 титульная страница > программирование > Освоение сегментации изображений: как традиционные методы по-прежнему актуальны в эпоху цифровых технологий
титульная страница > программирование > Освоение сегментации изображений: как традиционные методы по-прежнему актуальны в эпоху цифровых технологий
Освоение сегментации изображений: как традиционные методы по-прежнему актуальны в эпоху цифровых технологий
 Просматривать:453
Просматривать:453
Введение
Сегментация изображения, одна из самых основных процедур компьютерного зрения, позволяет системе разлагать и анализировать различные области изображения. Независимо от того, имеете ли вы дело с распознаванием объектов, медицинской визуализацией или автономным вождением, сегментация — это то, что разбивает изображения на значимые части.
Хотя модели глубокого обучения продолжают становиться все более популярными для решения этой задачи, традиционные методы цифровой обработки изображений по-прежнему остаются мощными и практичными. Подходы, рассматриваемые в этом посте, включают пороговое определение, обнаружение границ, региональную кластеризацию и реализацию общепризнанного набора данных для анализа изображений клеток — MIVIA HEp-2 Image Dataset.
Набор данных изображений MIVIA HEp-2
Набор изображений MIVIA HEp-2 представляет собой набор изображений клеток, используемых для анализа структуры антинуклеарных антител (ANA) в клетках HEp-2. Он состоит из 2D-изображений, полученных с помощью флуоресцентной микроскопии. Это делает его очень подходящим для задач сегментации, особенно тех, которые связаны с анализом медицинских изображений, где наиболее важно обнаружение клеточных областей.
Теперь давайте перейдем к методам сегментации, используемым для обработки этих изображений, и сравним их производительность на основе оценок F1.
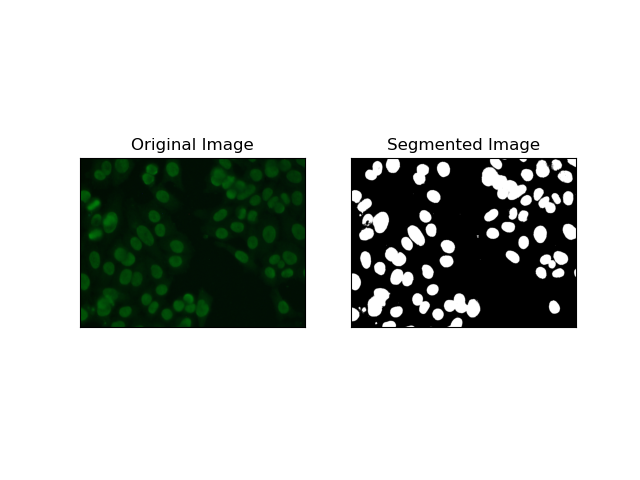
1. Пороговая сегментация
Пороговое определение — это процесс, при котором изображения в оттенках серого преобразуются в двоичные изображения на основе интенсивности пикселей. В наборе данных MIVIA HEp-2 этот процесс полезен при выделении клеток из фона. Он прост и эффективен на относительно большом уровне, особенно с помощью метода Оцу, поскольку он самостоятельно вычисляет оптимальный порог.
Метод Оцу — это метод автоматического определения порога, в котором он пытается найти лучшее пороговое значение, чтобы получить минимальную внутриклассовую дисперсию, тем самым разделяя два класса: передний план (ячейки) и фон. Метод проверяет гистограмму изображения и вычисляет идеальный порог, при котором сумма отклонений интенсивности пикселей в каждом классе минимизируется.
