
import streamlit as stimport numpy as npimport pandas as pdimport joblib
stremlit — это библиотека Python, которая позволяет легко создавать и публиковать пользовательские веб-приложения для проектов по машинному обучению и науке о данных.
numpy — фундаментальная библиотека Python для численных вычислений. Он обеспечивает поддержку больших многомерных массивов и матриц, а также набор математических функций для эффективной работы с этими массивами.
data = { \\\"island\\\": island, \\\"bill_length_mm\\\": bill_length_mm, \\\"bill_depth_mm\\\": bill_depth_mm, \\\"flipper_length_mm\\\": flipper_length_mm, \\\"body_mass_g\\\": body_mass_g, \\\"sex\\\": sex,}input_df = pd.DataFrame(data, index=[0])encode = [\\\"island\\\", \\\"sex\\\"]input_encoded_df = pd.get_dummies(input_df, prefix=encode)Входные значения извлекаются из формы ввода, созданной Stremlit, а категориальные переменные кодируются с использованием тех же правил, что и при создании модели. Обратите внимание, что порядок каждых данных должен быть таким же, как при создании модели. Если порядок другой, при выполнении прогноза с использованием модели произойдет ошибка.
clf = joblib.load(\\\"penguin_classifier_model.pkl\\\")
\\\"penguin_classifier_model.pkl\\\" — это файл, в котором хранится ранее сохраненная модель. Этот файл содержит обученный RandomForestClassifier в двоичном формате. Запуск этого кода загружает модель в clf, что позволяет использовать ее для прогнозов и оценок новых данных.
prediction = clf.predict(input_encoded_df)prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): использует обученную модель для прогнозирования класса для новых закодированных входных данных, сохраняя результат в прогнозировании.
clf.predict_proba(input_encoded_df): вычисляет вероятность для каждого класса, сохраняя результаты в Predict_proba.
Вы можете опубликовать разработанное вами приложение в Интернете, зайдя в облако сообщества Stremlit (https://streamlit.io/cloud) и указав URL-адрес репозитория GitHub.

Работа @allison_horst (https://github.com/allisonhorst)
Модель обучена с использованием набора данных Palmer Penguins, широко известного набора данных для отработки методов машинного обучения. Этот набор данных предоставляет информацию о трех видах пингвинов (Адели, Чинстрап и Генту) с архипелага Палмера в Антарктиде. Ключевые особенности:
Этот набор данных взят из Kaggle, и доступ к нему можно получить здесь. Разнообразие признаков делает его отличным выбором для построения модели классификации и понимания важности каждого признака для прогнозирования видов.
","image":"http://www.luping.net/uploads/20241006/17282217676702924713227.png","datePublished":"2024-11-02T21:56:21+08:00","dateModified":"2024-11-02T21:56:21+08:00","author":{"@type":"Person","name":"luping.net","url":"https://www.luping.net/articlelist/0_1.html"}} титульная страница > программирование > Развертывание модели машинного обучения в виде веб-приложения с использованием Streamlit
титульная страница > программирование > Развертывание модели машинного обучения в виде веб-приложения с использованием Streamlit
 Просматривать:221
Просматривать:221
Модель машинного обучения — это, по сути, набор правил или механизмов, используемых для прогнозирования или поиска закономерностей в данных. Проще говоря (и не боясь упрощений), линия тренда, рассчитанная с использованием метода наименьших квадратов в Excel, также является моделью. Однако модели, используемые в реальных приложениях, не так просты — они часто включают в себя более сложные уравнения и алгоритмы, а не только простые уравнения.
В этом посте я собираюсь начать с создания очень простой модели машинного обучения и выпустить ее в виде очень простого веб-приложения, чтобы получить представление о процессе.
Здесь я сосредоточусь только на процессе, а не на самой модели машинного обучения. Кроме того, я буду использовать Streamlit и Streamlit Community Cloud, чтобы легко выпускать веб-приложения Python.
Используя scikit-learn, популярную библиотеку Python для машинного обучения, вы можете быстро обучать данные и создавать модели с помощью всего нескольких строк кода для решения простых задач. Затем модель можно сохранить как файл многократного использования с помощью joblib. Эту сохраненную модель можно импортировать/загрузить как обычную библиотеку Python в веб-приложении, что позволяет приложению делать прогнозы с использованием обученной модели!
