 титульная страница > программирование > FireDucks: получите производительность, превосходящую возможности панд, без затрат на обучение!
титульная страница > программирование > FireDucks: получите производительность, превосходящую возможности панд, без затрат на обучение!
FireDucks: получите производительность, превосходящую возможности панд, без затрат на обучение!
 Просматривать:309
Просматривать:309
Pandas — одна из самых популярных библиотек. Когда я искал более простой способ ускорить ее работу, я обнаружил FireDucks и заинтересовался ею!
Сравнение с пандами: Почему FireDucks?
Программа Pandas может столкнуться с серьезной проблемой производительности в зависимости от того, как она была написана. Однако, будучи специалистом по данным, я хочу тратить все больше и больше времени на анализ данных, а не на повышение производительности своего кода. Итак, было бы здорово, если бы он мог делать что-то вроде изменения порядка процессов и автоматического ускорения работы программы. Например, Процесс A =>Процесс B будет медленнее, поэтому мы заменим его на Процесс B =>Процесс A. (Разумеется, результат гарантированно будет тот же.) Говорят, что ученые, работающие с данными, тратят около 45% потратили время на подготовку данных, и когда я подумывал сделать что-нибудь для ускорения процесса, я наткнулся на модуль под названием FireDucks.
Из документации FireDucks видно, что он поддерживается только для платформ Linux. Поскольку я использую Windows на своей основной машине, я хотел бы попробовать ее из WSL2 (подсистема Windows для Linux), среды, в которой можно запускать Linux в Windows.
Я пробовал следующую среду.
- ОС Microsoft Windows 11 Pro
- Версия 10.0.22631 Сборка 22631
- Модель системы Z690 Pro RS
- Тип системы на базе x64
- Процессор для ПК Intel(R) Core(TM) i3–12100 12-го поколения, 3300 МГц, 4 ядра, 8 логических процессоров
- Базовая плата Z690 Pro RS
- Рабочий стол платформы
- Установленная физическая память (ОЗУ)64,0 ГБ
Установка и настройка FireDucks
Установить WSL
WSL был установлен с помощью следующей документации Microsoft; дистрибутив Linux — Ubuntu 22.04.1 LTS.
Установить FireDucks
Затем установите FireDucks. Однако его очень легко установить.
pip install fireducks
Установка FireDucks (вместе с pyarrow, pandas и другими библиотеками) займет несколько минут.
Я попробовал выполнить приведенный ниже код, скорость загрузки была очень высокой: pandas потребовалось 4 секунды, а fireDucks — всего 74,5 нс.
# 1. analysis based on time period and creative duration # convert timestamp to date/time object df['timestamp_converted'] = pd.to_datetime(df['timestamp'], unit='s ') # define time period def get_part_of_day(hour): if 5Вся предварительная обработка и анализ данных в Pandas заняла около 8 секунд, тогда как при использовании FireDucks их можно было завершить за 4 секунды. Можно добиться ускорения почти в 2 раза.
Улучшенная производительность
Одна из самых напряженных вещей при использовании pandas — это ожидание при загрузке больших наборов данных, а затем мне приходится ждать сложной операции, такой как groupby. С другой стороны, поскольку FireDucks выполняет отложенную оценку, сама загрузка вообще не занимает времени, поэтому обработка выполняется там, где это необходимо, и я считаю, что это очень важно, поскольку общее время ожидания значительно сокращается.
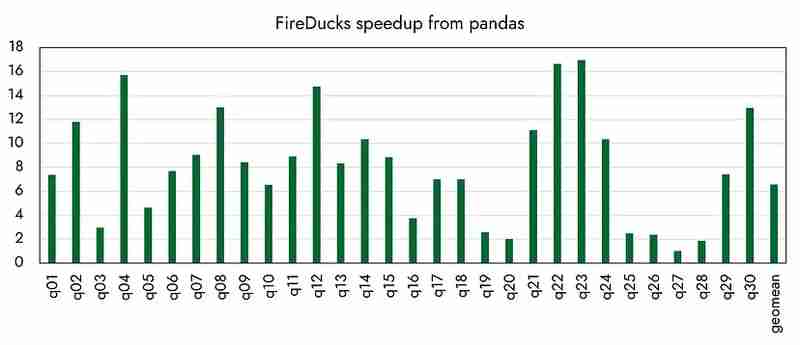
Что касается другой производительности, то, как официально заявлено организацией, кажется, что она была достигнута в 16 раз быстрее по сравнению с пандами. (В следующий раз я сравню производительность с различными конкурирующими библиотеками.)
нулевая стоимость обучения
Возможность следовать точным обозначениям pandas, не задумываясь ни о чем, является огромным преимуществом. Помимо FireDucks, существуют и другие библиотеки ускорения фреймов данных, но их слишком дорого изучать и слишком легко забыть.
Например, если вы хотите добавить столбцы с полярами, вам нужно написать что-то вроде этого.
