
比較優化如何讓 Python 排序更快
 瀏覽:585
瀏覽:585
在本文中,术语 Python 和 CPython(该语言的参考实现)可以互换使用。本文专门讨论 CPython,不涉及 Python 的任何其他实现。
Python 是一种美丽的语言,它允许程序员用简单的术语表达他们的想法,而将实际实现的复杂性抛在脑后。
它抽象出来的事情之一就是排序。
“Python中排序是如何实现的?”这个问题你可以轻松找到答案。这几乎总是回答另一个问题:“Python 使用什么排序算法?”。
然而,这通常会留下一些有趣的实现细节。
有一个实现细节我认为讨论得不够充分,尽管它是七年前在 python 3.7 中引入的:
sorted() 和 list.sort() 已针对常见情况进行了优化,速度提高了 40-75%。 (由 Elliot Gorokhovsky 在 bpo-28685 中贡献。)
但是在我们开始之前...
简要重新介绍 Python 中的排序
当你需要在python中对列表进行排序时,你有两个选择:
- 列表方法:list.sort(*, key=None, reverse=False),对给定列表进行就地排序
- 内置函数:sorted(iterable、/、*、key=None、reverse= False),返回排序列表而不修改其参数
如果需要对任何其他内置迭代进行排序,则无论作为参数传递的迭代或生成器的类型如何,都只能使用排序。
sorted 总是返回一个列表,因为它内部使用了 list.sort。
这是用纯 python 重写的 CPython 排序 C 实现的大致等效项:
def sorted(iterable: Iterable[Any], key=None, reverse=False):
new_list = list(iterable)
new_list.sort(key=key, reverse=reverse)
return new_list
是的,就这么简单。
Python 如何使排序更快
正如 Python 的内部排序文档所说:
有时可以用更快的特定类型比较来代替较慢的通用 PyObject_RichCompareBool
简单来说,这个优化可以描述如下:
当列表是同质的时,Python 使用特定于类型的比较函数
什么是同质列表?
同类列表是仅包含一种类型的元素的列表。
例如:
homogeneous = [1, 2, 3, 4]
另一方面,这不是一个同类列表:
heterogeneous = [1, "2", (3, ), {'4': 4}]
有趣的是,Python官方教程指出:
列表是可变的,并且它们的元素通常是同质的并且通过迭代列表来访问
关于元组的旁注
同一个教程指出:
元组是不可变的,并且通常包含元素的异构序列
因此,如果您想知道何时使用元组或列表,这里有一条经验法则:
如果元素具有相同类型,则使用列表,否则使用元组
等等,那么数组呢?
Python 实现了数值的同构数组容器对象。
但是,从 python 3.12 开始,数组没有实现自己的排序方法。
对它们进行排序的唯一方法是使用排序,它在内部从数组中创建一个列表,并删除该过程中任何与类型相关的信息。
为什么使用特定于类型的比较函数有帮助?
Python 中的比较成本很高,因为 Python 在进行任何实际比较之前会执行各种检查。
以下是在 python 中比较两个值时底层发生的情况的简化解释:
- Python 检查传递给比较函数的值是否不为 NULL
- 如果值的类型不同,但右操作数是左操作数的子类型,Python 使用右操作数的比较函数,但相反(例如,它将使用 )
- 如果值具有相同类型或不同类型但都不是另一个的子类型:
- Python将首先尝试左操作数的比较函数
- 如果失败,它将尝试右操作数的比较函数,但相反。
- 如果也失败,并且比较是相等或不相等,它将返回身份比较(对于引用内存中同一对象的值为 True)
- 否则,会引发 TypeError
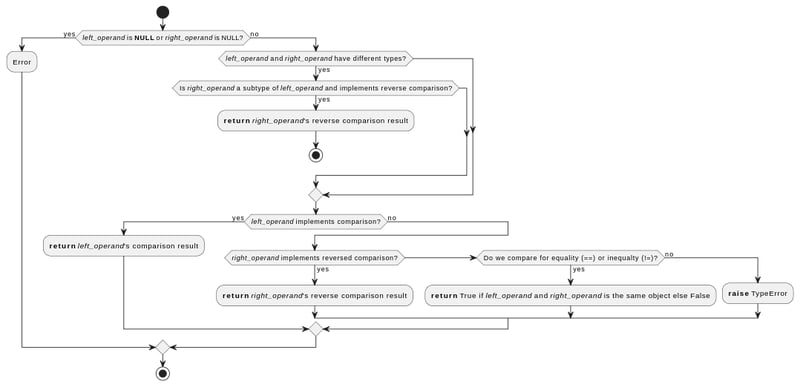
除此之外,每种类型自己的比较函数都会实现额外的检查。
例如,在比较字符串时,Python 会检查字符串字符是否占用超过一个字节的内存,而 float 比较会以不同的方式比较一对 float 以及一个 float 和一个 int。
更详细的解释和图表可以在这里找到:Adding Data-Aware Sort Optimizations to CPython
在引入此优化之前,每次在排序过程中比较两个值时,Python 都必须执行所有这些各种类型特定和非类型特定检查。
提前检查列表元素的类型
除了迭代列表并检查每个元素之外,没有什么神奇的方法可以知道列表中的所有元素是否属于同一类型。
Python 几乎完全做到了这一点 - 检查传递给 list.sort 或作为参数排序的 key 函数生成的排序键的类型
构建键列表
如果提供了 key 函数,Python 使用它来构造键列表,否则它使用列表自己的值作为排序键。
以一种过于简单的方式,键构造可以表示为以下 python 代码。
if key is None:
keys = list_items
else:
