 титульная страница > программирование > Выбор функций с помощью алгоритма IAMB: случайное погружение в машинное обучение
титульная страница > программирование > Выбор функций с помощью алгоритма IAMB: случайное погружение в машинное обучение
Выбор функций с помощью алгоритма IAMB: случайное погружение в машинное обучение
 Просматривать:668
Просматривать:668
Итак, вот история: недавно я работал над школьным заданием профессора Чжуана, включающим довольно крутой алгоритм под названием Марковское одеяло дополнительных ассоциаций (IAMB). У меня нет опыта работы в области науки о данных или статистики, так что это новая территория для меня, но я люблю узнавать что-то новое. Цель? Используйте IAMB, чтобы выбрать функции в наборе данных и посмотреть, как это влияет на производительность модели машинного обучения.
Мы рассмотрим основы алгоритма IAMB и применим его к Набору данных о диабете у индейцев Пима из наборов данных Джейсона Браунли. Этот набор данных отслеживает данные о здоровье женщин и включает информацию о том, есть ли у них диабет или нет. Мы будем использовать IAMB, чтобы выяснить, какие характеристики (например, ИМТ или уровень глюкозы) имеют наибольшее значение для прогнозирования диабета.
Что такое алгоритм IAMB и зачем его использовать?
Алгоритм IAMB подобен другу, который помогает вам очистить список подозреваемых в загадке: это метод выбора признаков, предназначенный для выбора только тех переменных, которые действительно важны для прогнозирования вашей цели. В данном случае целью является наличие у кого-либо диабета.
- Форвардная фаза: добавьте переменные, тесно связанные с целью.
- Обратная фаза: удалите переменные, которые на самом деле не помогают, оставив только самые важные.
Проще говоря, IAMB помогает нам избежать беспорядка в нашем наборе данных, выбирая только наиболее релевантные функции. Это особенно удобно, если вы хотите упростить задачу, повысить производительность модели и ускорить время обучения.
Источник: Алгоритмы крупномасштабного открытия Марковского бланкета
Что это за альфа-вещь и почему это важно?
Здесь появляется альфа. В статистике альфа (α) — это порог, который мы устанавливаем, чтобы решить, что считать «статистически значимым». В рамках инструкций, данных профессором, я использовал альфа 0,05, что означает, что я хочу сохранить только те функции, вероятность случайной связи которых с целевой переменной составляет менее 5%. Итак, если p-значение функции меньше 0,05, это означает, что существует сильная, статистически значимая связь с нашей целью.
Используя этот альфа-порог, мы концентрируемся только на наиболее значимых переменных, игнорируя те, которые не проходят наш тест на «значимость». Это похоже на фильтр, который сохраняет наиболее важные функции и отбрасывает шум.
Практический опыт: использование IAMB в наборе данных о диабете у индейцев пима
Вот настройка: набор данных о диабете индейцев пима включает характеристики здоровья (кровяное давление, возраст, уровень инсулина и т. д.) и нашу цель, Результат (есть ли у кого-то диабет).
Сначала мы загружаем данные и проверяем их:
import pandas as pd # Load and preview the dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv' column_names = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome'] data = pd.read_csv(url, names=column_names) print(data.head())
Реализация IAMB с Alpha = 0,05
Вот наша обновленная версия алгоритма IAMB. Мы используем p-значения, чтобы решить, какие функции сохранить, поэтому выбираются только те, у которых p-значения меньше нашей альфа (0,05).
import pingouin as pg
def iamb(target, data, alpha=0.05):
markov_blanket = set()
# Forward Phase: Add features with a p-value alpha
for feature in list(markov_blanket):
reduced_mb = markov_blanket - {feature}
result = pg.partial_corr(data=data, x=feature, y=target, covar=reduced_mb)
p_value = result.at[0, 'p-val']
if p_value > alpha:
markov_blanket.remove(feature)
return list(markov_blanket)
# Apply the updated IAMB function on the Pima dataset
selected_features = iamb('Outcome', data, alpha=0.05)
print("Selected Features:", selected_features)
Когда я запустил это исследование, оно дало мне уточненный список функций, которые, по мнению IAMB, наиболее тесно связаны с исходами диабета. Этот список помогает сузить список переменных, которые нам нужны для построения нашей модели.
