
使用 OpenVINO 和 Postgres 建立快速且有效率的語意搜尋系統
 瀏覽:841
瀏覽:841

照片由 real-napster 在 Pixabay上拍摄
在我最近的一个项目中,我必须构建一个语义搜索系统,该系统可以高性能扩展并为报告搜索提供实时响应。我们在 AWS RDS 上使用 PostgreSQL 和 pgvector,并搭配 AWS Lambda 来实现这一目标。面临的挑战是允许用户使用自然语言查询而不是依赖严格的关键字进行搜索,同时确保响应时间在 1-2 秒甚至更短,并且只能利用 CPU 资源。
在这篇文章中,我将逐步介绍构建此搜索系统的步骤,从检索到重新排名,以及使用 OpenVINO 和智能批处理进行标记化进行的优化。
语义搜索概述:检索和重新排序
现代最先进的搜索系统通常由两个主要步骤组成:检索和重新排名。
1) 检索:第一步涉及根据用户查询检索相关文档的子集。这可以使用预先训练的嵌入模型来完成,例如 OpenAI 的小型和大型嵌入、Cohere 的嵌入模型或 Mixbread 的 mxbai 嵌入。检索的重点是通过测量文档与查询的相似性来缩小文档池的范围。
这是一个使用 Huggingface 的句子转换器库进行检索的简化示例,这是我最喜欢的库之一:
from sentence_transformers import SentenceTransformer
import numpy as np
# Load a pre-trained sentence transformer model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# Sample query and documents (vectorize the query and the documents)
query = "How do I fix a broken landing gear?"
documents = ["Report 1 on landing gear failure", "Report 2 on engine problems"]
# Get embeddings for query and documents
query_embedding = model.encode(query)
document_embeddings = model.encode(documents)
# Calculate cosine similarity between query and documents
similarities = np.dot(document_embeddings, query_embedding)
# Retrieve top-k most relevant documents
top_k = np.argsort(similarities)[-5:]
print("Top 5 documents:", [documents[i] for i in top_k])
2) 重新排名:检索到最相关的文档后,我们使用交叉编码器模型进一步提高这些文档的排名。此步骤会更准确地重新评估与查询相关的每个文档,重点关注更深入的上下文理解。
重新排名是有益的,因为它通过更精确地评分每个文档的相关性来增加额外的细化层。
下面是使用 cross-encoder/ms-marco-TinyBERT-L-2-v2(轻量级交叉编码器)进行重新排名的代码示例:
from sentence_transformers import CrossEncoder
# Load the cross-encoder model
cross_encoder = CrossEncoder("cross-encoder/ms-marco-TinyBERT-L-2-v2")
# Use the cross-encoder to rerank top-k retrieved documents
query_document_pairs = [(query, doc) for doc in documents]
scores = cross_encoder.predict(query_document_pairs)
# Rank documents based on the new scores
top_k_reranked = np.argsort(scores)[-5:]
print("Top 5 reranked documents:", [documents[i] for i in top_k_reranked])
识别瓶颈:标记化和预测的成本
在开发过程中,我发现在使用句子转换器的默认设置处理 1,000 个报告时,标记化和预测阶段花费了相当长的时间。这造成了性能瓶颈,特别是因为我们的目标是实时响应。
下面我使用 SnakeViz 分析了我的代码以可视化性能:
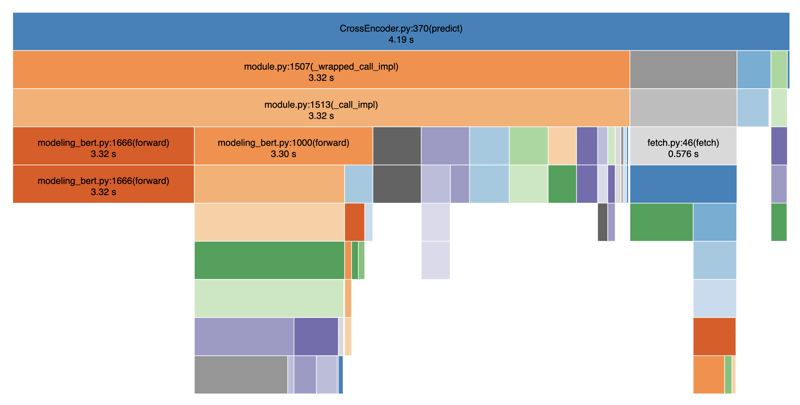