# Thresholding Segmentation
def thresholding(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY cv.THRESH_OTSU)
return thresh
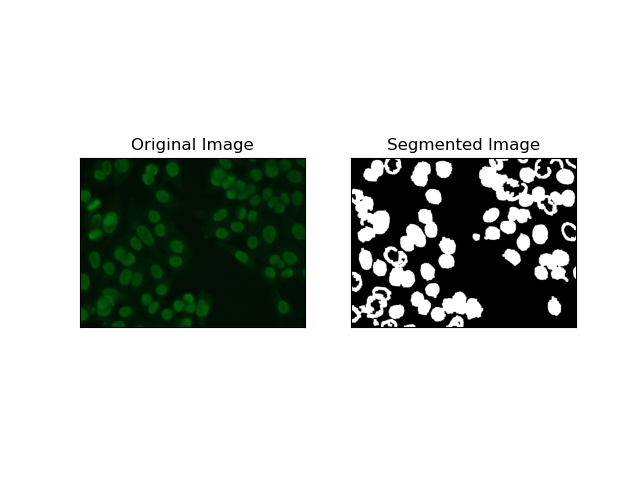
2. Сегментация обнаружения краев
Обнаружение краев относится к определению границ объектов или областей, таких как края ячеек в наборе данных MIVIA HEp-2. Из многих доступных методов обнаружения резких изменений интенсивности Canny Edge Detector является лучшим и, следовательно, наиболее подходящим методом для обнаружения клеточных границ.
Canny Edge Detector — это многоэтапный алгоритм, который может обнаруживать края путем обнаружения областей с сильными градиентами интенсивности. Процесс включает в себя сглаживание с помощью фильтра Гаусса, расчет градиентов интенсивности, применение немаксимального подавления для устранения ложных откликов и заключительную операцию двойного порога для сохранения только заметных краев.
# Edge Detection Segmentation
def edge_detection(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Gaussian blur
gray = cv.GaussianBlur(gray, (3, 3), 0)
# Calculate lower and upper thresholds for Canny edge detection
sigma = 0.33
v = np.median(gray)
lower = int(max(0, (1.0 - sigma) * v))
upper = int(min(255, (1.0 sigma) * v))
# Apply Canny edge detection
edges = cv.Canny(gray, lower, upper)
# Dilate the edges to fill gaps
kernel = np.ones((5, 5), np.uint8)
dilated_edges = cv.dilate(edges, kernel, iterations=2)
# Clean the edges using morphological opening
cleaned_edges = cv.morphologyEx(dilated_edges, cv.MORPH_OPEN, kernel, iterations=1)
# Find connected components and filter out small components
num_labels, labels, stats, _ = cv.connectedComponentsWithStats(
cleaned_edges, connectivity=8
)
min_size = 500
filtered_mask = np.zeros_like(cleaned_edges)
for i in range(1, num_labels):
if stats[i, cv.CC_STAT_AREA] >= min_size:
filtered_mask[labels == i] = 255
# Find contours of the filtered mask
contours, _ = cv.findContours(
filtered_mask, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE
)
# Create a filled mask using the contours
filled_mask = np.zeros_like(gray)
cv.drawContours(filled_mask, contours, -1, (255), thickness=cv.FILLED)
# Perform morphological closing to fill holes
final_filled_image = cv.morphologyEx(
filled_mask, cv.MORPH_CLOSE, kernel, iterations=2
)
# Dilate the final filled image to smooth the edges
final_filled_image = cv.dilate(final_filled_image, kernel, iterations=1)
return final_filled_image
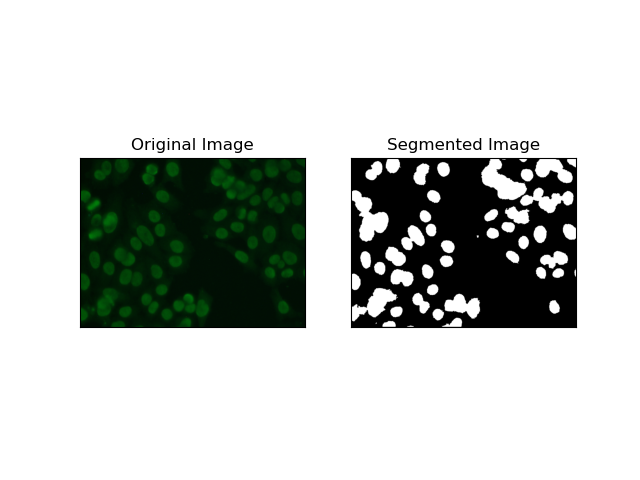
3. Сегментация по регионам
Сегментация на основе регионов группирует похожие пиксели в регионы в зависимости от определенных критериев, таких как интенсивность или цвет. Метод сегментации водораздела можно использовать для сегментации изображений клеток HEp-2, чтобы иметь возможность обнаруживать те области, которые представляют клетки; он рассматривает интенсивность пикселей как топографическую поверхность и выделяет различающиеся области.
