遍历对象字段,使用反射读取它们的值。值得注意的是,映像生成器在 Java 环境中运行。在此遍历期间,仅考虑由指向分析标记为“已读”的实例字段。例如,如果一个类有两个实例字段,但其中一个未标记为已读,则通过未标记字段可访问的对象将从图像堆中排除。
当遇到先前未通过指向分析识别其类的字段值时,该类将被注册为字段类型。此注册确保在点分析的后续迭代中,新类型传播到类型流图中的所有字段读取和传递用法。
下面的代码片段概述了堆快照的核心算法:
Declare List worklist := []
Declare Set reachableObjects := []
Function BuildHeapSnapshot(PointsToState pointsToState)
For Each field in pointsToState.getReachableStaticObjectFields()
Call AddObjectToWorkList(field.readValue())
End For
For Each method in pointsToState.getReachableMethods()
For Each constant in method.embeddedConstants()
Call AddObjectToWorkList(constant)
End For
End For
While worklist.isNotEmpty
Object current := Pop from worklist
If current Object is an Array
For Each value in current
Call AddObjectToWorkList(value)
Add current.getClass() to pointsToState.getObjectArrayTypes()
End For
Else
For Each field in pointsToState.getReachableInstanceObjectFields(current.getClass())
Object value := field.read(current)
Call AddObjectToWorkList(value)
Add value.getClass() to pointsToState.getFieldValueTypes(field)
End For
End If
End While
Return reachableObjects
End Function
综上所述,堆快照算法通过系统地遍历可达对象及其字段来高效地构造堆快照。这可确保仅相关对象包含在图像堆中,从而优化本机图像的性能和内存占用。
结论
总而言之,堆快照过程在本机映像的创建中起着至关重要的作用。通过系统地遍历可达对象及其字段,堆快照算法构建了一个对象图,该对象图表示可达对象从根指针(例如静态字段)的传递闭包。然后将该对象图作为图像堆嵌入到本机映像中,充当本机映像启动时的初始堆。
在整个过程中,算法依赖于分析点的状态来确定哪些对象和字段与包含在图像堆中相关。考虑由点分析标记为“已读”的对象和字段,而排除未标记的实体。此外,当遇到以前未见过的类型时,算法会将它们注册以便在点分析的后续迭代中传播。
总体而言,堆快照通过确保映像堆中仅包含必要的对象来优化本机映像的性能和内存使用情况。这种系统方法提高了本机图像执行的效率和可靠性。
-
 解決Spring Security 4.1及以上版本CORS問題指南彈簧安全性cors filter:故障排除常見問題 在將Spring Security集成到現有項目中時,您可能會遇到與CORS相關的錯誤,如果像“訪問Control-allo-allow-Origin”之類的標頭,則無法設置在響應中。為了解決此問題,您可以實現自定義過濾器,例如代碼段中的MyFi...程式設計 發佈於2025-04-27
解決Spring Security 4.1及以上版本CORS問題指南彈簧安全性cors filter:故障排除常見問題 在將Spring Security集成到現有項目中時,您可能會遇到與CORS相關的錯誤,如果像“訪問Control-allo-allow-Origin”之類的標頭,則無法設置在響應中。為了解決此問題,您可以實現自定義過濾器,例如代碼段中的MyFi...程式設計 發佈於2025-04-27 -
如何在php中使用捲髮發送原始帖子請求?如何使用php 創建請求來發送原始帖子請求,開始使用curl_init()開始初始化curl session。然後,配置以下選項: curlopt_url:請求 [要發送的原始數據指定內容類型,為原始的帖子請求指定身體的內容類型很重要。在這種情況下,它是文本/平原。要執行此操作,請使用包含以下標頭...程式設計 發佈於2025-04-27
-
Java為何無法創建泛型數組?通用陣列創建錯誤 arrayList [2]; JAVA報告了“通用數組創建”錯誤。為什麼不允許這樣做? 答案:Create an Auxiliary Class:public static ArrayList<myObject>[] a = new ArrayList<my...程式設計 發佈於2025-04-27
-