Selected Features: ['BMI', 'DiabetesPedigreeFunction', 'Pregnancies', 'Glucose']
Тестирование влияния выбранных IAMB функций на производительность модели
После того как мы выбрали выбранные функции, в реальном тесте производительность модели сравнивается с всеми функциями и функциями, выбранными IAMB. Для этого я выбрал простую гауссовскую наивную байесовскую модель, потому что она проста и хорошо справляется с вероятностями (что соответствует всей байесовской атмосфере).
Вот код для обучения и тестирования модели:
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score
# Split data
X = data.drop('Outcome', axis=1)
y = data['Outcome']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Model with All Features
model_all = GaussianNB()
model_all.fit(X_train, y_train)
y_pred_all = model_all.predict(X_test)
# Model with IAMB-Selected Features
X_train_selected = X_train[selected_features]
X_test_selected = X_test[selected_features]
model_iamb = GaussianNB()
model_iamb.fit(X_train_selected, y_train)
y_pred_iamb = model_iamb.predict(X_test_selected)
# Evaluate models
results = {
'Model': ['All Features', 'IAMB-Selected Features'],
'Accuracy': [accuracy_score(y_test, y_pred_all), accuracy_score(y_test, y_pred_iamb)],
'F1 Score': [f1_score(y_test, y_pred_all, average='weighted'), f1_score(y_test, y_pred_iamb, average='weighted')],
'AUC-ROC': [roc_auc_score(y_test, y_pred_all), roc_auc_score(y_test, y_pred_iamb)]
}
results_df = pd.DataFrame(results)
display(results_df)
Результаты
Вот как выглядит сравнение:
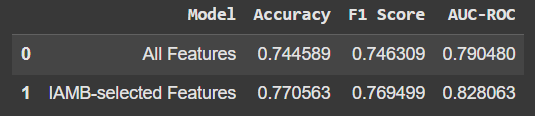
Использование только функций, выбранных IAMB, немного повысило точность и другие показатели. Это не такой уж большой скачок, но тот факт, что мы получаем лучшую производительность с меньшим количеством функций, является многообещающим. Кроме того, это означает, что наша модель не полагается на «шум» или нерелевантные данные.
Ключевые выводы
- IAMB отлично подходит для выбора функций.: он помогает очистить наш набор данных, сосредоточив внимание только на том, что действительно важно для прогнозирования нашей цели.
- Меньше часто значит больше: иногда меньшее количество функций дает лучшие результаты, как мы видели здесь, с небольшим повышением точности модели.
- Обучение и экспериментирование — это самое интересное: даже без глубокого опыта в области науки о данных погружение в подобные проекты открывает новые способы понимания данных и машинного обучения.
Надеюсь, это станет дружеским знакомством с IAMB! Если вам интересно, попробуйте — это удобный инструмент в наборе инструментов машинного обучения, и вы можете увидеть некоторые интересные улучшения в своих собственных проектах.
Источник: Алгоритмы крупномасштабного открытия Марковского бланкета
-
 Как исправить «Неправильно сконфигурировано: ошибка загрузки модуля MySQLdb» в Django на macOS?Неправильная настройка MySQL: проблема с относительными путямиПри запуске сервера запуска Python Manage.py в Django вы можете столкнуться со следующей...программирование Опубликовано 18 ноября 2024 г.
Как исправить «Неправильно сконфигурировано: ошибка загрузки модуля MySQLdb» в Django на macOS?Неправильная настройка MySQL: проблема с относительными путямиПри запуске сервера запуска Python Manage.py в Django вы можете столкнуться со следующей...программирование Опубликовано 18 ноября 2024 г. -
Как объединить два ассоциативных массива в PHP, сохранив при этом уникальные идентификаторы и обработав повторяющиеся имена?Объединение ассоциативных массивов в PHPВ PHP объединение двух ассоциативных массивов в один — распространенная задача. Рассмотрим следующий запрос:Оп...программирование Опубликовано 18 ноября 2024 г.