Сегментация водораздела рассматривает интенсивность пикселей как топографическую поверхность. Алгоритм идентифицирует «бассейны», в которых он определяет локальные минимумы, а затем постепенно заполняет эти бассейны, чтобы увеличить отдельные области. Этот метод весьма полезен, когда нужно разделить соприкасающиеся объекты, как в случае с клетками на микроскопических изображениях, но он может быть чувствителен к шуму. Этим процессом можно управлять с помощью маркеров, и чрезмерную сегментацию часто можно уменьшить.
# Region-Based Segmentation
def region_based(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV cv.THRESH_OTSU)
# Apply morphological opening to remove noise
kernel = np.ones((3, 3), np.uint8)
opening = cv.morphologyEx(thresh, cv.MORPH_OPEN, kernel, iterations=2)
# Dilate the opening to get the background
sure_bg = cv.dilate(opening, kernel, iterations=3)
# Calculate the distance transform
dist_transform = cv.distanceTransform(opening, cv.DIST_L2, 5)
# Threshold the distance transform to get the foreground
_, sure_fg = cv.threshold(dist_transform, 0.2 * dist_transform.max(), 255, 0)
sure_fg = np.uint8(sure_fg)
# Find the unknown region
unknown = cv.subtract(sure_bg, sure_fg)
# Label the markers for watershed algorithm
_, markers = cv.connectedComponents(sure_fg)
markers = markers 1
markers[unknown == 255] = 0
# Apply watershed algorithm
markers = cv.watershed(img, markers)
# Create a mask for the segmented region
mask = np.zeros_like(gray, dtype=np.uint8)
mask[markers == 1] = 255
return mask
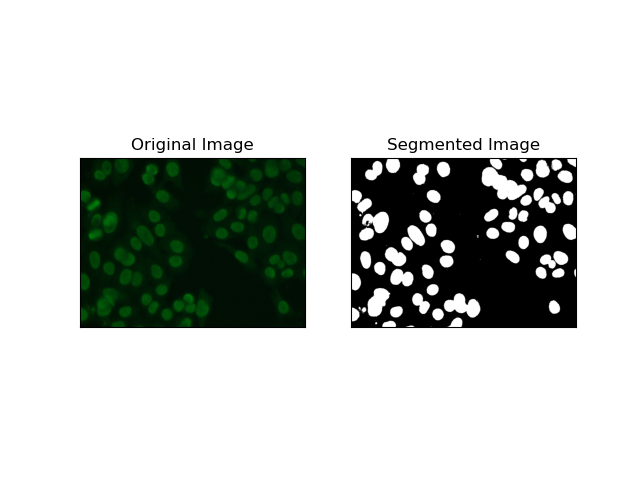
4. Сегментация на основе кластеризации
Методы кластеризации, такие как K-Means имеют тенденцию группировать пиксели в похожие кластеры, что отлично работает при необходимости сегментировать ячейки в разноцветных или сложных средах, как это видно на изображениях клеток HEp-2. По сути, это могут представлять разные классы, например клеточную область или фон.
K-means — это алгоритм обучения без учителя для кластеризации изображений на основе пиксельного сходства цвета или интенсивности. Алгоритм случайным образом выбирает K центроидов, присваивает каждый пиксель ближайшему центроиду и итеративно обновляет центроид, пока он не сойдется. Это особенно эффективно при сегментации изображения, имеющего несколько областей интереса, сильно отличающихся друг от друга.
