 титульная страница > программирование > Оптимизация парсинга веб-страниц: парсинг данных аутентификации с помощью JSDOM
титульная страница > программирование > Оптимизация парсинга веб-страниц: парсинг данных аутентификации с помощью JSDOM
Оптимизация парсинга веб-страниц: парсинг данных аутентификации с помощью JSDOM
 Просматривать:633
Просматривать:633
Как разработчикам парсинга, нам иногда необходимо извлекать данные аутентификации, например временные ключи, для выполнения наших задач. Однако все не так просто. Обычно это сетевые запросы HTML или XHR, но иногда данные аутентификации вычисляются. В этом случае мы можем либо провести обратный инжиниринг вычислений, что занимает много времени для деобфускации сценариев, либо запустить JavaScript, который их вычисляет. Обычно мы используем браузер, но это дорого. Crawlee обеспечивает поддержку параллельного запуска парсера браузера и Cheerio Scraper, но это очень сложно и дорого с точки зрения использования вычислительных ресурсов. JSDOM помогает нам запускать JavaScript страницы, используя меньше ресурсов, чем браузер, и немного больше, чем Cheerio.
В этой статье будет обсуждаться новый подход, который мы используем в одном из наших актеров для получения данных аутентификации из креативного центра рекламы TikTok, генерируемых веб-приложениями браузера, без фактического запуска браузера, а вместо него с использованием JSDOM.
Анализ сайта
Когда вы посещаете этот URL:
https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pc/en
Вы увидите список хэштегов с их рейтингом в реальном времени, количеством публикаций, диаграммой тенденций, авторами и аналитикой. Вы также можете заметить, что мы можем фильтровать отрасль, устанавливать период времени и использовать флажок, чтобы отфильтровать, является ли тенденция новой для топ-100 или нет.
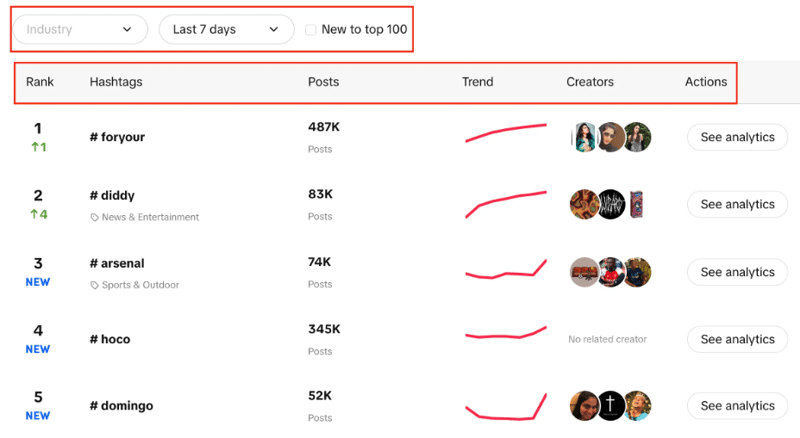
Наша цель — извлечь 100 лучших хэштегов из списка с помощью заданных фильтров.
Два возможных подхода — использовать CheerioCrawler, а второй — парсинг на основе браузера. Cheerio дает результаты быстрее, но не работает с веб-сайтами, созданными с помощью JavaScript.
Cheerio здесь не лучший вариант, поскольку Creative Center — это веб-приложение, а источником данных является API, поэтому мы можем получить только хэштеги, изначально присутствующие в структуре HTML, но не каждый из 100, как нам нужно.
Второй подход может заключаться в использовании таких библиотек, как Puppeteer, Playwright и т. д., для очистки данных в браузере, а также в использовании автоматизации для очистки всех хэштегов, но, учитывая предыдущий опыт, такая небольшая задача требует много времени.
Теперь мы разработали новый подход, чтобы сделать этот процесс намного лучше, чем сканирование в браузере, и очень близко к сканированию с помощью CheerioCrawler.
JSDOM-подход
Прежде чем углубиться в этот подход, я хотел бы выразить благодарность Алексею Удовыдченко, инженеру веб-автоматизации в Apify, за разработку этого подхода. Слава ему!
При таком подходе мы собираемся выполнять вызовы API https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list для получения необходимых данных.