-
Как я могу найти пользователей, у которых сегодня дни рождения, используя MySQL?Как определить пользователей с сегодняшним днем рождения с помощью MySQLОпределение того, является ли сегодня день рождения пользователя с помощью M...программирование Опубликовано 18 ноября 2024 г.
-
Как я могу использовать безразмерные переменные CSS с разными единицами измерения?Как гибко использовать безразмерные переменные CSSБезразмерные переменные CSS предоставляют возможность хранить числовые значения, которые можно удобн...программирование Опубликовано 18 ноября 2024 г.
-
Запуск функции при разрешении блока #await в Svelte (Kit)Перейти к содержимому: О блоке #await в svelte Запустить (запустить) функцию, когда блок #await разрешается или отклоняется Исправить неопределенный и...программирование Опубликовано 18 ноября 2024 г.
-
Помимо операторов if: где еще можно использовать тип с явным преобразованием bool без приведения?Контекстное преобразование в bool разрешено без приведения Ваш класс определяет явное преобразование в bool, что позволяет использовать его экземпляр ...программирование Опубликовано 18 ноября 2024 г.
-
Можете ли вы иметь несколько классов в одном файле Java?Несколько классов в файле JavaВ Java можно иметь несколько классов в одном файле .java. Однако может быть только один общедоступный класс верхнего уро...программирование Опубликовано 18 ноября 2024 г.
-
Что случилось со смещением столбцов в бета-версии Bootstrap 4?Bootstrap 4 Beta: удаление и восстановление смещения столбцовBootstrap 4 в своей бета-версии 1 внес существенные изменения в способ столбцы были смеще...программирование Опубликовано 18 ноября 2024 г.
-
Как тестировать соединения с базой данных PDO и эффективно обрабатывать ошибки?Тестирование соединений с базой данных PDOПри разработке установок базы данных крайне важно обеспечить достоверность соединений с базой данных. Это ст...программирование Опубликовано 18 ноября 2024 г.
-
Перезаписывают ли запросы на обновление MySQL существующие значения, если они одинаковы?Запросы на обновление MySQL: перезапись существующих значенийВ MySQL при обновлении таблицы можно столкнуться со сценарием, когда новое значение, указ...программирование Опубликовано 18 ноября 2024 г.
-
Почему хранилище `std::atomic` использует XCHG для последовательной согласованности на x86?Почему хранилище std::atomic использует XCHG для последовательной согласованностиВ контексте std::atomic для архитектур x86 и x86_64 операция сохранен...программирование Опубликовано 18 ноября 2024 г.
-
МножествоМетоды — это fns, которые можно вызывать на объектах Массивы — это объекты, поэтому в JS у них тоже есть методы. срез (начало): извлечь часть ...программирование Опубликовано 18 ноября 2024 г.
-
Почему C++ напрямую не поддерживает возврат массивов из функций?Почему C не одобряет функции, возвращающие массивПейзаж CВ отличие от таких языков, как Java, C не не предлагает прямую поддержку функций, возвращающи...программирование Опубликовано 18 ноября 2024 г.
-
Хорошо, вот несколько заголовков, которые соответствуют содержанию статьи: * Как исправить ошибку «-lGL: не найден» в Qt * Ошибка компиляции Qt: «-lGL: не найден» — что делать * Устранение ошибки «-lGL: не найдено» в проектах Qt. *РешениеУстранение ошибки «-lGL: not Found» в QtПри попытке скомпилировать вновь созданный проект в QtCreator некоторые пользователи могут столкнуться ошибка ...программирование Опубликовано 18 ноября 2024 г.
-
Безопасно ли использовать функцию PHP `eval`?Когда (если когда-либо) eval НЕ является злом?Хотя функция PHP eval часто не поощряется, ее полезность в PHP 5.3 является спорной . Несмотря на появле...программирование Опубликовано 18 ноября 2024 г.















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









