 титульная страница > ИИ > За пределами магистратуры: вот почему модели на малом языке — будущее искусственного интеллекта
титульная страница > ИИ > За пределами магистратуры: вот почему модели на малом языке — будущее искусственного интеллекта
За пределами магистратуры: вот почему модели на малом языке — будущее искусственного интеллекта
 Просматривать:585
Просматривать:585
Большие языковые модели (LLM) появились на сцене с выпуском ChatGPT от Open AI. С тех пор несколько компаний также запустили свои программы LLM, но сейчас все больше компаний склоняются к моделям малого языка (SLM).
SLM набирает обороты, но что это такое и чем они отличаются от LLM?
Что такое модель малого языка?
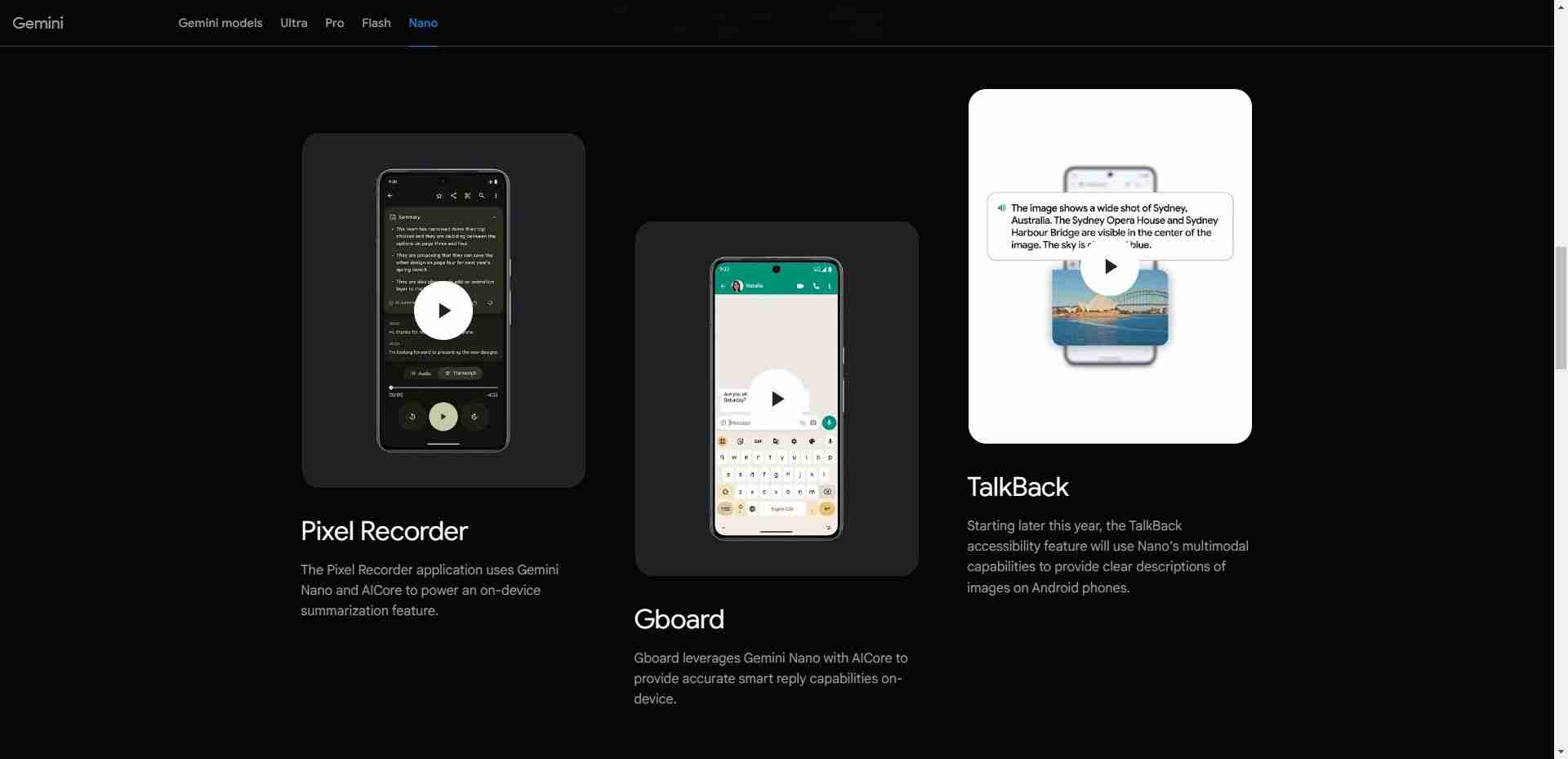
Маленькая языковая модель (SLM) — это тип модели искусственного интеллекта с меньшим количеством параметров (подумайте об этом как о значении модели, полученной во время обучения). Как и их более крупные аналоги, SLM могут генерировать текст и выполнять другие задачи. Однако SLM используют меньше наборов данных для обучения, имеют меньше параметров и требуют меньших вычислительных мощностей для обучения и запуска. у которых нет такого высокопроизводительного оборудования, как мобильные устройства. Например, Nano от Google — это SLM для мобильных устройств, созданный с нуля и работающий на мобильных устройствах. По словам компании, из-за своего небольшого размера Nano может работать локально с подключением к сети или без него.