正如您所看到的,标记化和预测步骤异常缓慢,导致提供搜索结果的严重延迟。总的来说,平均需要 4-5 秒。这是因为标记化和预测步骤之间存在阻塞操作。如果我们还添加其他操作,如数据库调用、过滤等,我们很容易就总共需要 8-9 秒。
使用 OpenVINO 优化性能
我面临的问题是:我们可以让它更快吗?答案是肯定的,通过利用OpenVINO,一个针对 CPU 推理的优化后端。 OpenVINO 有助于加速英特尔硬件上的深度学习模型推理,我们在 AWS Lambda 上使用该硬件。
OpenVINO 优化的代码示例
以下是我如何将 OpenVINO 集成到搜索系统中以加快推理速度:
import argparse
import numpy as np
import pandas as pd
from typing import Any
from openvino.runtime import Core
from transformers import AutoTokenizer
def load_openvino_model(model_path: str) -> Core:
core = Core()
model = core.read_model(model_path ".xml")
compiled_model = core.compile_model(model, "CPU")
return compiled_model
def rerank(
compiled_model: Core,
query: str,
results: list[str],
tokenizer: AutoTokenizer,
batch_size: int,
) -> np.ndarray[np.float32, Any]:
max_length = 512
all_logits = []
# Split results into batches
for i in range(0, len(results), batch_size):
batch_results = results[i : i batch_size]
inputs = tokenizer(
[(query, item) for item in batch_results],
padding=True,
truncation="longest_first",
max_length=max_length,
return_tensors="np",
)
# Extract input tensors (convert to NumPy arrays)
input_ids = inputs["input_ids"].astype(np.int32)
attention_mask = inputs["attention_mask"].astype(np.int32)
token_type_ids = inputs.get("token_type_ids", np.zeros_like(input_ids)).astype(
np.int32
)
infer_request = compiled_model.create_infer_request()
output = infer_request.infer(
{
"input_ids": input_ids,
"attention_mask": attention_mask,
"token_type_ids": token_type_ids,
}
)
logits = output["logits"]
all_logits.append(logits)
all_logits = np.concatenate(all_logits, axis=0)
return all_logits
def fetch_search_data(search_text: str) -> pd.DataFrame:
# Usually you would fetch the data from a database
df = pd.read_csv("cnbc_headlines.csv")
df = df[~df["Headlines"].isnull()]
texts = df["Headlines"].tolist()
# Load the model and rerank
openvino_model = load_openvino_model("cross-encoder-openvino-model/model")
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-2-v2")
rerank_scores = rerank(openvino_model, search_text, texts, tokenizer, batch_size=16)
# Add the rerank scores to the DataFrame and sort by the new scores
df["rerank_score"] = rerank_scores
