 титульная страница > программирование > Что быстрее и дешевле конвертировать файлы в AWS: Polar или Pandas?
титульная страница > программирование > Что быстрее и дешевле конвертировать файлы в AWS: Polar или Pandas?
Что быстрее и дешевле конвертировать файлы в AWS: Polar или Pandas?
 Просматривать:343
Просматривать:343
Оба предлагают широкий спектр инструментов и преимуществ, которые могут заставить нас усомниться в том, какой из двух выбрать в какой-то момент. Речь идет не об изменении всех процессов компании, чтобы они начали использовать Polars или о «смерти» Pandas (это произойдет не в ближайшем будущем). Речь идет о знании других инструментов, которые могут помочь нам сократить затраты и время в процессах, получив такие же или лучшие результаты.
Когда мы используем облачные сервисы, мы уделяем приоритетное внимание определенным факторам, включая их стоимость. Для этого процесса я использую сервисы AWS Lambda со средой выполнения Python 3.10 и S3 для хранения необработанного файла и файла, преобразованного в паркет.
Намерение состоит в том, чтобы получить файл CSV в виде необработанных данных и обработать его с помощью pandas и Polar с целью проверки, какая из этих двух библиотек предлагает нам лучшую оптимизацию ресурсов, таких как память и вес результирующего файла.
]Панды
Это библиотека Python, специализирующаяся на манипулировании и анализе данных. Она написана на C, ее первый выпуск состоялся в 2008 году.
*Поляры *
Это библиотека Python и Rust, специализирующаяся на манипулировании и анализе данных, которая позволяет выполнять параллельные процессы, написана в основном на Rust и выпущена в 2022 году.
Архитектура процесса:
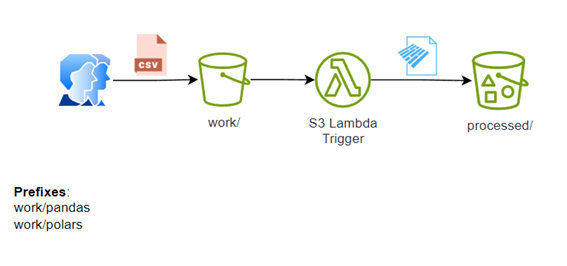
Проект довольно прост, как показано в архитектуре: пользователь помещает CSV-файл в папку work/pandas или work/porlas и автоматически запускает триггер s3 для обработки файла, чтобы преобразовать его в паркет и отправить в обработку.
В этом небольшом проекте используйте две лямбды со следующей конфигурацией:
Память: 2 ГБ
Эфемерная память: 2 ГБ
Время жизни: 600 секунд
Требования
Лямбда с пандами: Pandas, Numpy и Pyarrow
Лямбда с полярами: Поляры
Набор данных, использованный для сравнения, доступен на Kaggle под названием «Обзоры фильмов на Rotten Tomatoes — 1,44 млн строк» или может быть загружен отсюда.
Полный репозиторий доступен на GitHub, его можно клонировать здесь.
Размер или вес
Лямбда, которую использует Pandas, требует еще двух плагинов для создания файла паркета, в данном случае это PyArrow и конкретная версия numpy для версии Pandas, которую я использовал. В результате мы получили лямбду с весом или размером 74,4 МБ, что очень близко к пределу, который AWS допускает для веса лямбды.
Лямбда с Polars не требует другого плагина, такого как PyArrow, который упрощает жизнь и уменьшает размер лямбды менее чем вдвое. В результате наша лямбда имеет вес или размер 30,6 МБ по сравнению с первой, что дает нам место для установки других зависимостей, которые могут нам понадобиться для процесса преобразования.
Производительность
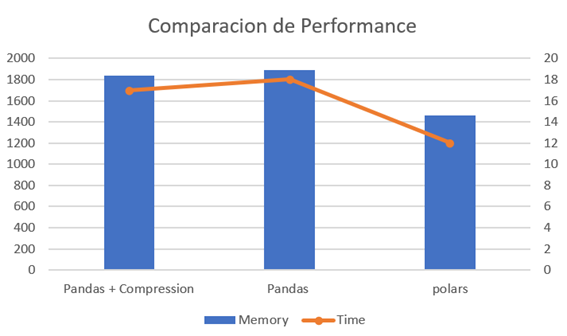
Лямбда с Pandas была оптимизирована для использования сжатия после первой версии, однако ее поведение также было проанализировано.
Панды
Обработка набора данных заняла 18 секунд, а для обработки CSV-файла и создания файла Parquet потребовалось 1894 МБ памяти. По сравнению с другими версиями, именно эта версия требовала больше всего времени и ресурсов.
Сжатие Pandas
Добавление строки кода позволило нам немного улучшиться по сравнению с предыдущей версией (Pandas), на обработку набора данных ушло 17 секунд и использовано 1837 МБ, что представляет собой существенное улучшение не во времени обработки и вычислений, а в размере. полученного файла.
Полярные территории
Обработка того же набора данных заняла 12 секунд, а я использовал всего 1462 МБ, по сравнению с двумя предыдущими, это означает экономию времени на 44,44% и меньшее потребление памяти.
Размер выходного файла
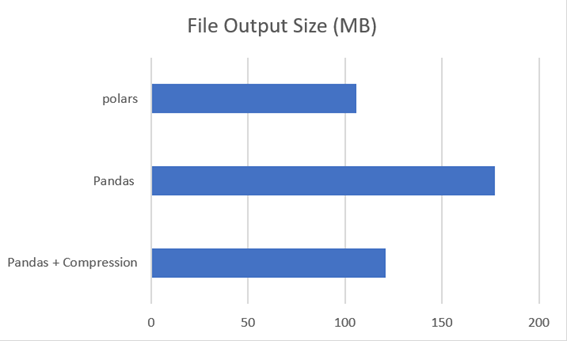
Панды
Лямбда, в которой не был установлен процесс сжатия, создала паркетный файл размером 177,4 МБ.
