 титульная страница > программирование > Я создал приложение для проверки количества токенов с помощью Streamlit в Snowflake (SiS).
титульная страница > программирование > Я создал приложение для проверки количества токенов с помощью Streamlit в Snowflake (SiS).
Я создал приложение для проверки количества токенов с помощью Streamlit в Snowflake (SiS).
 Просматривать:659
Просматривать:659
Введение
Здравствуйте, я инженер по продажам в Snowflake. Я хотел бы поделиться с вами своим опытом и экспериментами в различных постах. В этой статье я покажу вам, как создать приложение с использованием Streamlit в Snowflake для проверки количества токенов и оценки затрат на Cortex LLM.
Примечание: этот пост отражает мои личные взгляды, а не взгляды Снежинки.
Что такое Streamlit в Snowflake (SiS)?
Streamlit — это библиотека Python, которая позволяет создавать веб-интерфейсы с помощью простого кода Python, устраняя необходимость в HTML/CSS/JavaScript. Вы можете увидеть примеры в галерее приложений.
Streamlit в Snowflake позволяет разрабатывать и запускать веб-приложения Streamlit непосредственно в Snowflake. Его легко использовать, имея только учетную запись Snowflake, и он отлично подходит для интеграции данных таблиц Snowflake в веб-приложения.
О Streamlit в Snowflake (официальная документация Snowflake)
Что такое кора снежинки?
Snowflake Cortex — это набор генеративных функций искусственного интеллекта в Snowflake. Cortex LLM позволяет вызывать большие языковые модели, работающие на Snowflake, с помощью простых функций SQL или Python.
Функции большой языковой модели (LLM) (Snowflake Cortex) (официальная документация Snowflake)
Обзор функций
Изображение
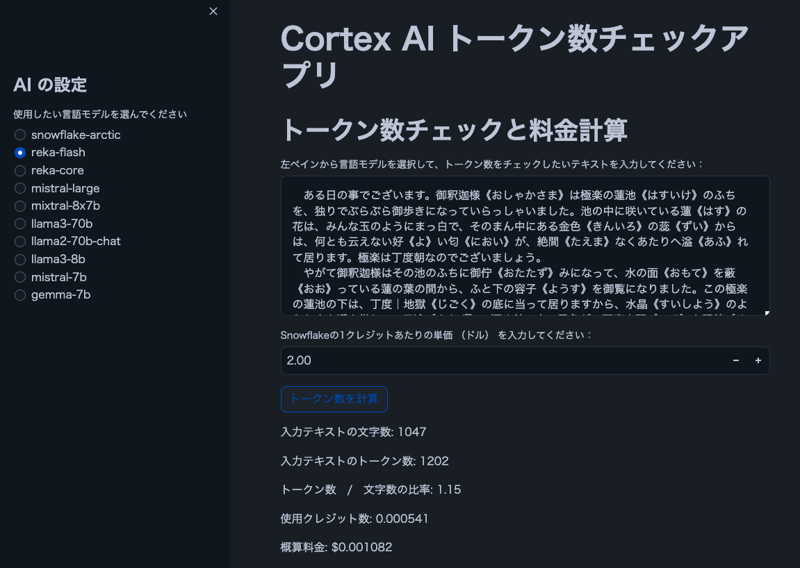
Примечание: текст на изображении взят из «Паучьей нити» Рюносукэ Акутагавы.
