 титульная страница > программирование > Использование библиотек Python Faker и Pandas для создания синтетических данных для тестирования
титульная страница > программирование > Использование библиотек Python Faker и Pandas для создания синтетических данных для тестирования
Использование библиотек Python Faker и Pandas для создания синтетических данных для тестирования
 Просматривать:948
Просматривать:948
Введение:
Комплексное тестирование имеет важное значение для приложений, управляемых данными, но оно часто зависит от наличия правильных наборов данных, которые не всегда могут быть доступны. Независимо от того, разрабатываете ли вы веб-приложения, модели машинного обучения или серверные системы, реалистичные и структурированные данные имеют решающее значение для правильной проверки и обеспечения надежной производительности. Получение реальных данных может быть ограничено из-за проблем конфиденциальности, лицензионных ограничений или просто отсутствия соответствующих данных. Именно здесь синтетические данные становятся ценными.
В этом блоге мы рассмотрим, как можно использовать Python для генерации синтетических данных для различных сценариев, в том числе:
- Взаимосвязанные таблицы: представление связей «один ко многим».
- Иерархические данные: часто используются в организационных структурах.
- Сложные отношения: например, отношения «многие ко многим» в системах регистрации.
Мы будем использовать библиотеки Faker и Pandas для создания реалистичных наборов данных для этих случаев использования.
Пример 1. Создание синтетических данных для клиентов и заказов (отношения «один ко многим»)
Во многих приложениях данные хранятся в нескольких таблицах со связями по внешнему ключу. Давайте сгенерируем синтетические данные о клиентах и их заказах. Клиент может разместить несколько заказов, что представляет собой связь «один ко многим».
Создание таблицы клиентов
Таблица «Клиенты» содержит основную информацию, такую как идентификатор клиента, имя и адрес электронной почты.
import pandas as pd
from faker import Faker
import random
fake = Faker()
def generate_customers(num_customers):
customers = []
for _ in range(num_customers):
customer_id = fake.uuid4()
name = fake.name()
email = fake.email()
customers.append({'CustomerID': customer_id, 'CustomerName': name, 'Email': email})
return pd.DataFrame(customers)
customers_df = generate_customers(10)
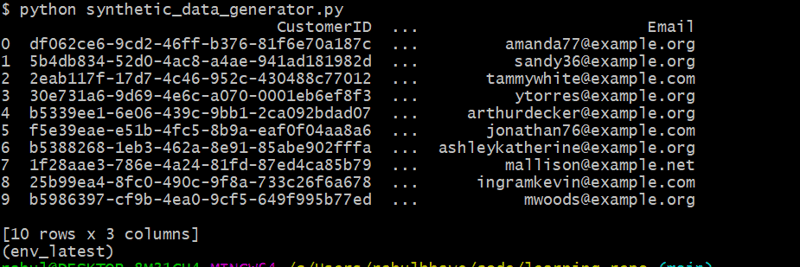
Этот код генерирует 10 случайных клиентов с помощью Faker для создания реалистичных имен и адресов электронной почты.
Создание таблицы заказов
Теперь мы создаем таблицу Orders, где каждый заказ связан с клиентом через CustomerID.