Помимо Nano, в сфере искусственного интеллекта существует множество других SLM от ведущих и перспективных компаний. Некоторые популярные SLM включают Phi-3 от Microsoft, GPT-4o mini от OpenAI, Claude 3 Haiku от Anthropic, Llama 3 от Meta и Mixtral 8x7B от Mistral AI.
Также доступны и другие варианты, которые вы можете принять за LLM, но они УУЗР. Это особенно верно, учитывая, что большинство компаний используют мультимодельный подход, выпуская более одной языковой модели в своем портфолио, предлагая как LLM, так и SLM. Одним из примеров является GPT-4, который имеет различные модели, в том числе GPT-4, GPT-4o (Omni) и GPT-4o mini.
Малые языковые модели и большие языковые модели
Обсуждая SLM, мы не можем игнорировать их крупных аналогов: LLM. Ключевое различие между SLM и LLM заключается в размере модели, который измеряется с точки зрения параметров.
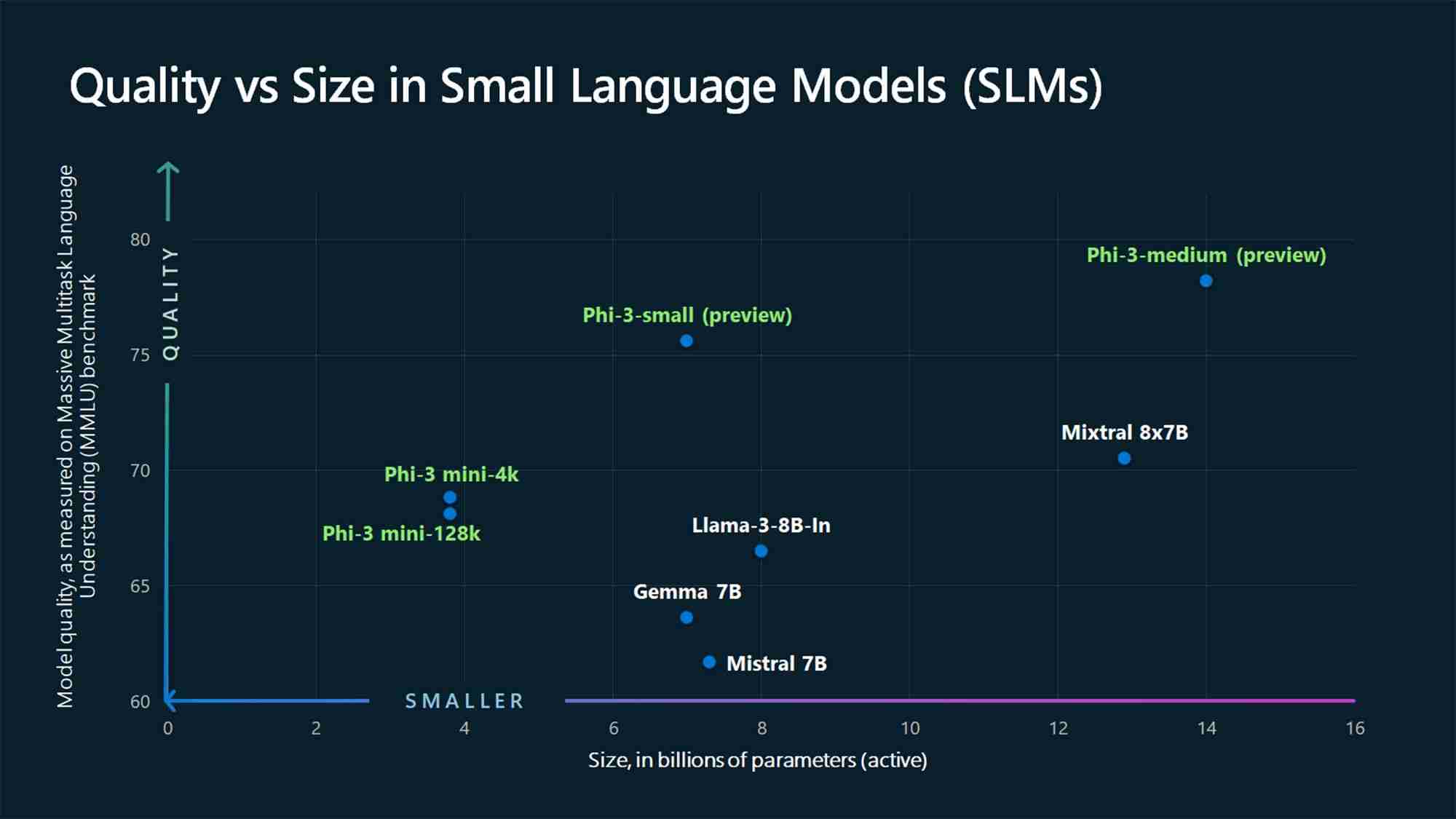
На момент написания этой статьи в отрасли искусственного интеллекта не существует единого мнения относительно максимального количества параметров, которые модель не должна использовать. превышает минимальное количество, чтобы считаться SLM, или минимальное количество, необходимое для того, чтобы считаться LLM. Однако SLM обычно имеют от миллионов до нескольких миллиардов параметров, а LLM — больше, достигая триллионов.