Функции
- Пользователи могут выбрать модель Cortex LLM
- Отображение количества символов и токенов для текста, вводимого пользователем
- Показать соотношение токенов к символам
- Расчет ориентировочной стоимости на основе цены кредита Snowflake
Примечание: таблица цен Cortex LLM (PDF)
Предварительные условия
- Аккаунт Snowflake с доступом к Cortex LLM
- snowflake-ml-python 1.1.2 или новее
Примечание: доступность региона Cortex LLM (официальная документация Snowflake)
Исходный код
import streamlit as st
from snowflake.snowpark.context import get_active_session
import snowflake.snowpark.functions as F
# Get current session
session = get_active_session()
# Application title
st.title("Cortex AI Token Count Checker")
# AI settings
st.sidebar.title("AI Settings")
lang_model = st.sidebar.radio("Select the language model you want to use",
("snowflake-arctic", "reka-core", "reka-flash",
"mistral-large2", "mistral-large", "mixtral-8x7b", "mistral-7b",
"llama3.1-405b", "llama3.1-70b", "llama3.1-8b",
"llama3-70b", "llama3-8b", "llama2-70b-chat",
"jamba-instruct", "gemma-7b")
)
# Function to count tokens (using Cortex's token counting function)
def count_tokens(model, text):
result = session.sql(f"SELECT SNOWFLAKE.CORTEX.COUNT_TOKENS('{model}', '{text}') as token_count").collect()
return result[0]['TOKEN_COUNT']
# Token count check and cost calculation
st.header("Token Count Check and Cost Calculation")
input_text = st.text_area("Select a language model from the left pane and enter the text you want to check for token count:", height=200)
# Let user input the price per credit
credit_price = st.number_input("Enter the price per Snowflake credit (in dollars):", min_value=0.0, value=2.0, step=0.01)
# Credits per 1M tokens for each model (as of 2024/8/30, mistral-large2 is not supported)
model_credits = {
"snowflake-arctic": 0.84,
"reka-core": 5.5,
"reka-flash": 0.45,
"mistral-large2": 1.95,
"mistral-large": 5.1,
"mixtral-8x7b": 0.22,
"mistral-7b": 0.12,
"llama3.1-405b": 3,
"llama3.1-70b": 1.21,
"llama3.1-8b": 0.19,
"llama3-70b": 1.21,
"llama3-8b": 0.19,
"llama2-70b-chat": 0.45,
"jamba-instruct": 0.83,
"gemma-7b": 0.12
}
if st.button("Calculate Token Count"):
if input_text:
# Calculate character count
char_count = len(input_text)
st.write(f"Character count of input text: {char_count}")
if lang_model in model_credits:
# Calculate token count
token_count = count_tokens(lang_model, input_text)
st.write(f"Token count of input text: {token_count}")
# Ratio of tokens to characters
ratio = token_count / char_count if char_count > 0 else 0
st.write(f"Token count / Character count ratio: {ratio:.2f}")
# Cost calculation
credits_used = (token_count / 1000000) * model_credits[lang_model]
cost = credits_used * credit_price
st.write(f"Credits used: {credits_used:.6f}")
st.write(f"Estimated cost: ${cost:.6f}")
else:
st.warning("The selected model is not supported by Snowflake's token counting feature.")
else:
st.warning("Please enter some text.")
Заключение
Это приложение упрощает оценку затрат на рабочие нагрузки LLM, особенно при работе с такими языками, как японский, где часто существует разрыв между количеством символов и количеством токенов. Надеюсь, оно окажется для вас полезным!
Объявления
Snowflake Что нового, обновления на X
Я делюсь обновлениями Snowflake «Что нового» на X. Если вам интересно, подписывайтесь!