df = df.sort_values(by="rerank_score", ascending=False)
return df
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Fetch search results with reranking using OpenVINO"
)
parser.add_argument(
"--search_text",
type=str,
required=True,
help="The search text to use for reranking",
)
args = parser.parse_args()
df = fetch_search_data(args.search_text)
print(df)
通过这种方法,我们可以获得 2-3 倍的加速,将原来的 4-5 秒减少到 1-2 秒。完整的工作代码位于 Github 上。
速度微调:批量大小和标记化
提高性能的另一个关键因素是优化令牌化流程并调整批量大小和令牌长度。通过增加批量大小(batch_size = 16)和减少令牌长度(max_length = 512),我们可以并行化令牌化并减少重复操作的开销。在我们的实验中,我们发现 16 到 64 之间的 batch_size 效果很好,任何更大的值都会降低性能。同样,我们将 max_length 设置为 128,如果报告的平均长度相对较短,则该值是可行的。通过这些更改,我们实现了 8 倍的整体加速,将重新排名时间缩短至 1 秒以下,即使在 CPU 上也是如此。
在实践中,这意味着尝试不同的批量大小和令牌长度,以找到数据速度和准确性之间的适当平衡。通过这样做,我们看到响应时间显着缩短,使得搜索系统即使有 1,000 份报告也可扩展。
结论
通过使用 OpenVINO 并优化标记化和批处理,我们能够构建一个高性能语义搜索系统,满足仅 CPU 设置的实时要求。事实上,我们的整体速度提升了 8 倍。使用句子转换器的检索和使用交叉编码器模型的重新排名相结合,创造了强大的、用户友好的搜索体验。
如果您正在构建响应时间和计算资源受到限制的类似系统,我强烈建议您探索 OpenVINO 和智能批处理以释放更好的性能。
希望您喜欢这篇文章。如果您觉得这篇文章有用,请给我一个赞,以便其他人也可以找到它,并与您的朋友分享。在 Linkedin 上关注我,了解我的最新工作。感谢您的阅读!
-
 PHP與C++函數重載處理的區別作為經驗豐富的C開發人員脫離謎題,您可能會遇到功能超載的概念。這個概念雖然在C中普遍,但在PHP中構成了獨特的挑戰。讓我們深入研究PHP功能過載的複雜性,並探索其提供的可能性。 在PHP中理解php的方法在PHP中,函數超載的概念(如C等語言)不存在。函數簽名僅由其名稱定義,而與他們的參數列表無關...程式設計 發佈於2025-07-02
PHP與C++函數重載處理的區別作為經驗豐富的C開發人員脫離謎題,您可能會遇到功能超載的概念。這個概念雖然在C中普遍,但在PHP中構成了獨特的挑戰。讓我們深入研究PHP功能過載的複雜性,並探索其提供的可能性。 在PHP中理解php的方法在PHP中,函數超載的概念(如C等語言)不存在。函數簽名僅由其名稱定義,而與他們的參數列表無關...程式設計 發佈於2025-07-02 -
如何使用“ JSON”軟件包解析JSON陣列?parsing JSON與JSON軟件包 QUALDALS:考慮以下go代碼:字符串 } func main(){ datajson:=`[“ 1”,“ 2”,“ 3”]`` arr:= jsontype {} 摘要:= = json.unmarshal([] byte(...程式設計 發佈於2025-07-02
-
如何實時捕獲和流媒體以進行聊天機器人命令執行?在開發能夠執行命令的chatbots的領域中,實時從命令執行實時捕獲Stdout,一個常見的需求是能夠檢索和顯示標準輸出(stdout)在cath cath cant cant cant cant cant cant cant cant interfaces in Chate cant inter...程式設計 發佈於2025-07-02
-
PHP陣列鍵值異常:了解07和08的好奇情況PHP數組鍵值問題,使用07&08 在給定數月的數組中,鍵值07和08呈現令人困惑的行為時,就會出現一個不尋常的問題。運行print_r($月)返回意外結果:鍵“ 07”丟失,而鍵“ 08”分配給了9月的值。 此問題源於PHP對領先零的解釋。當一個數字帶有0(例如07或08)的前綴時,PHP將...程式設計 發佈於2025-07-02
-
我可以將加密從McRypt遷移到OpenSSL,並使用OpenSSL遷移MCRYPT加密數據?將我的加密庫從mcrypt升級到openssl 問題:是否可以將我的加密庫從McRypt升級到OpenSSL?如果是這樣,如何? 答案:是的,可以將您的Encryption庫從McRypt升級到OpenSSL。 可以使用openssl。 附加說明: [openssl_decrypt()函數要求...程式設計 發佈於2025-07-02