URL приложения: https://yh-machine-learning.streamlit.app/
GitHub: https://github.com/yoshan0921/yh-machine-learning.git
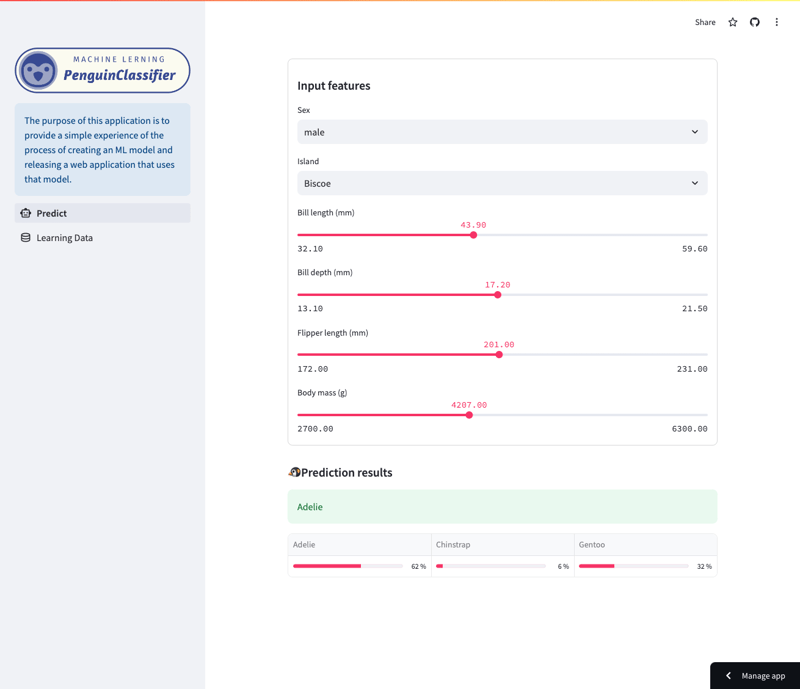
Это приложение позволяет вам проверять прогнозы, сделанные с помощью случайной модели леса, обученной на наборе данных Palmer Penguins. (Более подробную информацию о данных обучения см. в конце этой статьи.)
В частности, модель предсказывает виды пингвинов на основе множества характеристик, включая вид, остров, длину клюва, длину ласт, размер тела и пол. Пользователи могут перемещаться по приложению, чтобы увидеть, как различные функции влияют на прогнозы модели.
Экран прогнозов
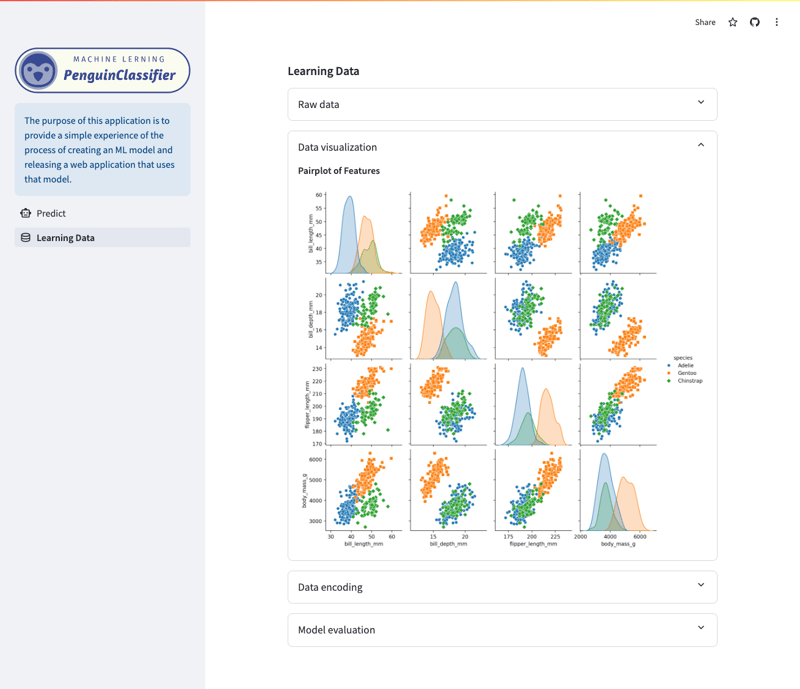
Экран обучающих данных/визуализации
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import joblib
pandas — это библиотека Python, специализирующаяся на манипулировании и анализе данных. Он поддерживает загрузку, предварительную обработку и структурирование данных с использованием DataFrames, а также подготовку данных для моделей машинного обучения.
sklearn — это комплексная библиотека Python для машинного обучения, предоставляющая инструменты для обучения и оценки. В этом посте я построю модель, используя метод обучения под названием «Случайный лес».
joblib — это библиотека Python, которая помогает очень эффективно сохранять и загружать объекты Python, такие как модели машинного обучения.
df = pd.read_csv("./dataset/penguins_cleaned.csv")
X_raw = df.drop("species", axis=1)
y_raw = df.species
Загрузите набор данных (обучающие данные) и разделите его на функции (X) и целевые переменные (y).
encode = ["island", "sex"]
X_encoded = pd.get_dummies(X_raw, columns=encode)
target_mapper = {"Adelie": 0, "Chinstrap": 1, "Gentoo": 2}
y_encoded = y_raw.apply(lambda x: target_mapper[x])
Категорийные переменные преобразуются в числовой формат с использованием горячего кодирования (X_encoded). Например, если «остров» содержит категории «Биско», «Мечта» и «Торгерсен», для каждой создается новый столбец (остров_Биско, остров_Мечта, остров_Торгерсен). То же самое делается и с сексом. Если исходные данные — «Биско», столбец Island_Biscoe будет установлен в 1, а остальные — в 0.