keys = [key(list_item) for list_item in list_item]
注意,CPython 内部使用的键是 CPython 对象引用的 C 数组,而不是 Python 列表
一旦构造了键,Python 就会检查它们的类型。
检查密钥类型
检查键的类型时,Python 的排序算法会尝试确定键数组中的所有元素是否都是 str、int、float 或 tuple,或者只是同一类型,但对基本类型有一些限制。
值得注意的是,检查键的类型会预先增加一些额外的工作。 Python 这样做是因为它通常可以通过加快实际排序速度来获得回报,特别是对于较长的列表。
整型约束
int 应该不是bignum
实际上,这意味着要使此优化发挥作用,整数应小于 2^30 - 1(这可能因平台而异)
作为旁注,这里有一篇很棒的文章,解释了 Python 如何处理大整数:# How python Implements super long integers?
强度约束
字符串中的所有字符应占用小于 1 个字节的内存,这意味着它们应由 0-255 范围内的整数值表示
实际上,这意味着字符串应仅包含拉丁字符、空格和 ASCII 表中的一些特殊字符。
浮动约束
为了使此优化发挥作用,浮点数没有任何限制。
元组约束
- 仅检查第一个元素的类型
- 这个元素本身不应该是一个元组
- 如果所有元组的第一个元素具有相同的类型,则比较优化将应用于它们
- 所有其他元素照常比较
我如何应用这些知识?
首先,了解一下是不是很有趣?
其次,在 Python 开发者面试中提及这些知识可能是一个很好的接触。
对于实际的代码开发来说,了解这个优化可以帮助你提高排序性能。
通过明智地选择值类型进行优化
根据引入此优化的 PR 中的基准,对仅由浮点数组成的列表进行排序,而不是对末尾带有单个整数的浮点数列表进行排序,速度几乎快两倍。
所以当需要优化时,像这样转换列表
floats_and_int = [1.0, -1.0, -0.5, 3]
进入看起来像这样的列表
just_floats = [1.0, -1.0, -0.5, 3.0] # note that 3.0 is a float now
可能会提高性能。
使用对象列表的键进行优化
虽然 Python 的排序优化适用于内置类型,但了解它如何与自定义类交互也很重要。
对自定义类的对象进行排序时,Python 依赖于您定义的比较方法,例如 __lt__(小于)或 __gt__(大于)。
但是,特定于类型的优化不适用于自定义类。
Python 将始终对这些对象使用通用比较方法。
这是一个例子:
class MyClass:
def __init__(self, value):
self.value = value
def __lt__(self, other):
return self.value
在这种情况下,Python 将使用 __lt__ 方法进行比较,但它不会从特定于类型的优化中受益。排序仍然可以正常工作,但可能不如排序内置类型那么快。
如果在对自定义对象进行排序时性能至关重要,请考虑使用返回内置类型的关键函数:
sorted_list = sorted(my_list, key=lambda x: x.value)
后记
过早的优化,尤其是在 Python 中,是邪恶的。
您不应该围绕 CPython 中的特定优化来设计整个应用程序,但了解这些优化是有好处的:充分了解您的工具是成为更熟练的开发人员的一种方式。
留意此类优化可以让您在情况需要时利用它们,特别是当性能变得至关重要时:
考虑一个场景,其中您的排序基于时间戳:使用同质整数列表(Unix 时间戳)而不是日期时间对象可以有效地利用此优化。
但是,重要的是要记住,代码的可读性和可维护性应优先于此类优化。
虽然了解这些低级细节很重要,但欣赏 Python 的高级抽象也同样重要,正是这些抽象使其成为一种高效的语言。
Python 是一门令人惊叹的语言,探索其深度可以帮助您更好地理解它并成为一名更好的 Python 程序员。
-
 Java中Lambda表達式為何需要“final”或“有效final”變量?Lambda Expressions Require "Final" or "Effectively Final" VariablesThe error message "Variable used in lambda expression shou...程式設計 發佈於2025-07-13
Java中Lambda表達式為何需要“final”或“有效final”變量?Lambda Expressions Require "Final" or "Effectively Final" VariablesThe error message "Variable used in lambda expression shou...程式設計 發佈於2025-07-13 -
Python中嵌套函數與閉包的區別是什麼嵌套函數與python 在python中的嵌套函數不被考慮閉合,因為它們不符合以下要求:不訪問局部範圍scliables to incling scliables在封裝範圍外執行範圍的局部範圍。 make_printer(msg): DEF打印機(): 打印(味精) ...程式設計 發佈於2025-07-13