Английская версия
Что нового в боте Snowflake (английская версия)
https://x.com/snow_new_en
Японская версия
Что нового в боте Snowflake (японская версия)
https://x.com/snow_new_jp
История изменений
(20240914) Исходное сообщение
Оригинальная японская статья
https://zenn.dev/tsubasa_tech/articles/4dd80c91508ec4
-
 Как объединить данные из трех таблиц MySQL в новую таблицу?mySQL: Creating a New Table from Data and Columns of Three TablesQuestion:How can I create a new table that combines selected data from three existing...программирование Опубликовано в 2025-07-09
Как объединить данные из трех таблиц MySQL в новую таблицу?mySQL: Creating a New Table from Data and Columns of Three TablesQuestion:How can I create a new table that combines selected data from three existing...программирование Опубликовано в 2025-07-09 -
Почему я получаю ошибку «не удалось найти внедрение ошибки с шаблоном запроса» в моем запросе Silverlight Linq?] Запрос. Отсутствие реализации: разрешение «не удалось найти« Ошибки в приложении Silverlight, попытка установить соединение базы данных с исп...программирование Опубликовано в 2025-07-09
-
Как эффективно изменить атрибут CSS «: после» псевдоэлемента с использованием jQuery?понимание ограничений псевдо-элементов в jQuery: доступ к ": после" selector в веб-разработке, псевдо-элементы, такие как ": по...программирование Опубликовано в 2025-07-09
-
Могут ли параметры шаблона в C ++ 20 постоянной функции зависеть от параметров функции?постоянные функции и параметры шаблона, зависящие от аргументов функций в C 17, параметр шаблона не может зависеть от аргумента, потому что он...программирование Опубликовано в 2025-07-09
-
В чем разница между вложенными функциями и закрытием в Python] вложенные функции против закрытия в Python , в то время как вложенные функции в Python поверхностно напоминают закрытия, они в основном отлича...программирование Опубликовано в 2025-07-09
-
Почему Microsoft Visual C ++ не может правильно реализовать двухфазной экземпляры?загадка «Сломанная» двухфазное матричное экземпляры в Microsoft Visual C Задача задачи: пользователи обычно выражают обеспокоенность Microso...программирование Опубликовано в 2025-07-09
-
Как разрешить расходы на путь модуля в Go Mod с помощью директивы «Заменить»?Распространение пути преодоления модуля в Go Mod При использовании MOD можно столкнуться с конфликтом, где 3 -й пакет импортирует другой пакет...программирование Опубликовано в 2025-07-09
-
Как разрешить ошибку \ "Неверное использование групповой функции \" в MySQL при поиске максимального подсчета?Как получить максимальный счет, используя MySQL В MySQL вы можете столкнуться с проблемой, пытаясь найти максимальный подсчет значений, сгрупп...программирование Опубликовано в 2025-07-09
-
Причины и решения для сбоя обнаружения лица: ошибка -215обработка ошибок: разрешение «ошибка: (-215)! Empty () в функции DetectMultiscale" в OpenCV при попытке использовать метод DeTectMultisca...программирование Опубликовано в 2025-07-09
-
Как предотвратить дублирующие материалы после обновления формы?предотвращение дублирующих материалов с помощью обработки обновления В веб -разработке обычно встречается с проблемой дублирования материалов,...программирование Опубликовано в 2025-07-09
-
Python Metaclass Principle и создание и настройку классаЧто такое Metaclass в Python? Так же, как классы создают экземпляры, MetaClasses создают классы. Они обеспечивают уровень контроля над процессом с...программирование Опубликовано в 2025-07-09
-
Могут ли CSS найти HTML -элементы на основе какого -либо значения атрибута?] нацеливание html -элементов с любым значением атрибута в CSS в CSS, можно нацелить элементы на основе конкретных атрибутов, как показано в пр...программирование Опубликовано в 2025-07-09
-
Как я могу объединить таблицы базы данных с различным числом столбцов?объединенные таблицы с разными столбцами ] может столкнуться с проблемами при попытке объединить таблицы баз данных с разными столбцами. Просто...программирование Опубликовано в 2025-07-09
-
Как передавать эксклюзивные указатели в качестве функции или параметров конструктора в C ++?] управление уникальными указателями как параметры в конструкторах и функциях уникальные указатели ( уникальный Последствия. прохождение по зн...программирование Опубликовано в 2025-07-09
-
Методы доступа и управления переменными среды Pythonдоступа к переменным среды в Python для доступа к переменным среды в Python Использовать os.environ объект, который представляет картировани...программирование Опубликовано в 2025-07-09















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