Вид целевой переменной отображается в числовые значения (y_encoded).
x_train, x_test, y_train, y_test = train_test_split(
X_encoded, y_encoded, test_size=0.3, random_state=1
)
Чтобы оценить модель, необходимо измерить ее производительность на данных, не используемых для обучения. 7:3 широко используется в качестве общей практики в машинном обучении.
clf = RandomForestClassifier() clf.fit(x_train, y_train)
Для обучения модели используется метод подгонки.
x_train представляет данные обучения для независимых переменных, а y_train представляет целевые переменные.
При вызове этого метода модель, обученная на основе обучающих данных, сохраняется в clf.
joblib.dump(clf, "penguin_classifier_model.pkl")
joblib.dump() — это функция для сохранения объектов Python в двоичном формате. Сохранив модель в этом формате, ее можно загрузить из файла и использовать как есть, без необходимости повторного обучения.
import streamlit as st import numpy as np import pandas as pd import joblib
stremlit — это библиотека Python, которая позволяет легко создавать и публиковать пользовательские веб-приложения для проектов по машинному обучению и науке о данных.
numpy — фундаментальная библиотека Python для численных вычислений. Он обеспечивает поддержку больших многомерных массивов и матриц, а также набор математических функций для эффективной работы с этими массивами.
data = {
"island": island,
"bill_length_mm": bill_length_mm,
"bill_depth_mm": bill_depth_mm,
"flipper_length_mm": flipper_length_mm,
"body_mass_g": body_mass_g,
"sex": sex,
}
input_df = pd.DataFrame(data, index=[0])
encode = ["island", "sex"]
input_encoded_df = pd.get_dummies(input_df, prefix=encode)
Входные значения извлекаются из формы ввода, созданной Stremlit, а категориальные переменные кодируются с использованием тех же правил, что и при создании модели. Обратите внимание, что порядок каждых данных должен быть таким же, как при создании модели. Если порядок другой, при выполнении прогноза с использованием модели произойдет ошибка.
clf = joblib.load("penguin_classifier_model.pkl")
"penguin_classifier_model.pkl" — это файл, в котором хранится ранее сохраненная модель. Этот файл содержит обученный RandomForestClassifier в двоичном формате. Запуск этого кода загружает модель в clf, что позволяет использовать ее для прогнозов и оценок новых данных.
prediction = clf.predict(input_encoded_df) prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): использует обученную модель для прогнозирования класса для новых закодированных входных данных, сохраняя результат в прогнозировании.
clf.predict_proba(input_encoded_df): вычисляет вероятность для каждого класса, сохраняя результаты в Predict_proba.
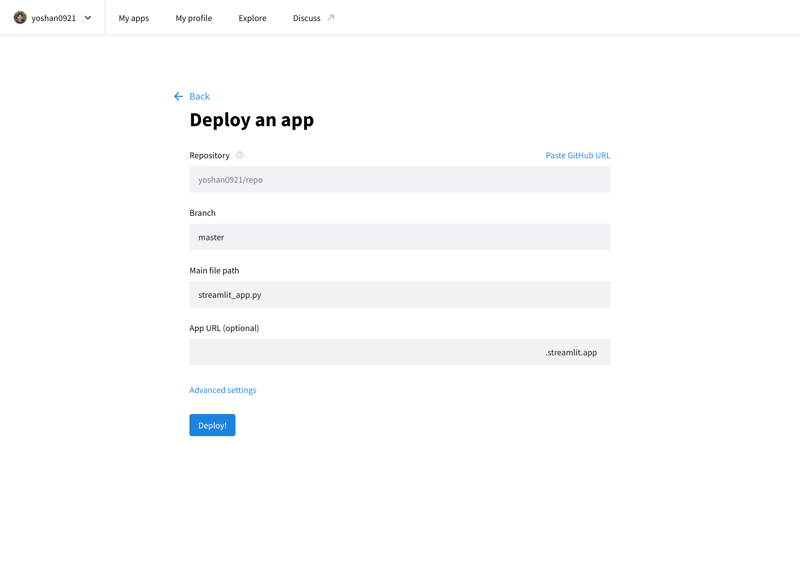
Вы можете опубликовать разработанное вами приложение в Интернете, зайдя в облако сообщества Stremlit (https://streamlit.io/cloud) и указав URL-адрес репозитория GitHub.

Работа @allison_horst (https://github.com/allisonhorst)
Модель обучена с использованием набора данных Palmer Penguins, широко известного набора данных для отработки методов машинного обучения. Этот набор данных предоставляет информацию о трех видах пингвинов (Адели, Чинстрап и Генту) с архипелага Палмера в Антарктиде. Ключевые особенности:
Этот набор данных взят из Kaggle, и доступ к нему можно получить здесь. Разнообразие признаков делает его отличным выбором для построения модели классификации и понимания важности каждого признака для прогнозирования видов.

























Отказ от ответственности: Все предоставленные ресурсы частично взяты из Интернета. В случае нарушения ваших авторских прав или других прав и интересов, пожалуйста, объясните подробные причины и предоставьте доказательства авторских прав или прав и интересов, а затем отправьте их по электронной почте: [email protected]. Мы сделаем это за вас как можно скорее.
Copyright© 2022 湘ICP备2022001581号-3