# Clustering Segmentation
def clustering(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Reshape the image
Z = gray.reshape((-1, 3))
Z = np.float32(Z)
# Define the criteria for k-means clustering
criteria = (cv.TERM_CRITERIA_EPS cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# Set the number of clusters
K = 2
# Perform k-means clustering
_, label, center = cv.kmeans(Z, K, None, criteria, 10, cv.KMEANS_RANDOM_CENTERS)
# Convert the center values to uint8
center = np.uint8(center)
# Reshape the result
res = center[label.flatten()]
res = res.reshape((gray.shape))
# Apply thresholding to the result
_, res = cv.threshold(res, 0, 255, cv.THRESH_BINARY cv.THRESH_OTSU)
return res
Оценка методов с использованием оценок F1
Оценка F1 — это показатель, который сочетает в себе точность и полноту для сравнения прогнозируемого изображения сегментации с реальным изображением. Это гармоническое среднее значение точности и полноты, которое полезно в случаях высокого дисбаланса данных, например, в наборах данных медицинских изображений.
Мы рассчитали оценку F1 для каждого метода сегментации, объединив как основную истину, так и сегментированное изображение, и вычислив взвешенную оценку F1.
def calculate_f1_score(ground_image, segmented_image):
ground_image = ground_image.flatten()
segmented_image = segmented_image.flatten()
return f1_score(ground_image, segmented_image, average="weighted")
Затем мы визуализировали оценки F1 различных методов с помощью простой гистограммы:
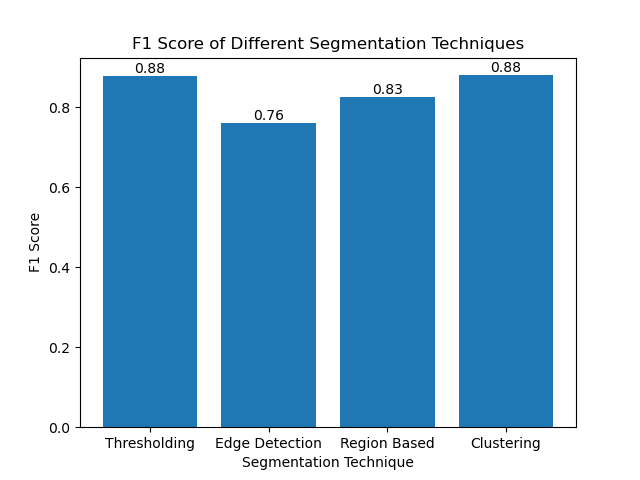
Заключение
Хотя в последнее время появляется множество подходов к сегментации изображений, традиционные методы сегментации, такие как определение порогов, обнаружение границ, методы на основе областей и кластеризация, могут быть очень полезны при применении к таким наборам данных, как набор данных изображений MIVIA HEp-2.
]Каждый метод имеет свои сильные стороны:
- Пороговое значение хорошо подходит для простой двоичной сегментации.
- Обнаружение границ — идеальный метод обнаружения границ.
- Сегментация по регионам очень полезна для отделения связанных компонентов от их соседей.
- Методы кластеризации хорошо подходят для задач сегментации по нескольким регионам.
Оценивая эти методы с использованием оценок F1, мы понимаем недостатки каждой из этих моделей. Эти методы, возможно, не такие сложные, как те, которые разрабатываются в новейших моделях глубокого обучения, но они по-прежнему быстрые, интерпретируемые и пригодные для использования в широком спектре приложений.
Спасибо, что читаете! Я надеюсь, что это исследование традиционных методов сегментации изображений вдохновит ваш следующий проект. Не стесняйтесь делиться своими мыслями и опытом в комментариях ниже!