我可以將加密從McRypt遷移到OpenSSL,並使用OpenSSL遷移MCRYPT加密數據?將我的加密庫從mcrypt升級到openssl 問題:是否可以將我的加密庫從McRypt升級到OpenSSL?如果是這樣,如何? 答案:是的,可以將您的Encryption庫從McRypt升級到OpenSSL。 可以使用openssl。 附加說明: [openssl_decrypt()函數要求...程式設計 發佈於2025-04-27
-
如何在GO編譯器中自定義編譯優化?在GO編譯器中自定義編譯優化 GO中的默認編譯過程遵循特定的優化策略。 However, users may need to adjust these optimizations for specific requirements.Optimization Control in Go Compi...程式設計 發佈於2025-04-27
-
如何從2D數組中提取元素?使用另一數組的索引Using NumPy Array as Indices for the 2nd Dimension of Another ArrayTo extract specific elements from a 2D array based on indices provided by a second ...程式設計 發佈於2025-04-27
-
在細胞編輯後,如何維護自定義的JTable細胞渲染?在JTable中維護jtable單元格渲染後,在JTable中,在JTable中實現自定義單元格渲染和編輯功能可以增強用戶體驗。但是,至關重要的是要確保即使在編輯操作後也保留所需的格式。 在設置用於格式化“價格”列的“價格”列,用戶遇到的數字格式丟失的“價格”列的“價格”之後,問題在設置自定義單元...程式設計 發佈於2025-04-27
-
哪種方法更有效地用於點 - 填點檢測:射線跟踪或matplotlib \的路徑contains_points?在Python Matplotlib's path.contains_points FunctionMatplotlib's path.contains_points function employs a path object to represent the polygon.它...程式設計 發佈於2025-04-27
-
解決MySQL插入Emoji時出現的\\"字符串值錯誤\\"異常Resolving Incorrect String Value Exception When Inserting EmojiWhen attempting to insert a string containing emoji characters into a MySQL database us...程式設計 發佈於2025-04-27
-
在JavaScript中如何並發運行異步操作並正確處理錯誤?同意操作execution 在執行asynchronous操作時,相關的代碼段落會遇到一個問題,當執行asynchronous操作:此實現在啟動下一個操作之前依次等待每個操作的完成。要啟用並發執行,需要進行修改的方法。 第一個解決方案試圖通過獲得每個操作的承諾來解決此問題,然後單獨等待它們: c...程式設計 發佈於2025-04-27
-
為什麼PYTZ最初顯示出意外的時區偏移?與pytz 最初從pytz獲得特定的偏移。例如,亞洲/hong_kong最初顯示一個七個小時37分鐘的偏移: 差異源利用本地化將時區分配給日期,使用了適當的時區名稱和偏移量。但是,直接使用DateTime構造器分配時區不允許進行正確的調整。 example pytz.timezone(&#...程式設計 發佈於2025-04-27
-
查找當前執行JavaScript的腳本元素方法如何引用當前執行腳本的腳本元素在某些方案中理解問題在某些方案中,開發人員可能需要將其他腳本動態加載其他腳本。但是,如果Head Element尚未完全渲染,則使用document.getElementsbytagname('head')[0] .appendChild(v)的常規方...程式設計 發佈於2025-04-27
-
如何從PHP中的數組中提取隨機元素?從陣列中的隨機選擇,可以輕鬆從數組中獲取隨機項目。考慮以下數組:; 從此數組中檢索一個隨機項目,利用array_rand( array_rand()函數從數組返回一個隨機鍵。通過將$項目數組索引使用此鍵,我們可以從數組中訪問一個隨機元素。這種方法為選擇隨機項目提供了一種直接且可靠的方法。程式設計 發佈於2025-04-27
-
為什麼Microsoft Visual C ++無法正確實現兩台模板的實例?The Mystery of "Broken" Two-Phase Template Instantiation in Microsoft Visual C Problem Statement:Users commonly express concerns that Micro...程式設計 發佈於2025-04-27
-
Android如何向PHP服務器發送POST數據?在android apache httpclient(已棄用) httpclient httpclient = new defaulthttpclient(); httppost httppost = new httppost(“ http://www.yoursite.com/script.p...程式設計 發佈於2025-04-27















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









