
使用 Scikit-Learn 完成機器學習工作流程:預測加州房價
 瀏覽:712
瀏覽:712
介绍
在本文中,我们将使用 Scikit-Learn 演示完整的机器学习项目工作流程。我们将建立一个模型,根据各种特征(例如收入中位数、房屋年龄和平均房间数量)来预测加州的房价。该项目将指导您完成该过程的每个步骤,包括数据加载、探索、模型训练、评估和结果可视化。无论您是想要了解基础知识的初学者,还是想要复习知识的经验丰富的从业者,本文都将为机器学习技术的实际应用提供宝贵的见解。
加州房价预测项目
一、简介
加州房地产市场以其独特的特征和定价动态而闻名。在这个项目中,我们的目标是开发一种机器学习模型来根据各种特征预测房价。我们将使用加州住房数据集,其中包括各种属性,例如收入中位数、房屋年龄、平均房间等。
2. 导入库
在本节中,我们将导入数据操作、可视化和构建机器学习模型所需的库。
import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error from sklearn.datasets import fetch_california_housing
3. 加载数据集
我们将加载加州住房数据集并创建一个 DataFrame 来组织数据。目标变量,即房价,将作为新列添加。
# Load the California Housing dataset california = fetch_california_housing() df = pd.DataFrame(california.data, columns=california.feature_names) df['PRICE'] = california.target
4. 随机选择样本
为了保持分析的可管理性,我们将从数据集中随机选择 700 个样本进行研究。
# Randomly Selecting 700 Samples df_sample = df.sample(n=700, random_state=42)
5.查看我们的数据
本节将提供数据集的概述,显示前五行以了解数据的特征和结构。
# Overview of the data
print("First five rows of the dataset:")
print(df_sample.head())
输出
First five rows of the dataset:
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude \
20046 1.6812 25.0 4.192201 1.022284 1392.0 3.877437 36.06
3024 2.5313 30.0 5.039384 1.193493 1565.0 2.679795 35.14
15663 3.4801 52.0 3.977155 1.185877 1310.0 1.360332 37.80
20484 5.7376 17.0 6.163636 1.020202 1705.0 3.444444 34.28
9814 3.7250 34.0 5.492991 1.028037 1063.0 2.483645 36.62
Longitude PRICE
20046 -119.01 0.47700
3024 -119.46 0.45800
15663 -122.44 5.00001
20484 -118.72 2.18600
9814 -121.93 2.78000
显示数据框信息
print(df_sample.info())
输出
Index: 700 entries, 20046 to 5350 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 MedInc 700 non-null float64 1 HouseAge 700 non-null float64 2 AveRooms 700 non-null float64 3 AveBedrms 700 non-null float64 4 Population 700 non-null float64 5 AveOccup 700 non-null float64 6 Latitude 700 non-null float64 7 Longitude 700 non-null float64 8 PRICE 700 non-null float64 dtypes: float64(9) memory usage: 54.7 KB
显示摘要统计数据
print(df_sample.describe())
输出
MedInc HouseAge AveRooms AveBedrms Population \
count 700.000000 700.000000 700.000000 700.000000 700.000000
mean 3.937653 28.855714 5.404192 1.079266 1387.422857
std 2.085831 12.353313 1.848898 0.236318 1027.873659
min 0.852700 2.000000 2.096692 0.500000 8.000000
25% 2.576350 18.000000 4.397751 1.005934 781.000000
50% 3.480000 30.000000 5.145295 1.047086 1159.500000
75% 4.794625 37.000000 6.098061 1.098656 1666.500000
max 15.000100 52.000000 36.075472 5.273585 8652.000000
AveOccup Latitude Longitude PRICE
count 700.000000 700.000000 700.000000 700.000000
mean 2.939913 35.498243 -119.439729 2.082073
std 0.745525 2.123689 1.956998 1.157855
min 1.312994 32.590000 -124.150000 0.458000
25% 2.457560 33.930000 -121.497500 1.218500
50% 2.834524 34.190000 -118.420000 1.799000
75% 3.326869 37.592500 -118.007500 2.665500
max 7.200000 41.790000 -114.590000 5.000010
6. 将数据集拆分为训练集和测试集
我们将数据集分为特征(X)和目标变量(y),然后将其分为训练集和测试集,用于模型训练和评估。
# Splitting the dataset into Train and Test sets
X = df_sample.drop('PRICE', axis=1) # Features
y = df_sample['PRICE'] # Target variable
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
7. 模型训练
在本节中,我们将使用训练数据创建和训练线性回归模型,以了解特征与房价之间的关系。
# Creating and training the Linear Regression model lr = LinearRegression() lr.fit(X_train, y_train)
8. 评估模型
我们将对测试集进行预测并计算均方误差(MSE)和R平方值来评估模型的性能。
# Making predictions on the test set
y_pred = lr.predict(X_test)
# Calculating Mean Squared Error
mse = mean_squared_error(y_test, y_pred)
print(f"\nLinear Regression Mean Squared Error: {mse}")
输出
Linear Regression Mean Squared Error: 0.3699851092128846
9. 显示实际值与预测值
在这里,我们将创建一个 DataFrame 来比较实际房价与模型生成的预测价格。
# Displaying Actual vs Predicted Values
results = pd.DataFrame({'Actual Prices': y_test.values, 'Predicted Prices': y_pred})
print("\nActual vs Predicted:")
print(results)
输出
Actual vs Predicted:
Actual Prices Predicted Prices
0 0.87500 0.887202
1 1.19400 2.445412
2 5.00001 6.249122
3 2.78700 2.743305
4 1.99300 2.794774
.. ... ...