def generate_orders(customers_df, num_orders):
orders = []
for _ in range(num_orders):
order_id = fake.uuid4()
customer_id = random.choice(customers_df['CustomerID'].tolist())
product = fake.random_element(elements=('Laptop', 'Phone', 'Tablet', 'Headphones'))
price = round(random.uniform(100, 2000), 2)
orders.append({'OrderID': order_id, 'CustomerID': customer_id, 'Product': product, 'Price': price})
return pd.DataFrame(orders)
orders_df = generate_orders(customers_df, 30)
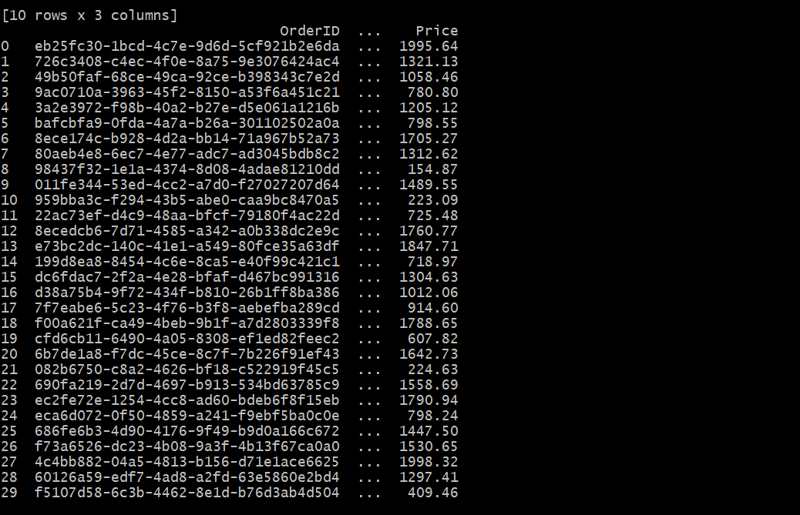
В этом случае таблица Orders связывает каждый заказ с клиентом с помощью CustomerID. Каждый клиент может разместить несколько заказов, образуя отношения «один ко многим».
Пример 2: создание иерархических данных для отделов и сотрудников
Иерархические данные часто используются в организациях, где в подразделениях работает несколько сотрудников. Давайте смоделируем организацию с отделами, в каждом из которых работает несколько сотрудников.
Создание таблицы отделов
Таблица «Отделы» содержит уникальный идентификатор отдела, имя и руководителя каждого отдела.
def generate_departments(num_departments):
departments = []
for _ in range(num_departments):
department_id = fake.uuid4()
department_name = fake.company_suffix()
manager = fake.name()
departments.append({'DepartmentID': department_id, 'DepartmentName': department_name, 'Manager': manager})
return pd.DataFrame(departments)
departments_df = generate_departments(10)
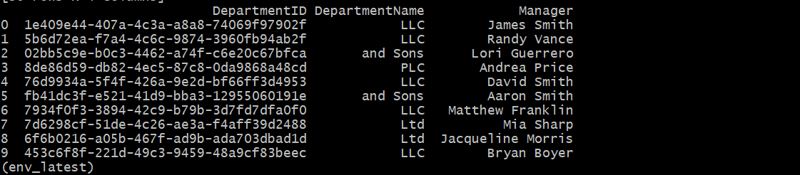
Создание таблицы сотрудников
Далее мы создаем таблицу Employeestable, где каждый сотрудник связан с отделом через DepartmentID.
def generate_employees(departments_df, num_employees):
employees = []
for _ in range(num_employees):
employee_id = fake.uuid4()
employee_name = fake.name()
email = fake.email()
department_id = random.choice(departments_df['DepartmentID'].tolist())
salary = round(random.uniform(40000, 120000), 2)
employees.append({
'EmployeeID': employee_id,
'EmployeeName': employee_name,
'Email': email,
'DepartmentID': department_id,
'Salary': salary
})
return pd.DataFrame(employees)
employees_df = generate_employees(departments_df, 100)
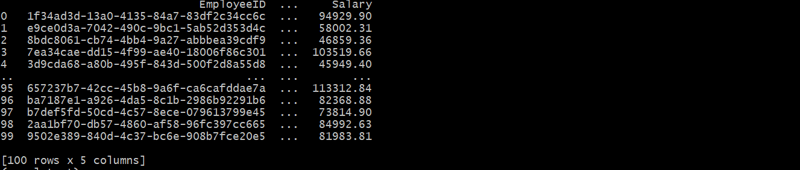
Эта иерархическая структура связывает каждого сотрудника с отделом через DepartmentID, образуя родительско-дочерние отношения.