Сжатие Pandas
При настройке сжатия в лямбде у меня не создается паркетный файл размером 121,1 МБ. Одна небольшая строка или опция помогла нам уменьшить размер файла на 31,74%. Учитывая, что это не существенное изменение кода, это очень хороший вариант.
Полярные территории
Polars создала файл размером 105,8 МБ, который, приобретенный вместе с первой версией Pandas, представляет собой экономию на 40,36% и 12,63% по сравнению с версией Pandas со сжатием.
Заключение
Нет необходимости менять все внутренние процессы, использующие Pandas, чтобы они теперь использовали Polars, однако важно учитывать, что если мы говорим о тысячах или миллионах выполнения лямбда-выражений, использование Polars поможет нам не только с развертыванием время, но также поможет нам снизить затраты благодаря повременной тарификации, которую AWS взимает за бессерверные сервисы, такие как Lambda.
Аналогичным образом, когда мы переводим эти 40,36% в миллионы файлов, мы говорим о ГБ или ТБ, что окажет существенное влияние на Datalake или Dataware или даже на холодное файловое хранилище.
Сокращение с помощью Polars не будет ограничиваться только этими двумя факторами, поскольку это сильно повлияет на вывод данных и/или объектов из AWS, поскольку это услуга, которая имеет свою стоимость.
-
 Как перенаправить несколько типов пользователей (студентов, учителей и администраторов) на их соответствующие действия в приложении Firebase?] red: Как перенаправить несколько типов пользователей на соответствующие действия понимание проблемы в огненном приложении, основанном авт...программирование Опубликовано в 2025-07-09
Как перенаправить несколько типов пользователей (студентов, учителей и администраторов) на их соответствующие действия в приложении Firebase?] red: Как перенаправить несколько типов пользователей на соответствующие действия понимание проблемы в огненном приложении, основанном авт...программирование Опубликовано в 2025-07-09 -
Разрешить исключение \\ "Ошибка строкового значения \\"разрешение исключения неверного строкового значения при вставке эмоджи при попытке вставить строку, содержащую символы эмоджи в базу данных mysq...программирование Опубликовано в 2025-07-09
-
Почему Microsoft Visual C ++ не может правильно реализовать двухфазной экземпляры?загадка «Сломанная» двухфазное матричное экземпляры в Microsoft Visual C Задача задачи: пользователи обычно выражают обеспокоенность Microso...программирование Опубликовано в 2025-07-09
-
Советы по плавающим изображениям в правой стороне дна и обертывание текстаПлавание изображения в правое внизу с текстом, обернутым вокруг в веб -дизайне, иногда желательно плавать изображение в нижний правый угол стр...программирование Опубликовано в 2025-07-09
-
Почему левые соединения выглядят как внутриполомы при фильтрации в предложении «Где в правом таблице»?Left Join Conundrum: часы ведьмы, когда он превращается во внутреннее соединение в сфере мастера базы данных, выполнение сложных поисков данных ...программирование Опубликовано в 2025-07-09
-
Python эффективный способ удаления HTML -тегов из текстаLearing HTML -теги в Python для нетронутого текстового представления манипулирование ответами HTML часто включает в себя извлечение соответств...программирование Опубликовано в 2025-07-09
-
Как проверить, есть ли у объекта конкретный атрибут в Python?Метод для определения атрибута объекта Этот запрос ищет метод для проверки присутствия конкретного атрибута в объекте. Рассмотрим следующий пр...программирование Опубликовано в 2025-07-09
-
Как я могу объединить таблицы базы данных с различным числом столбцов?объединенные таблицы с разными столбцами ] может столкнуться с проблемами при попытке объединить таблицы баз данных с разными столбцами. Просто...программирование Опубликовано в 2025-07-09
-
Как я могу эффективно прочитать большой файл в обратном порядке с помощью Python?Чтение файла в обратном порядке в Python Если вы работаете с большим файлом, и вам необходимо прочитать его содержимое с последней строки до п...программирование Опубликовано в 2025-07-09
-
Почему выражения Lambda требуют «окончательных» или «действительных окончательных» переменных в Java?] Lambda Expressions требуют «окончательного» или «эффективного окончательного» переменных ] Сообщение об ошибке «переменная, используемая в выр...программирование Опубликовано в 2025-07-09
-
Причины CodeIgniter подключиться к базе данных MySQL после перехода на MySQLIневозможно подключиться к базе данных MySQL: Сообщение об ошибке устранения неисправностей При попытке переключиться с драйвера MySQL к вашему...программирование Опубликовано в 2025-07-09
-
Как упростить анализ JSON в PHP для многомерных массивов?sacksing json с php пытаться анализировать данные JSON в PHP может быть сложной, особенно при работе с многомерными массивами. Чтобы упростить п...программирование Опубликовано в 2025-07-09
-
Почему Java не может создать общие массивы?enderic Mrue Creation Error Вопрос: ] при попытке создать массив общих классов, используя выражение: ArrayList [2]; public static ArrayLi...программирование Опубликовано в 2025-07-09
-
Как обойти блоки веб -сайтов с помощью запросов Python и фальшивых пользовательских агентов?Как смоделировать поведение браузера с помощью запросов Python и фальшивых пользовательских агентов библиотеки Python - это мощный инструмент ...программирование Опубликовано в 2025-07-09
-
Как правильно использовать как запросы с параметрами PDO?Использование подобных запросов в PDO При попытке реализовать подобные запросы в PDO, вы можете столкнуться с проблемами, подобными тем, котор...программирование Опубликовано в 2025-07-09















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