135 1.62100 2.246041
136 3.52500 2.626354
137 1.91700 1.899090
138 2.27900 2.731436
139 1.73400 2.017134
[140 rows x
2 columns]
10. 可视化结果
在最后一节中,我们将使用散点图可视化实际房价和预测房价之间的关系,以直观地评估模型的性能。
# Visualizing the Results
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, color='blue')
plt.xlabel('Actual Prices')
plt.ylabel('Predicted Prices')
plt.title('Actual vs Predicted House Prices')
# Draw the ideal line
plt.plot([0, 6], [0, 6], color='red', linestyle='--')
# Set limits to minimize empty space
plt.xlim(y_test.min() - 1, y_test.max() 1)
plt.ylim(y_test.min() - 1, y_test.max() 1)
plt.grid()
plt.show()
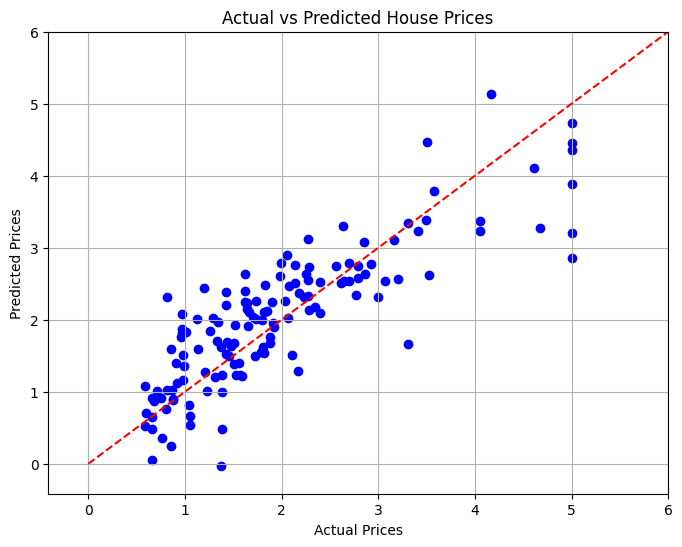
结论
在这个项目中,我们开发了一个线性回归模型来根据各种特征预测加州的房价。计算均方误差来评估模型的性能,从而提供预测准确性的定量测量。通过可视化,我们能够看到我们的模型相对于实际值的表现如何。
该项目展示了机器学习在房地产分析中的力量,可以作为更先进的预测建模技术的基础。
-
 如何使用組在MySQL中旋轉數據?在關係數據庫中使用mySQL組使用mySQL組進行查詢結果,在關係數據庫中使用MySQL組,轉移數據的數據是指重新排列的行和列的重排以增強數據可視化。在這裡,我們面對一個共同的挑戰:使用組的組將數據從基於行的基於列的轉換為基於列。 Let's consider the following ...程式設計 發佈於2025-07-02
如何使用組在MySQL中旋轉數據?在關係數據庫中使用mySQL組使用mySQL組進行查詢結果,在關係數據庫中使用MySQL組,轉移數據的數據是指重新排列的行和列的重排以增強數據可視化。在這裡,我們面對一個共同的挑戰:使用組的組將數據從基於行的基於列的轉換為基於列。 Let's consider the following ...程式設計 發佈於2025-07-02 -
eval()vs. ast.literal_eval():對於用戶輸入,哪個Python函數更安全?稱量()和ast.literal_eval()中的Python Security 在使用用戶輸入時,必須優先確保安全性。強大的Python功能Eval()通常是作為潛在解決方案而出現的,但擔心其潛在風險。 This article delves into the differences betwee...程式設計 發佈於2025-07-02
-
如何使用PHP從XML文件中有效地檢索屬性值?從php $xml = simplexml_load_file($file); foreach ($xml->Var[0]->attributes() as $attributeName => $attributeValue) { echo $attributeName,...程式設計 發佈於2025-07-02
-
PHP與C++函數重載處理的區別作為經驗豐富的C開發人員脫離謎題,您可能會遇到功能超載的概念。這個概念雖然在C中普遍,但在PHP中構成了獨特的挑戰。讓我們深入研究PHP功能過載的複雜性,並探索其提供的可能性。 在PHP中理解php的方法在PHP中,函數超載的概念(如C等語言)不存在。函數簽名僅由其名稱定義,而與他們的參數列表無關...程式設計 發佈於2025-07-02
-
如何使用Regex在PHP中有效地提取括號內的文本php:在括號內提取文本在處理括號內的文本時,找到最有效的解決方案是必不可少的。一種方法是利用PHP的字符串操作函數,如下所示: 作為替代 $ text ='忽略除此之外的一切(text)'; preg_match('#((。 &&& [Regex使用模式來搜索特...程式設計 發佈於2025-07-02
-
