
Java-программа для удаления дубликатов из заданного стека
 Просматривать:125
Просматривать:125
В этой статье мы рассмотрим два метода удаления повторяющихся элементов из стека в Java. Мы сравним простой подход с вложенными циклами и более эффективный метод с использованием HashSet. Цель — продемонстрировать, как оптимизировать удаление дубликатов, и оценить эффективность каждого подхода.
Постановка задачи
Напишите программу на Java для удаления повторяющегося элемента из стека.
Вход
Stackdata = initData(10L);
Выход
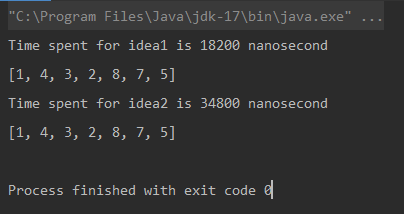
Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Naive Approach: 18200 nanoseconds Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Optimized Approach: 34800 nanoseconds
Чтобы удалить дубликаты из данного стека, у нас есть 2 подхода:
- Наивный подход: создайте два вложенных цикла, чтобы увидеть, какие элементы уже присутствуют, и предотвратить их добавление в возвращаемый стек результатов.
- Подход HashSet: используйте Set для хранения уникальных элементов и воспользуйтесь его сложностью O(1) для проверки наличия элемента или нет.
Создание и клонирование случайных стеков
Ниже приведена программа на Java, которая сначала создает случайный стек, а затем создает его дубликат для дальнейшего использования —
private static Stack initData(Long size) {
Stack stack = new Stack ();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i manualCloneStack(Stack stack) {
Stack newStack = new Stack ();
for (Integer item: stack) {
newStack.push(item);
}
return newStack;
}
initData помогает создать стек заданного размера и случайных элементов в диапазоне от 1 до 100.
manualCloneStack помогает генерировать данные путем копирования данных из другого стека и использования их для сравнения производительности двух идей.
Удалить дубликаты из заданного стека, используя наивный подход
Ниже приведен шаг по удалению дубликатов из данного стека с использованием наивного подхода —
- Запустите таймер.
- Создайте пустой стек для хранения уникальных элементов.
- Выполните итерацию с использованием цикла while и продолжайте, пока исходный стек не станет пустым, извлеките верхний элемент.
- Проверьте наличие дубликатов, используя resultStack.contains(element), чтобы узнать, находится ли элемент уже в стеке результатов.
- Если элемента нет в стеке результатов, добавьте его в стек результатов.
- Запишите время окончания и подсчитайте общее потраченное время.
- Вернуть результат
Пример
Ниже приведена Java-программа для удаления дубликатов из заданного стека с использованием наивного подхода –
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack ();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.println("Time spent for idea1 is %d nanosecond".formatted(System.nanoTime() - start));
return resultStack;
}
Для наивного подхода мы используем
while (!stack.isEmpty())
resultStack.contains(element)
, чтобы проверить, присутствует ли элемент. Удалить дубликаты из заданного стека, используя оптимизированный подход (HashSet)
Ниже приведен шаг по удалению дубликатов из данного стека с использованием оптимизированного подхода —
- Запустить таймер
- Создайте набор для отслеживания видимых элементов (для проверок сложности O(1)).
- Создайте временный стек для хранения уникальных элементов.
- Итерация с использованием цикла while продолжается до тех пор, пока стек не станет пустым.
- Удалить верхний элемент из стека.
- Чтобы проверить дубликаты, мы будем использовать seen.contains(element), чтобы проверить, находится ли элемент уже в наборе.
- Если элемента нет в наборе, добавьте его как в видимый, так и во временный стек.
- Запишите время окончания и подсчитайте общее потраченное время.
- Вернуть результат
Пример
Ниже приведена Java-программа для удаления дубликатов из заданного стека с помощью HashSet —
public static Stackidea2(Stack stack) { long start = System.nanoTime(); Set seen = new HashSet(); Stack tempStack = new Stack(); while (!stack.isEmpty()) { int element = stack.pop(); if (!seen.contains(element)) { seen.add(element); tempStack.push(element); } } System.out.println("Time spent for idea2 is %d nanosecond".formatted(System.nanoTime() - start)); return tempStack; }
Для оптимизации подхода мы используем
Set seen Использование обоих подходов вместе
Ниже приведен шаг по удалению дубликатов из данного стека с использованием обоих подходов, упомянутых выше:
- Инициализируя данные, мы используем метод initData(Long size) для создания стека, заполненного случайными целыми числами.
- Клонирование стека. Мы используем метод cloneStack(Stack stack) для создания точной копии исходного стека.
- Сгенерируйте исходный стек с помощью initData.
- Клонируйте этот стек, используя cloneStack.
- Примените наивный подход для удаления дубликатов из исходного стека.
- Примените оптимизированный подход для удаления дубликатов из клонированного стека.
- Отобразите время, затраченное на каждый метод, и уникальные элементы, полученные с помощью обоих подходов.