Прежде чем вызывать этот API, нам понадобится несколько обязательных заголовков (данные аутентификации), поэтому сначала мы выполним вызов https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad /ru.
Мы начнем этот подход с создания функции, которая создаст для нас URL-адрес для вызова API, выполнит вызов и получит данные.
export const createStartUrls = (input) => {
const {
days = '7',
country = '',
resultsLimit = 100,
industry = '',
isNewToTop100,
} = input;
const filterBy = isNewToTop100 ? 'new_on_board' : '';
return [
{
url: `https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list?page=1&limit=50&period=${days}&country_code=${country}&filter_by=${filterBy}&sort_by=popular&industry_id=${industry}`,
headers: {
// required headers
},
userData: { resultsLimit },
},
];
};
В приведенной выше функции мы создаем начальный URL-адрес для вызова API, который включает в себя различные параметры, о которых мы говорили ранее. После создания URL-адреса в соответствии с параметрами он вызовет Creative_radar_api и получит все результаты.
Но это не сработает, пока мы не получим заголовки. Итак, давайте создадим функцию, которая сначала создаст сеанс, используя sessionPool и proxyConfiguration.
export const createSessionFunction = async (
sessionPool,
proxyConfiguration,
) => {
const proxyUrl = await proxyConfiguration.newUrl(Math.random().toString());
const url =
'https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en';
// need url with data to generate token
const response = await gotScraping({ url, proxyUrl });
const headers = await getApiUrlWithVerificationToken(
response.body.toString(),
url,
);
if (!headers) {
throw new Error(`Token generation blocked`);
}
log.info(`Generated API verification headers`, Object.values(headers));
return new Session({
userData: {
headers,
},
sessionPool,
});
};
В этой функции основная цель — вызвать https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en и получить взамен заголовки. Чтобы получить заголовки, мы используем функцию getApiUrlWithVerificationToken.
Прежде чем продолжить, я хочу упомянуть, что Crawlee изначально поддерживает JSDOM с помощью JSDOM Crawler. Он предоставляет основу для параллельного сканирования веб-страниц с использованием простых HTTP-запросов и реализации DOM jsdom. Он использует необработанные HTTP-запросы для загрузки веб-страниц, он очень быстр и эффективен в плане пропускной способности данных.
Давайте посмотрим, как мы собираемся создать функцию getApiUrlWithVerificationToken:
const getApiUrlWithVerificationToken = async (body, url) => {
log.info(`Getting API session`);
const virtualConsole = new VirtualConsole();
const { window } = new JSDOM(body, {
url,
contentType: 'text/html',
runScripts: 'dangerously',
resources: 'usable' || new CustomResourceLoader(),
// ^ 'usable' faster than custom and works without canvas
pretendToBeVisual: false,
virtualConsole,
});
virtualConsole.on('error', () => {
// ignore errors cause by fake XMLHttpRequest
});
const apiHeaderKeys = ['anonymous-user-id', 'timestamp', 'user-sign'];
const apiValues = {};
let retries = 10;
// api calls made outside of fetch, hack below is to get URL without actual call
window.XMLHttpRequest.prototype.setRequestHeader = (name, value) => {
if (apiHeaderKeys.includes(name)) {
apiValues[name] = value;
}
if (Object.values(apiValues).length === apiHeaderKeys.length) {
retries = 0;
}
};
window.XMLHttpRequest.prototype.open = (method, urlToOpen) => {
if (
['static', 'scontent'].find((x) =>
urlToOpen.startsWith(`https://${x}`),
)
)
log.debug('urlToOpen', urlToOpen);
};
do {
await sleep(4000);
retries--;
} while (retries > 0);
await window.close();
return apiValues;
};
В этой функции мы создаем виртуальную консоль, которая использует CustomResourceLoader для запуска фонового процесса и заменяет браузер JSDOM.
Для этого конкретного примера нам нужны три обязательных заголовка для вызова API: анонимный идентификатор пользователя, метка времени и подпись пользователя.
Используя XMLHttpRequest.prototype.setRequestHeader, мы проверяем, присутствуют ли упомянутые заголовки в ответе или нет. Если да, мы берем значение этих заголовков и повторяем попытки, пока не получим все заголовки.