Async Void vs. Async Task在ASP.NET中:為什麼Async Void方法有時會拋出異常?在ASP.NET async void void async void void void void void void void的設計無需返回asynchroncon而無需返回任務對象。他們在執行過程中增加未償還操作的計數,並在完成後減少。在某些情況下,這種行為可能是有益的,例如未期望或明確...程式設計 發佈於2025-07-02
-
Python中何時用"try"而非"if"檢測變量值?使用“ try“ vs.” if”來測試python 在python中的變量值,在某些情況下,您可能需要在處理之前檢查變量是否具有值。在使用“如果”或“ try”構建體之間決定。 “ if” constructs result = function() 如果結果: 對於結果: ...程式設計 發佈於2025-07-02
-
C++中如何將獨占指針作為函數或構造函數參數傳遞?在構造函數和函數中將唯一的指數管理為參數 unique pointers( unique_ptr [2啟示。通過值: base(std :: simelor_ptr n) :next(std :: move(n)){} 此方法將唯一指針的所有權轉移到函數/對象。指針的內容被移至功能中,在操作...程式設計 發佈於2025-07-02
-
PHP SimpleXML解析帶命名空間冒號的XML方法在php 很少,請使用該限制很大,很少有很高。例如:這種技術可確保可以通過遍歷XML樹和使用兒童()方法()方法的XML樹和切換名稱空間來訪問名稱空間內的元素。程式設計 發佈於2025-07-02
-
您如何在Laravel Blade模板中定義變量?在Laravel Blade模板中使用Elegance 在blade模板中如何分配變量對於存儲以後使用的數據至關重要。在使用“ {{}}”分配變量的同時,它可能並不總是最優雅的解決方案。 幸運的是,Blade通過@php Directive提供了更優雅的方法: $ old_section =...程式設計 發佈於2025-07-02
-
如何有效地轉換PHP中的時區?在PHP 利用dateTime對象和functions DateTime對象及其相應的功能別名為時區轉換提供方便的方法。例如: //定義用戶的時區 date_default_timezone_set('歐洲/倫敦'); //創建DateTime對象 $ dateTime = ne...程式設計 發佈於2025-07-02
-
如何處理PHP文件系統功能中的UTF-8文件名?在PHP的Filesystem functions中處理UTF-8 FileNames 在使用PHP的MKDIR函數中含有UTF-8字符的文件很多flusf-8字符時,您可能會在Windows Explorer中遇到comploreer grounder grounder grounder gro...程式設計 發佈於2025-07-02
-
如何在php中使用捲髮發送原始帖子請求?如何使用php 創建請求來發送原始帖子請求,開始使用curl_init()開始初始化curl session。然後,配置以下選項: curlopt_url:請求 [要發送的原始數據指定內容類型,為原始的帖子請求指定身體的內容類型很重要。在這種情況下,它是文本/平原。要執行此操作,請使用包含以下標頭...程式設計 發佈於2025-07-02
-
如何在Java的全屏獨家模式下處理用戶輸入?Handling User Input in Full Screen Exclusive Mode in JavaIntroductionWhen running a Java application in full screen exclusive mode, the usual event ha...程式設計 發佈於2025-07-02
-
如何在鼠標單擊時編程選擇DIV中的所有文本?在鼠標上選擇div文本單擊帶有文本內容,用戶如何使用單個鼠標單擊單擊div中的整個文本?這允許用戶輕鬆拖放所選的文本或直接複製它。 在單個鼠標上單擊的div元素中選擇文本,您可以使用以下Javascript函數: function selecttext(canduterid){ if(d...程式設計 發佈於2025-07-02















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