-
如何使用Python理解有效地創建字典?在python中,詞典綜合提供了一種生成新詞典的簡潔方法。儘管它們與列表綜合相似,但存在一些顯著差異。 與問題所暗示的不同,您無法為鑰匙創建字典理解。您必須明確指定鍵和值。 For example:d = {n: n**2 for n in range(5)}This creates a dict...程式設計 發佈於2025-07-13
-
為什麼使用Firefox後退按鈕時JavaScript執行停止?導航歷史記錄問題:JavaScript使用Firefox Back Back 此行為是由瀏覽器緩存JavaScript資源引起的。要解決此問題並確保在後續頁面訪問中執行腳本,Firefox用戶應設置一個空功能。 警報'); }; alert('inline Alert')...程式設計 發佈於2025-07-13
-
如何檢查對像是否具有Python中的特定屬性?方法來確定對象屬性存在尋求一種方法來驗證對像中特定屬性的存在。考慮以下示例,其中嘗試訪問不確定屬性會引起錯誤: >>> a = someClass() >>> A.property Trackback(最近的最新電話): 文件“ ”,第1行, attributeError:SomeClass實...程式設計 發佈於2025-07-13
-
Java中如何使用觀察者模式實現自定義事件?在Java 中創建自定義事件的自定義事件在許多編程場景中都是無關緊要的,使組件能夠基於特定的觸發器相互通信。本文旨在解決以下內容:問題語句我們如何在Java中實現自定義事件以促進基於特定事件的對象之間的交互,定義了管理訂閱者的類界面。 以下代碼片段演示瞭如何使用觀察者模式創建自定義事件: args...程式設計 發佈於2025-07-13
-
如何將來自三個MySQL表的數據組合到新表中?mysql:從三個表和列的新表創建新表 答案:為了實現這一目標,您可以利用一個3-way Join。 選擇p。 *,d.content作為年齡 來自人為p的人 加入d.person_id = p.id上的d的詳細信息 加入T.Id = d.detail_id的分類法 其中t.taxonomy ...程式設計 發佈於2025-07-13
-
將圖片浮動到底部右側並環繞文字的技巧在Web設計中圍繞在Web設計中,有時可以將圖像浮動到頁面右下角,從而使文本圍繞它纏繞。這可以在有效地展示圖像的同時創建一個吸引人的視覺效果。 css位置在右下角,使用css float and clear properties: img { 浮點:對; ...程式設計 發佈於2025-07-13
-
如何在Java的全屏獨家模式下處理用戶輸入?Handling User Input in Full Screen Exclusive Mode in JavaIntroductionWhen running a Java application in full screen exclusive mode, the usual event ha...程式設計 發佈於2025-07-13
-
在細胞編輯後,如何維護自定義的JTable細胞渲染?在JTable中維護jtable單元格渲染後,在JTable中,在JTable中實現自定義單元格渲染和編輯功能可以增強用戶體驗。但是,至關重要的是要確保即使在編輯操作後也保留所需的格式。 在設置用於格式化“價格”列的“價格”列,用戶遇到的數字格式丟失的“價格”列的“價格”之後,問題在設置自定義單元...程式設計 發佈於2025-07-13
-
左連接為何在右表WHERE子句過濾時像內連接?左JOIN CONUNDRUM:WITCHING小時在數據庫Wizard的領域中變成內在的加入很有趣,當將c.foobar條件放置在上面的Where子句中時,據說左聯接似乎會轉換為內部連接。僅當滿足A.Foo和C.Foobar標準時,才會返回結果。 為什麼要變形?關鍵在於其中的子句。當左聯接的右側...程式設計 發佈於2025-07-13
-
如何使用Python的請求和假用戶代理繞過網站塊?如何使用Python的請求模擬瀏覽器行為,以及偽造的用戶代理提供了一個用戶 - 代理標頭一個有效方法是提供有效的用戶式header,以提供有效的用戶 - 設置,該標題可以通過browser和Acterner Systems the equestersystermery和操作系統。通過模仿像Chro...程式設計 發佈於2025-07-13
-
如何有效地轉換PHP中的時區?在PHP 利用dateTime對象和functions DateTime對象及其相應的功能別名為時區轉換提供方便的方法。例如: //定義用戶的時區 date_default_timezone_set('歐洲/倫敦'); //創建DateTime對象 $ dateTime = ne...程式設計 發佈於2025-07-13















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