Пример
Ниже представлена программа на Java, которая удаляет повторяющиеся элементы из стека, используя оба упомянутых выше подхода –
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.Stack;
public class DuplicateStackElements {
private static Stack initData(Long size) {
Stack stack = new Stack();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i cloneStack(Stack stack) {
Stack newStack = new Stack();
newStack.addAll(stack);
return newStack;
}
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.printf("Time spent for idea1 is %d nanoseconds%n", System.nanoTime() - start);
return resultStack;
}
public static Stack idea2(Stack stack) {
long start = System.nanoTime();
Set seen = new HashSet();
Stack tempStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.printf("Time spent for idea2 is %d nanoseconds%n", System.nanoTime() - start);
return tempStack;
}
public static void main(String[] args) {
Stack data1 = initData(10L);
Stack data2 = cloneStack(data1);
System.out.println("Unique elements using idea1: " idea1(data1));
System.out.println("Unique elements using idea2: " idea2(data2));
}
}
Выход
Сравнение
* Единица измерения — наносекунда.
public static void main(String[] args) {
Stack data1 = initData();
Stack data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}
| Метод | 100 элементов | 1000 элементов | 10000 элементов |
100000 элементов |
1000000 элементов |
| Идея 1 | 693100 |
4051600 |
19026900 |
114201800 |
1157256000 |
| Идея 2 | 135800 |
681400 |
2717800 |
11489400 |
36456100 |
Как уже отмечалось, время реализации идеи 2 короче, чем для идеи 1, поскольку сложность идеи 1 равна O(n²), а сложность идеи 2 — O(n). Так вот, когда количество стеков увеличивается, время, затрачиваемое на расчеты, тоже увеличивается на его основе.
-
 jQuery получает значение радионогиальной группыВ этой статье содержится краткие фрагменты кода jQuery и ответы, часто задаваемые вопросы (FAQS), касающиеся манипулирования групп радиопроизводст...программирование Опубликовано в 2025-04-18
jQuery получает значение радионогиальной группыВ этой статье содержится краткие фрагменты кода jQuery и ответы, часто задаваемые вопросы (FAQS), касающиеся манипулирования групп радиопроизводст...программирование Опубликовано в 2025-04-18 -
Как я могу эффективно заменить несколько подстроков в строке Java?заменить несколько подстроков в строку эффективно в Java , когда сталкивается с необходимостью заменить несколько подстроков в строке, это зама...программирование Опубликовано в 2025-04-18
-
Почему PHP DateTime :: Modify ('+1 месяц') дает неожиданные результаты?изменение месяцев с PHP DateTime: раскрыть предполагаемое поведение при работе с классом DateTime PHP, добавление или вычитание месяцев не все...программирование Опубликовано в 2025-04-18
-
Как проверить, есть ли у объекта конкретный атрибут в Python?Метод для определения атрибута объекта Этот запрос ищет метод для проверки присутствия конкретного атрибута в объекте. Рассмотрим следующий пр...программирование Опубликовано в 2025-04-18
-
Как правильно отобразить текущую дату и время в формате «DD/MM/yyyy HH: MM: Ss.SS» в Java?Как отобразить текущую дату и время в «dd/mm/yyyy hh: mm: ss.ss" format в предоставленном коде Java, выпуск с датой и временем в желании ...программирование Опубликовано в 2025-04-18
-
Как я могу настроить оптимизацию компиляции в компиляторе GO?настройка оптимизации компиляции в GO Compiler процесс компиляции по умолчанию в GO следует за конкретной стратегией оптимизации. Однако польз...программирование Опубликовано в 2025-04-18
-
Почему Microsoft Visual C ++ не может правильно реализовать двухфазной экземпляры?загадка «Сломанная» двухфазное матричное экземпляры в Microsoft Visual C Задача: пользователи обычно выражают обеспокоенность Microsoft Visu...программирование Опубликовано в 2025-04-18
-
FOSTAPI CUSTEM 404 Руководство по созданию страницCustom 404 не найдена страницей с FastApi , чтобы создать пользовательскую страницу 404, не найденная, FastApi предлагает несколько подходов. С...программирование Опубликовано в 2025-04-18
-
Как разрешить ошибку \ "Неверное использование групповой функции \" в MySQL при поиске максимального подсчета?Как получить максимальный счет, используя MySQL В MySQL вы можете столкнуться с проблемой, пытаясь найти максимальный подсчет значений, сгрупп...программирование Опубликовано в 2025-04-18
-
Используйте MySQLI, чтобы получить одномерный метод одномерного массива с одним столбцомКак получить значения отдельного столбца в виде одномерного массива с использованием MySQLI? Вместо желаемого одномерного массива вы получаете мн...программирование Опубликовано в 2025-04-18
-
Множествометоды являются FNS, которые можно вызвать на Objects ] Массивы являются объектами, следовательно, они также имеют методы в JS. ] ] Срез (...программирование Опубликовано в 2025-04-18
-
Как удалить смайлики из струн в Python: руководство для начинающих по исправлению общих ошибок?удаление emojis из строк в Python import codecs import re text = codecs.decode('This dog \U0001f602'.encode('UTF-8'), 'UTF-8') print(text) # ...программирование Опубликовано в 2025-04-18
-
Какие узоры дизайна для асинхронных обещаний повторение?проектирование шаблонов для обещания Retries В асинхронном программировании часто полезно повторно выполнить неудачные обещания, пока они не р...программирование Опубликовано в 2025-04-18
-
Как я могу эффективно прочитать большой файл в обратном порядке с помощью Python?Чтение файла в обратном порядке в Python Если вы работаете с большим файлом, и вам необходимо прочитать его содержимое с последней строки до п...программирование Опубликовано в 2025-04-18
-
Как проанализировать числа в экспоненциальной нотации с помощью Decimal.parse ()?анализирует число из экспоненциальной нотации При попытке проанализировать строку, выраженную в экспоненциальной нотации, используя Tecimal.pa...программирование Опубликовано в 2025-04-18















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