Например, GPT-3, выпущенный в 2020 году, имеет 175 миллиардов параметров (а По слухам, модель GPT-4 имеет около 1,76 триллиона), тогда как SLM-модули Microsoft Phi-3-mini, Phi-3-small и Phi-3-medium 2024 года измеряют 3,8, 7 и 14 миллиардов параметров соответственно.
Другим фактором, отличающим SLM от LLM, является объем данных, используемых для обучения. SLM обучаются на меньших объемах данных, тогда как LLM используют большие наборы данных. Это различие также влияет на способность модели решать сложные задачи.
Из-за больших объемов данных, используемых при обучении, LLM лучше подходят для решения различных типов сложных задач, требующих продвинутого рассуждения, тогда как SLM лучше подходят для более простых задачи. В отличие от LLM, SLM используют меньше обучающих данных, но используемые данные должны быть более высокого качества, чтобы реализовать многие возможности LLM в крошечном пакете.
Почему модели на малом языке — это будущее
В большинстве случаев использования SLM имеют больше шансов стать основными моделями, используемыми компаниями и потребителями для выполнения широкого спектра задач. Конечно, у LLM есть свои преимущества и они больше подходят для определенных случаев использования, например для решения сложных задач. Тем не менее, SLM — это будущее для большинства случаев использования по следующим причинам.