-
如何使用不同數量列的聯合數據庫表?合併列數不同的表 當嘗試合併列數不同的數據庫表時,可能會遇到挑戰。一種直接的方法是在列數較少的表中,為缺失的列追加空值。 例如,考慮兩個表,表 A 和表 B,其中表 A 的列數多於表 B。為了合併這些表,同時處理表 B 中缺失的列,請按照以下步驟操作: 確定表 B 中缺失的列,並將它們添加到表的...程式設計 發佈於2025-07-02
-
編譯器報錯“usr/bin/ld: cannot find -l”解決方法錯誤:“ usr/bin/ld:找不到-l “ 此錯誤表明鏈接器在鏈接您的可執行文件時無法找到指定的庫。為了解決此問題,我們將深入研究如何指定庫路徑並將鏈接引導到正確位置的詳細信息。 添加庫搜索路徑的一個可能的原因是,此錯誤是您的makefile中缺少庫搜索路徑。要解決它,您可以在鏈接器命令中添...程式設計 發佈於2025-07-02
-
eval()vs. ast.literal_eval():對於用戶輸入,哪個Python函數更安全?稱量()和ast.literal_eval()中的Python Security 在使用用戶輸入時,必須優先確保安全性。強大的Python功能Eval()通常是作為潛在解決方案而出現的,但擔心其潛在風險。 This article delves into the differences betwee...程式設計 發佈於2025-07-02
-
在Java中使用for-to-loop和迭代器進行收集遍歷之間是否存在性能差異?For Each Loop vs. Iterator: Efficiency in Collection TraversalIntroductionWhen traversing a collection in Java, the choice arises between using a for-...程式設計 發佈於2025-07-02
-
Java中如何使用觀察者模式實現自定義事件?在Java 中創建自定義事件的自定義事件在許多編程場景中都是無關緊要的,使組件能夠基於特定的觸發器相互通信。本文旨在解決以下內容:問題語句我們如何在Java中實現自定義事件以促進基於特定事件的對象之間的交互,定義了管理訂閱者的類界面。 以下代碼片段演示瞭如何使用觀察者模式創建自定義事件: args...程式設計 發佈於2025-07-02
-
如何使用PHP從XML文件中有效地檢索屬性值?從php $xml = simplexml_load_file($file); foreach ($xml->Var[0]->attributes() as $attributeName => $attributeValue) { echo $attributeName,...程式設計 發佈於2025-07-02
-
切換到MySQLi後CodeIgniter連接MySQL數據庫失敗原因Unable to Connect to MySQL Database: Troubleshooting Error MessageWhen attempting to switch from the MySQL driver to the MySQLi driver in CodeIgniter,...程式設計 發佈於2025-07-02
-
Go web應用何時關閉數據庫連接?在GO Web Applications中管理數據庫連接很少,考慮以下簡化的web應用程序代碼:出現的問題:何時應在DB連接上調用Close()方法? ,該特定方案將自動關閉程序時,該程序將在EXITS EXITS EXITS出現時自動關閉。但是,其他考慮因素可能保證手動處理。 選項1:隱式關閉終...程式設計 發佈於2025-07-02
-
如何修復\“常規錯誤:2006 MySQL Server在插入數據時已經消失\”?How to Resolve "General error: 2006 MySQL server has gone away" While Inserting RecordsIntroduction:Inserting data into a MySQL database can...程式設計 發佈於2025-07-02
-
如何高效地在一個事務中插入數據到多個MySQL表?mySQL插入到多個表中,該數據可能會產生意外的結果。雖然似乎有多個查詢可以解決問題,但將從用戶表的自動信息ID與配置文件表的手動用戶ID相關聯提出了挑戰。 使用Transactions和last_insert_id() 插入用戶(用戶名,密碼)值('test','tes...程式設計 發佈於2025-07-02















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