Затем самая важная часть заключается в том, что мы используем XMLHttpRequest.prototype.open для извлечения данных аутентификации и совершения вызовов без фактического использования браузеров или раскрытия активности ботов.
В конце createSessionFunction возвращает сеанс с необходимыми заголовками.
Теперь переходя к нашему основному коду, мы будем использовать CheerioCrawler и prenavigationHooks для внедрения заголовков, которые мы получили из предыдущей функции, в requestHandler.
const crawler = new CheerioCrawler({
sessionPoolOptions: {
maxPoolSize: 1,
createSessionFunction: async (sessionPool) =>
createSessionFunction(sessionPool, proxyConfiguration),
},
preNavigationHooks: [
(crawlingContext) => {
const { request, session } = crawlingContext;
request.headers = {
...request.headers,
...session.userData?.headers,
};
},
],
proxyConfiguration,
});
Наконец, в обработчике запроса мы выполняем вызов, используя заголовки, и проверяем, сколько вызовов необходимо для получения всей постраничной обработки данных.
async requestHandler(context) {
const { log, request, json } = context;
const { userData } = request;
const { itemsCounter = 0, resultsLimit = 0 } = userData;
if (!json.data) {
throw new Error('BLOCKED');
}
const { data } = json;
const items = data.list;
const counter = itemsCounter items.length;
const dataItems = items.slice(
0,
resultsLimit && counter > resultsLimit
? resultsLimit - itemsCounter
: undefined,
);
await context.pushData(dataItems);
const {
pagination: { page, total },
} = data;
log.info(
`Scraped ${dataItems.length} results out of ${total} from search page ${page}`,
);
const isResultsLimitNotReached =
counter
Здесь важно отметить, что мы создаем этот код таким образом, чтобы мы могли выполнять любое количество вызовов API.
В этом конкретном примере мы выполнили только один запрос и один сеанс, но при необходимости вы можете сделать больше. Когда первый вызов API будет завершен, будет создан второй вызов API. Опять же, при необходимости вы можете сделать больше звонков, но мы остановились на двух.
Чтобы было понятнее, вот как выглядит поток кода:
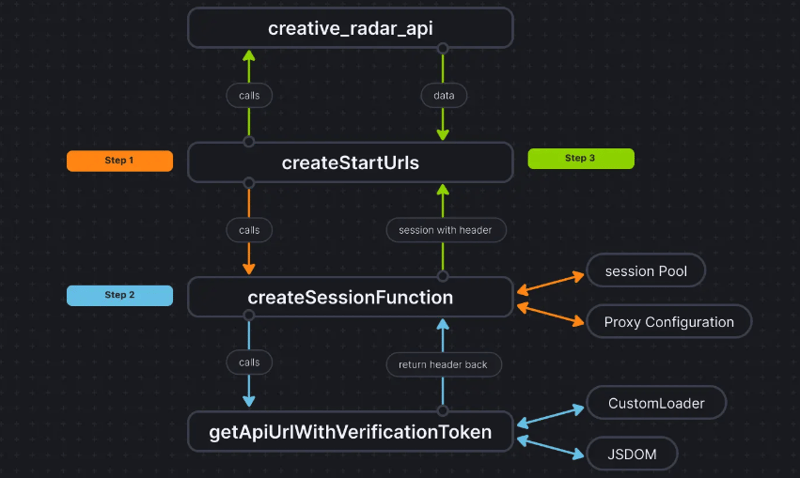
Заключение
Этот подход помогает нам получить третий способ извлечь данные аутентификации без фактического использования браузера и передать данные в CheerioCrawler. Это значительно повышает производительность и снижает требования к оперативной памяти на 50%, и хотя производительность парсинга на основе браузера в десять раз медленнее, чем у чистого Cheerio, JSDOM делает это всего в 3-4 раза медленнее, что делает его в 2-3 раза быстрее, чем браузерный на основе парсинга.
Кодовая база проекта уже загружена здесь. Код написан как актер Apify; вы можете узнать больше об этом здесь, но вы также можете запустить его без использования Apify SDK.
Если у вас есть какие-либо сомнения или вопросы по поводу этого подхода, свяжитесь с нами на нашем сервере Discord.