1. Более низкие затраты на обучение и обслуживание
SLM требует меньше данных для обучения, чем LLM, что делает их наиболее жизнеспособный вариант для частных лиц и малых и средних компаний с ограниченными данными для обучения, финансами или тем и другим. LLM требуют больших объемов обучающих данных и, как следствие, огромных вычислительных ресурсов как для обучения, так и для работы.

Чтобы представить это в перспективе, генеральный директор OpenAI Сэм Альтман подтвердил, что на обучение им потребовалось более 100 миллионов долларов. GPT-4 во время выступления на мероприятии в Массачусетском технологическом институте (согласно Wired). Другой пример — LLM OPT-175B компании Meta. Meta сообщает, что обучение проводилось с использованием 992 графических процессоров NVIDIA A100 80 ГБ, стоимость которых, по данным CNBC, составляет примерно 10 000 долларов за единицу. Таким образом, стоимость составляет примерно 9 миллионов долларов, не включая другие расходы, такие как энергия, заработная плата и многое другое.
При таких цифрах малым и средним компаниям нецелесообразно обучать LLM. Напротив, у SLM более низкий барьер входа с точки зрения ресурсов и меньшие затраты на эксплуатацию, и, таким образом, больше компаний будут использовать их.
2. Повышение производительности
Производительность – еще один аспект область, где SLM превосходят LLM благодаря своим компактным размерам. SLM имеют меньшую задержку и больше подходят для сценариев, где необходимы более быстрые ответы, например, в приложениях реального времени. Например, более быстрый ответ предпочтителен в системах голосового ответа, таких как цифровые помощники.

Выполнение на устройстве (подробнее об этом позже) также означает, что вашему запросу не придется совершать поездку на онлайн-серверы и обратно на них. ответьте на ваш запрос, что приведет к более быстрому ответу.
3. Более точный
Когда дело доходит до генеративного ИИ, одно остается неизменным: мусор на входе, мусор на выходе. Текущие LLM прошли обучение с использованием больших наборов необработанных данных из Интернета. Таким образом, они могут быть не точными во всех ситуациях. Это одна из проблем ChatGPT и подобных моделей, и почему не следует доверять всему, что говорит чат-бот с искусственным интеллектом. С другой стороны, SLM обучаются с использованием данных более высокого качества, чем LLM, и, следовательно, имеют более высокую точность. области по сравнению с более крупными и обобщенными моделями.

4. Может работать на устройстве
SLM требуют меньше вычислительной мощности, чем LLM, и поэтому идеально подходят для периферийных вычислений. Их можно развернуть на периферийных устройствах, таких как смартфоны и автономные транспортные средства, которые не обладают большой вычислительной мощностью или ресурсами. Модель Google Nano может работать на устройстве, что позволяет ей работать даже при отсутствии активного подключения к Интернету.Эта возможность представляет собой беспроигрышную ситуацию как для компаний, так и для потребителей. Во-первых, это выигрыш в плане конфиденциальности, поскольку пользовательские данные обрабатываются локально, а не отправляются в облако, что важно, поскольку в наши смартфоны интегрировано все больше искусственного интеллекта, содержащего почти все подробности о нас. Это также выгода для компаний, поскольку им не нужно развертывать и запускать большие серверы для решения задач ИИ.

SLM набирает обороты благодаря крупнейшим игрокам отрасли, таким как Open AI, Google, Microsoft, Anthropic и Meta выпускают такие модели. Эти модели больше подходят для более простых задач, для которых большинство из нас использует LLM; следовательно, за ними будущее.
Но LLM никуда не денется. Вместо этого они будут использоваться для продвинутых приложений, которые объединяют информацию из разных областей для создания чего-то нового, например, в медицинских исследованиях.