Пример 3. Моделирование отношений «многие ко многим» для записи на курсы
В определенных сценариях существуют отношения «многие ко многим», когда одна сущность связана со многими другими. Давайте смоделируем это со студентами, зачисленными на несколько курсов, где на каждом курсе обучается несколько студентов.
Создание таблицы курсов
def generate_courses(num_courses):
courses = []
for _ in range(num_courses):
course_id = fake.uuid4()
course_name = fake.bs().title()
instructor = fake.name()
courses.append({'CourseID': course_id, 'CourseName': course_name, 'Instructor': instructor})
return pd.DataFrame(courses)
courses_df = generate_courses(20)
Создание таблицы учащихся
def generate_students(num_students):
students = []
for _ in range(num_students):
student_id = fake.uuid4()
student_name = fake.name()
email = fake.email()
students.append({'StudentID': student_id, 'StudentName': student_name, 'Email': email})
return pd.DataFrame(students)
students_df = generate_students(50)
print(students_df)
Создание таблицы набора на курсы
Таблица CourseEnrollments отражает отношения «многие ко многим» между студентами и курсами.
def generate_course_enrollments(students_df, courses_df, num_enrollments):
enrollments = []
for _ in range(num_enrollments):
enrollment_id = fake.uuid4()
student_id = random.choice(students_df['StudentID'].tolist())
course_id = random.choice(courses_df['CourseID'].tolist())
enrollment_date = fake.date_this_year()
enrollments.append({
'EnrollmentID': enrollment_id,
'StudentID': student_id,
'CourseID': course_id,
'EnrollmentDate': enrollment_date
})
return pd.DataFrame(enrollments)
enrollments_df = generate_course_enrollments(students_df, courses_df, 200)
В этом примере мы создаем связывающую таблицу для представления отношений «многие ко многим» между студентами и курсами.
Заключение:
Используя Python и такие библиотеки, как Faker и Pandas, вы можете создавать реалистичные и разнообразные синтетические наборы данных для удовлетворения различных потребностей тестирования. В этом блоге мы рассмотрели:
- Взаимосвязанные таблицы: демонстрация связи «один ко многим» между клиентами и заказами.
- Иерархические данные: иллюстрируют детско-родительские отношения между отделами и сотрудниками.
- Сложные отношения: моделирование отношений «многие ко многим» между студентами и курсами.
Эти примеры закладывают основу для создания синтетических данных, адаптированных к вашим потребностям. Дальнейшие улучшения, такие как создание более сложных связей, настройка данных для конкретных баз данных или масштабирование наборов данных для тестирования производительности, могут вывести генерацию синтетических данных на новый уровень.
Эти примеры обеспечивают прочную основу для создания синтетических данных. Однако для повышения сложности и специфичности можно внести дальнейшие улучшения, например:
- Данные, специфичные для базы данных: настройка генерации данных для различных систем баз данных (например, SQL или NoSQL).
- Более сложные отношения: создание дополнительных взаимозависимостей, таких как временные отношения, многоуровневые иерархии или уникальные ограничения.
- Масштабирование данных: создание больших наборов данных для тестирования производительности или стресс-тестирования, гарантируя, что система сможет обрабатывать реальные условия в большом масштабе. Создавая синтетические данные, адаптированные к вашим потребностям, вы можете моделировать реалистичные условия для разработки, тестирования и оптимизации приложений, не полагаясь на конфиденциальные или труднодоступные наборы данных.
Если вам понравилась статья, поделитесь ею с друзьями и коллегами. Вы можете связаться со мной в LinkedIn, чтобы обсудить любые дополнительные идеи.