-
 Почему Microsoft Visual C ++ не может правильно реализовать двухфазной экземпляры?загадка «Сломанная» двухфазное матричное экземпляры в Microsoft Visual C Задача: пользователи обычно выражают обеспокоенность Microsoft Visu...программирование Опубликовано в 2025-04-09
Почему Microsoft Visual C ++ не может правильно реализовать двухфазной экземпляры?загадка «Сломанная» двухфазное матричное экземпляры в Microsoft Visual C Задача: пользователи обычно выражают обеспокоенность Microsoft Visu...программирование Опубликовано в 2025-04-09 -
Как я могу настроить оптимизацию компиляции в компиляторе GO?настройка оптимизации компиляции в GO Compiler процесс компиляции по умолчанию в GO следует за конкретной стратегией оптимизации. Однако польз...программирование Опубликовано в 2025-04-09
-
Существует ли разница в производительности между использованием зала и итератора для сбора сбора в Java?для каждого цикла Vs. iterator: эффективность в сборе Traversal введение при переселении коллекции в Java, выборе между использованием для...программирование Опубликовано в 2025-04-09
-
Как ограничить диапазон прокрутки элемента в родительском элементе динамического размера?реализация пределов высоты CSS для вертикальных элементов прокрутки В интерактивном интерфейсе, контроль над поведением прокрутки элементов яв...программирование Опубликовано в 2025-04-09
-
Можете ли вы использовать CSS для цветной консоли вывода в Chrome и Firefox?отображение цветов в консоли Javascript ] может ли использовать консоль Chrome для отображения цветного текста, такого как красный для ошибок, ...программирование Опубликовано в 2025-04-09
-
Почему `body {margin: 0; } `Всегда удалять верхний край в CSS?адресация поля тела в CSS для начинающих веб -разработчиков, удаление поля элемента тела может быть запутанной задачей. Часто предоставляемый ...программирование Опубликовано в 2025-04-09
-
Как эффективно преобразовать часовые пояса в PHP?эффективное преобразование часового пояса в php В PHP, обработка часовых поясов может быть простой задачей. Это руководство предоставит метод пр...программирование Опубликовано в 2025-04-09
-
Eval () против AST.Literal_EVAL (): какая функция Python безопаснее для пользовательского ввода?взвешивание eval () и ast.literal_eval () в Python Security при обращении с вводом пользователя, это необходимо определить определение безопас...программирование Опубликовано в 2025-04-09
-
Как объединить данные из трех таблиц MySQL в новую таблицу?mySQL: Creating a New Table from Data and Columns of Three TablesQuestion:How can I create a new table that combines selected data from three existing...программирование Опубликовано в 2025-04-09
-
Как отправить необработанный запрос по почте с Curl в PHP?Как отправить необработанный запрос Post, используя Curl в php в PHP, Curl является популярной библиотекой для отправки HTTP -запросов. Эта ст...программирование Опубликовано в 2025-04-09
-
Как я могу эффективно создавать словаря, используя понимание Python?Python Dictionary понимание в Python, словарь понимает, предлагает краткий способ создания новых словарей. Хотя они похожи на понимание списков,...программирование Опубликовано в 2025-04-09
-
Можно ли сложить несколько липких элементов друг на друга в чистых CSS?возможно ли иметь несколько липких элементов, сложенных друг на друга в чистом CSS? Здесь: https://webthemez.com/demo/sticky-multi-heand-scroll/...программирование Опубликовано в 2025-04-09
-
Как извлечь случайный элемент из массива в PHP?случайный выбор из массива в php, получение случайного элемента из массива может быть выполнено с легкостью. Рассмотрим следующий массив: ] $ite...программирование Опубликовано в 2025-04-09
-
Почему выполнение JavaScript прекращается при использовании кнопки Firefox Back?Проблема истории навигации: Javascript перестает выполнять после использования кнопки Firefox Back пользователи Firefox могут столкнуться с пр...программирование Опубликовано в 2025-04-09
-
Как правильно отобразить текущую дату и время в формате «DD/MM/yyyy HH: MM: Ss.SS» в Java?Как отобразить текущую дату и время в «dd/mm/yyyy hh: mm: ss.ss" format в предоставленном коде Java, выпуск с датой и временем в желании ...программирование Опубликовано в 2025-04-09















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