-
 Алгоритмы разведки роя: три реализации PythonImagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...ИИ Опубликовано в 2025-03-24
Алгоритмы разведки роя: три реализации PythonImagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...ИИ Опубликовано в 2025-03-24 -
Как сделать ваш LLM более точным с тряпкой и тонкой настройкойImagine studying a module at university for a semester. At the end, after an intensive learning phase, you take an exam – and you can recall th...ИИ Опубликовано в 2025-03-24
-
Что такое Google Gemini? Все, что вам нужно знать о конкуренте Google ChatgptGoogle recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members ...ИИ Опубликовано в 2025-03-23
-
Руководство по подсказке с DSPYdspy: декларативная структура для построения и улучшения приложений LLM dspy (декларативные самосовершенствовающие языковые программы) революциониз...ИИ Опубликовано в 2025-03-22
-
Автоматизируйте блог в Twitter Threadэта статья подробно описывает преобразование контента с длинной формой (например, в блогах) в привлечение потоков Twitter с использованием LLM Gemini...ИИ Опубликовано в 2025-03-11
-
Искусственная иммунная система (AIS): руководство с примерами PythonВ этой статье исследуется искусственная иммунная система (AIS), вычислительные модели, вдохновленные замечательной способностью иммунной системы чело...ИИ Опубликовано в 2025-03-04
-
Попробуйте задать ChatGPT эти забавные вопросы о себеВы когда-нибудь задумывались, что ChatGPT знает о вас? Как он обрабатывает информацию, которую вы ему передаете с течением времени? Я использовал кучу...ИИ Опубликовано 22 ноября 2024 г.
-
Вот как вы все еще можете попробовать загадочного чат-бота GPT-2Если вам нравятся модели искусственного интеллекта или чат-боты, возможно, вы видели дискуссии о загадочном чат-боте GPT-2 и его эффективности.Здесь м...ИИ Опубликовано 8 ноября 2024 г.
-
Режим Canvas в ChatGPT великолепен: 4 способа его использованияНовый режим Canvas в ChatGPT добавил дополнительные возможности к написанию и редактированию в ведущем в мире инструменте генеративного искусственного...ИИ Опубликовано 8 ноября 2024 г.
-
Как пользовательские GPT ChatGPT могут раскрыть ваши данные и как обеспечить их безопасностьПользовательская функция GPT ChatGPT позволяет любому создать собственный инструмент искусственного интеллекта практически для всего, что вы только м...ИИ Опубликовано 8 ноября 2024 г.
-
10 способов, которыми ChatGPT может помочь вам найти работу в LinkedInРаздел «О программе» вашего профиля LinkedIn, вмещающий 2600 доступных символов, — это отличное место, где можно рассказать о своем опыте, навыках, у...ИИ Опубликовано 8 ноября 2024 г.
-
Ознакомьтесь с этими 6 малоизвестными приложениями искусственного интеллекта, которые предоставляют уникальные возможностиНа данный момент большинство людей слышали о ChatGPT и Copilot, двух новаторских приложениях для генеративного ИИ, которые возглавили бум ИИ.Но знаете...ИИ Опубликовано 8 ноября 2024 г.
-
Эти 7 признаков показывают, что мы уже достигли пика развития искусственного интеллектаГде бы вы ни посмотрели в Интернете, есть сайты, сервисы и приложения, заявляющие, что использование ИИ делает его лучшим вариантом. Не знаю, как вы, ...ИИ Опубликовано 8 ноября 2024 г.
-
4 инструмента обнаружения ChatGPT для проверки искусственного интеллекта для учителей, лекторов и руководителейПо мере того, как ChatGPT становится все более популярным, становится все труднее отличить, что написано человеком, а что создано ИИ. Из-за этого учи...ИИ Опубликовано 8 ноября 2024 г.
-
Расширенная голосовая функция ChatGPT распространяется среди большего числа пользователейЕсли вы когда-либо хотели провести полноценный разговор с ChatGPT, теперь вы можете это сделать. То есть до тех пор, пока вы платите за право использо...ИИ Опубликовано 8 ноября 2024 г.















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