-
 Как преодолеть ограничения переопределения функций PHP?преодоление ограничений переосмысления функции PHP в PHP, определение функции с одним и тем же именем несколько раз-нет-нет. Попытка сделать э...программирование Опубликовано в 2025-07-02
Как преодолеть ограничения переопределения функций PHP?преодоление ограничений переосмысления функции PHP в PHP, определение функции с одним и тем же именем несколько раз-нет-нет. Попытка сделать э...программирование Опубликовано в 2025-07-02 -
Как преобразовать столбец DataFrame Pandas в формат DateTime и фильтр по дате?Transform Pandas DataFrame в Format DateTime сценарий: данные в данных Pandas DataFrame часто существует в различных форматах, включая строк...программирование Опубликовано в 2025-07-02
-
Как я могу программно выбрать весь текст в Div на мыши щелкнуть?программно выбрать текст div на мышью щелкнут Вопрос , данный элемент div с текстовым контентом, как пользователь может программно выбрать весь...программирование Опубликовано в 2025-07-02
-
Могут ли CSS найти HTML -элементы на основе какого -либо значения атрибута?] нацеливание html -элементов с любым значением атрибута в CSS в CSS, можно нацелить элементы на основе конкретных атрибутов, как показано в пр...программирование Опубликовано в 2025-07-02
-
Как реализовать пользовательские события, используя шаблон наблюдателя в Java?Создание пользовательских событий в Java пользовательские события являются незаменимыми во многих сценариях программирования, позволяя компонент...программирование Опубликовано в 2025-07-02
-
Как я могу поддерживать пользовательский рендеринг JTable Cell после редактирования ячейки?поддержание рендеринга Jtable Cell после редактирования ячейки в jtable, реализация пользовательских элементов рендеринга ячейки и редактирова...программирование Опубликовано в 2025-07-02
-
Можете ли вы использовать CSS для цветной консоли вывода в Chrome и Firefox?отображение цветов в консоли Javascript ] может ли использовать консоль Chrome для отображения цветного текста, такого как красный для ошибок, ...программирование Опубликовано в 2025-07-02
-
Как сортировать ключи от Javascript объекта в алфавитном порядке?Как сортировать объекты javascript по Key Если у вас есть объект JavaScript, вы можете реорганизовать его свойства алфавитно для улучшенных це...программирование Опубликовано в 2025-07-02
-
Как я могу эффективно генерировать удобные для URL слизняки из строк Unicode в PHP?создание функции для эффективной генерации Slug Создание слизняков, упрощенные представления строк Unicode, используемые в URL, может быть сло...программирование Опубликовано в 2025-07-02
-
Как я могу объединить таблицы базы данных с различным числом столбцов?объединенные таблицы с разными столбцами ] может столкнуться с проблемами при попытке объединить таблицы баз данных с разными столбцами. Просто...программирование Опубликовано в 2025-07-02
-
Как ограничить диапазон прокрутки элемента в родительском элементе динамического размера?реализация пределов высоты CSS для вертикальных элементов прокрутки В интерактивном интерфейсе, контроль над поведением прокрутки элементов яв...программирование Опубликовано в 2025-07-02
-
Ubuntu 12.04 MySQL Local Connection Руководство по исправлению ошибок подключенияпрограммирование Опубликовано в 2025-07-02
-
Как исправить \ "mysql_config не найдена \" Ошибка при установке MySQL-Python на Ubuntu/Linux?mysql-python error: "mysql_config не найдено" попытка установить Mysql-python на Ubuntu/linux box может столкнуться с сообщением об ...программирование Опубликовано в 2025-07-02
-
Как предотвратить дублирующие материалы после обновления формы?предотвращение дублирующих материалов с помощью обработки обновления В веб -разработке обычно встречается с проблемой дублирования материалов,...программирование Опубликовано в 2025-07-02
-
Как я могу синхронно повторять и печатать значения из двух массивов одинакового размера в PHP?синхронно итерационные и печатные значения из двух массивов одного и того же размера при создании Selectbox с использованием двух массивов одина...программирование Опубликовано в 2025-07-02















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