-
 Как я могу эффективно заменить несколько подстроков в строке Java?заменить несколько подстроков в строку эффективно в Java , когда сталкивается с необходимостью заменить несколько подстроков в строке, это зама...программирование Опубликовано в 2025-04-05
Как я могу эффективно заменить несколько подстроков в строке Java?заменить несколько подстроков в строку эффективно в Java , когда сталкивается с необходимостью заменить несколько подстроков в строке, это зама...программирование Опубликовано в 2025-04-05 -
\ "В то время как (1) против (;;): Оптимизация компилятора исключает различия в производительности? \"while (1) vs. for (;;;): существует ли разница в скорости? ] Вопрос: . Использование (1) вместо (;) петли? Компиляторы: ] perl: как (1)...программирование Опубликовано в 2025-04-05
-
Как я могу настроить оптимизацию компиляции в компиляторе GO?настройка оптимизации компиляции в GO Compiler процесс компиляции по умолчанию в GO следует за конкретной стратегией оптимизации. Однако польз...программирование Опубликовано в 2025-04-05
-
Как преодолеть ограничения переопределения функций PHP?преодоление ограничений переосмысления функции PHP в PHP, определение функции с одним и тем же именем несколько раз-нет-нет. Попытка сделать э...программирование Опубликовано в 2025-04-05
-
Как захватить и транслировать Stdout в режиме реального времени для выполнения команды Chatbot?захватывание Stdout в режиме реального времени из выполнения команды В сфере разработки чат -ботов, способных выполнять команды, является общи...программирование Опубликовано в 2025-04-05
-
Как проверить, есть ли у объекта конкретный атрибут в Python?Метод для определения атрибута объекта Этот запрос ищет метод для проверки присутствия конкретного атрибута в объекте. Рассмотрим следующий пр...программирование Опубликовано в 2025-04-05
-
Как реализовать универсальную хэш -функцию для кортежей в неупорядоченных коллекциях?generic hash function для кортежей в неупорядоченных коллекциях . Чтобы исправить это, один подход - это вручную определить функцию HASH для к...программирование Опубликовано в 2025-04-05
-
Как я могу эффективно генерировать удобные для URL слизняки из строк Unicode в PHP?создание функции для эффективной генерации Slug Создание слизняков, упрощенные представления строк Unicode, используемые в URL, может быть сло...программирование Опубликовано в 2025-04-05
-
Python Read File CSV UnicoDedeCodeError Ultimate Solutionошибка декодирования Unicod Не могу декодировать байты В позиции 2-3: усеченная \ uxxxxxxxxxxxx эта ошибка возникает, когда путь к файлу CSV со...программирование Опубликовано в 2025-04-05
-
Как разрешить \ "Отказалось загрузить сценарий ... \" Ошибки из -за политики безопасности контента Android?Представление Mystery: Directive Policive Policive Content Security столкновение с загадочной ошибкой »отказалась загрузить скрипт ...» при ра...программирование Опубликовано в 2025-04-05
-
Как я могу поддерживать пользовательский рендеринг JTable Cell после редактирования ячейки?поддержание рендеринга Jtable Cell после редактирования ячейки в jtable, реализация пользовательских элементов рендеринга ячейки и редактирова...программирование Опубликовано в 2025-04-05
-
Почему Microsoft Visual C ++ не может правильно реализовать двухфазной экземпляры?загадка «Сломанная» двухфазное матричное экземпляры в Microsoft Visual C Задача: пользователи обычно выражают обеспокоенность Microsoft Visu...программирование Опубликовано в 2025-04-05
-
Как правильно отобразить текущую дату и время в формате «DD/MM/yyyy HH: MM: Ss.SS» в Java?Как отобразить текущую дату и время в «dd/mm/yyyy hh: mm: ss.ss" format в предоставленном коде Java, выпуск с датой и временем в желании ...программирование Опубликовано в 2025-04-05
-
Как я могу выполнить несколько операторов SQL в одном запросе с помощью Node-Mysql?Поддержка запросов с несколькими Statement в Node-Mysql в Node.js возникает вопрос, когда выполняется несколько SQL-записей в одном запросе, и...программирование Опубликовано в 2025-04-05
-
Почему ввод запроса в POST Захват в PHP, несмотря на действительный код?addressing post запрос неисправность в php в представленном фрагменте кода: action='' intement. Вход из нагламента на нажим. Однако выход ...программирование Опубликовано в 2025-04-05















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