# pandas df["new_col"] = df["A"] 1 # polars df = df.with_columns((pl.col("A") 1).alias("new_col"))Практически нет необходимости изменять существующий код
У меня есть несколько ETL и других проектов, использующих pandas, и было бы неплохо увидеть улучшение производительности, просто установив и заменив оператор импорта на FireDucks.
Если вы хотите добавить его дальше, оставьте комментарий ниже.
-
 Как эффективно вставить данные в несколько таблиц MySQL в одну транзакцию?mysql вставьте в несколько таблиц , пытаясь вставить данные в несколько таблиц с одним запросом MySQL, может дать неожиданные результаты. Хотя ...программирование Опубликовано в 2025-07-06
Как эффективно вставить данные в несколько таблиц MySQL в одну транзакцию?mysql вставьте в несколько таблиц , пытаясь вставить данные в несколько таблиц с одним запросом MySQL, может дать неожиданные результаты. Хотя ...программирование Опубликовано в 2025-07-06 -
Почему PHP DateTime :: Modify ('+1 месяц') дает неожиданные результаты?изменение месяцев с PHP DateTime: раскрыть предполагаемое поведение при работе с классом DateTime PHP, добавление или вычитание месяцев не все...программирование Опубликовано в 2025-07-06
-
Eval () против AST.Literal_EVAL (): какая функция Python безопаснее для пользовательского ввода?взвешивание eval () и ast.literal_eval () в Python Security при обращении с вводом пользователя, это необходимо определить определение безопас...программирование Опубликовано в 2025-07-06
-
Как проанализировать числа в экспоненциальной нотации с помощью Decimal.parse ()?анализирует число из экспоненциальной нотации При попытке проанализировать строку, выраженную в экспоненциальной нотации, используя Tecimal.pa...программирование Опубликовано в 2025-07-06
-
Разрешает ли Java несколько типов возврата: более пристальный взгляд на общие методы?множественные типы возврата в Java: a miscessception presvelired в сфере программирования Java, может возникнуть признание метода, оставляя ра...программирование Опубликовано в 2025-07-06
-
Как сортировать ключи от Javascript объекта в алфавитном порядке?Как сортировать объекты javascript по Key Если у вас есть объект JavaScript, вы можете реорганизовать его свойства алфавитно для улучшенных це...программирование Опубликовано в 2025-07-06
-
Почему выполнение JavaScript прекращается при использовании кнопки Firefox Back?Проблема истории навигации: Javascript перестает выполнять после использования кнопки Firefox Back пользователи Firefox могут столкнуться с пр...программирование Опубликовано в 2025-07-06
-
PHP Simplexml SAINGING XML Метод с пространством имен толстой кишкиparsing xml с пространством именами Colons в PHP Simplexml столкнулся с трудностями при разборе XML, содержащих теги Colons, такие как элемент...программирование Опубликовано в 2025-07-06
-
Как решить ошибку «Не можете угадать тип файла, используйте приложение/октет-поток ...» в Appengine?appengine static file type type override в Appengine, статические обработки файлов могут иногда переопределять правильный тип панели Mime, что...программирование Опубликовано в 2025-07-06
-
Python Read File CSV UnicoDedeCodeError Ultimate Solutionошибка декодирования Unicod Не могу декодировать байты В позиции 2-3: усеченная \ uxxxxxxxxxxxx эта ошибка возникает, когда путь к файлу CSV со...программирование Опубликовано в 2025-07-06
-
Как правильно вставить Blobs (изображения) в MySQL с помощью PHP?вставьте Blobs в базы данных MySQL с PHP При попытке сохранить изображение в базе данных MySQL, вы можете столкнуться с проблемой. Это руково...программирование Опубликовано в 2025-07-06
-
Как передавать эксклюзивные указатели в качестве функции или параметров конструктора в C ++?] управление уникальными указателями как параметры в конструкторах и функциях уникальные указатели ( уникальный Последствия. прохождение по зн...программирование Опубликовано в 2025-07-06
-
Какой метод более эффективен для обнаружения с точки зрения полигона: трассировка лучей или matplotlib \ path.contains_points?эффективное обнаружение с пунктом-в полигоне в Python определение того, находится ли точка в полигоне частой задачей в вычислительной геометрии....программирование Опубликовано в 2025-07-06
-
Объект: обложка не удается в IE и Edge, как исправить?object-fit: cover не удастся в IE и Edge, как исправить? В CSS для поддержания постоянной высоты изображения работает беспрепятственно через брау...программирование Опубликовано в 2025-07-06
-
Как я могу настроить оптимизацию компиляции в компиляторе GO?настройка оптимизации компиляции в GO Compiler процесс компиляции по умолчанию в GO следует за конкретной стратегией оптимизации. Однако польз...программирование Опубликовано в 2025-07-06















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









