 титульная страница > программирование > Извлечение данных из сложных PDF-файлов с помощью Google Gemini в строках Python
титульная страница > программирование > Извлечение данных из сложных PDF-файлов с помощью Google Gemini в строках Python
Извлечение данных из сложных PDF-файлов с помощью Google Gemini в строках Python
 Просматривать:671
Просматривать:671
В этом руководстве я покажу вам, как извлекать структурированные данные из PDF-файлов с помощью моделей визуального языка (VLM), таких как Gemini Flash или GPT-4o.
Gemini, последняя серия моделей визуального языка от Google, продемонстрировала высочайший уровень понимания текста и изображений. Эти улучшенные мультимодальные возможности и длинное контекстное окно делают его особенно полезным для обработки визуально сложных данных PDF, с которыми трудно справиться традиционным моделям извлечения, таких как рисунки, диаграммы, таблицы и диаграммы.
Таким образом, вы можете легко создать свой собственный инструмент извлечения данных для извлечения визуальных файлов и веб-страниц. Вот как:
Длинное контекстное окно и мультимодальные возможности Gemini делают его особенно полезным для обработки визуально сложных данных PDF, где традиционные модели извлечения не справляются.
Настройка среды
Прежде чем мы углубимся в извлечение, давайте настроим нашу среду разработки. В этом руководстве предполагается, что в вашей системе установлен Python. Если нет, загрузите и установите его с https://www.python.org/downloads/
⚠️ Обратите внимание: если вы не хотите использовать Python, вы можете использовать облачную платформу thepi.pe для загрузки файлов и скачивания результатов в формате CSV без написания кода.
Установите необходимые библиотеки
Откройте терминал или командную строку и выполните следующие команды:
pip install git https://github.com/emcf/thepipe pip install pandas
Для новичков в Python: pip — это установщик пакетов для Python, и эти команды загрузят и установят необходимые библиотеки.
Настройте свой ключ API
Чтобы использовать thepipe, вам понадобится ключ API.
Отказ от ответственности: thepi.pe — бесплатный инструмент с открытым исходным кодом, но стоимость API составляет примерно 0,00002 доллара США за токен. Если вы хотите избежать таких затрат, ознакомьтесь с инструкциями по локальной настройке на GitHub. Обратите внимание, что вам все равно придется платить выбранному вами поставщику LLM.
Вот как его получить и настроить:
- Посетите https://thepi.pe/platform/
- Создайте учетную запись или войдите в систему
- Найдите свой ключ API на странице настроек

Теперь вам нужно установить это как переменную среды. Этот процесс зависит от вашей операционной системы:
- Скопируйте ключ API из меню настроек на платформе thepi.pe
Для Windows:
- Найдите «Переменные среды» в меню «Пуск».
- Нажмите «Изменить переменные системной среды»
- Нажмите кнопку «Переменные среды»
- В разделе «Пользовательские переменные» нажмите «Создать»
- Установите имя переменной как THEPIPE_API_KEY, а значение — как ключ API
- Нажмите «ОК», чтобы сохранить
Для macOS и Linux:
Откройте терминал и добавьте следующую строку в файл конфигурации оболочки (например, ~/.bashrc или ~/.zshrc):
export THEPIPE_API_KEY=your_api_key_here
Затем перезагрузите конфигурацию:
source ~/.bashrc # or ~/.zshrc
Определение схемы извлечения
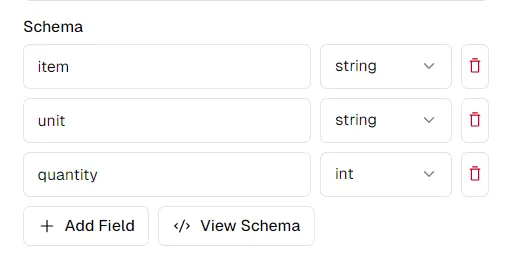
Ключом к успешному извлечению является определение четкой схемы данных, которые вы хотите извлечь. Допустим, мы извлекаем данные из документа ведомости объемов:

Пример страницы из документа «Количественная ведомость». Данные на каждой странице не зависят от других страниц, поэтому мы выполняем извлечение «постранично». На каждой странице необходимо извлечь несколько фрагментов данных, поэтому мы устанавливаем для нескольких извлечений значение True
Глядя на имена столбцов, мы можем извлечь такую схему:
schema = {
"item": "string",
"unit": "string",
"quantity": "int",
}
Вы можете изменить схему по своему вкусу на платформе thepi.pe. Нажав «Просмотреть схему», вы получите схему, которую вы можете скопировать и вставить для использования с API Python
Извлечение данных из PDF-файлов
Теперь давайте воспользуемся Extract_from_file для извлечения данных из PDF-файла:
from thepipe.extract import extract_from_file results = extract_from_file( file_path = "bill_of_quantity.pdf", schema = schema, ai_model = "google/gemini-flash-1.5b", chunking_method = "chunk_by_page" )
Здесь мы используем chunking_method="chunk_by_page", потому что мы хотим отправлять каждую страницу в модель искусственного интеллекта индивидуально (PDF слишком велик, чтобы передать все сразу). Мы также устанавливаем Multiple_extractions=True, поскольку каждая страница PDF содержит несколько строк данных. Вот как выглядит страница из PDF-файла:
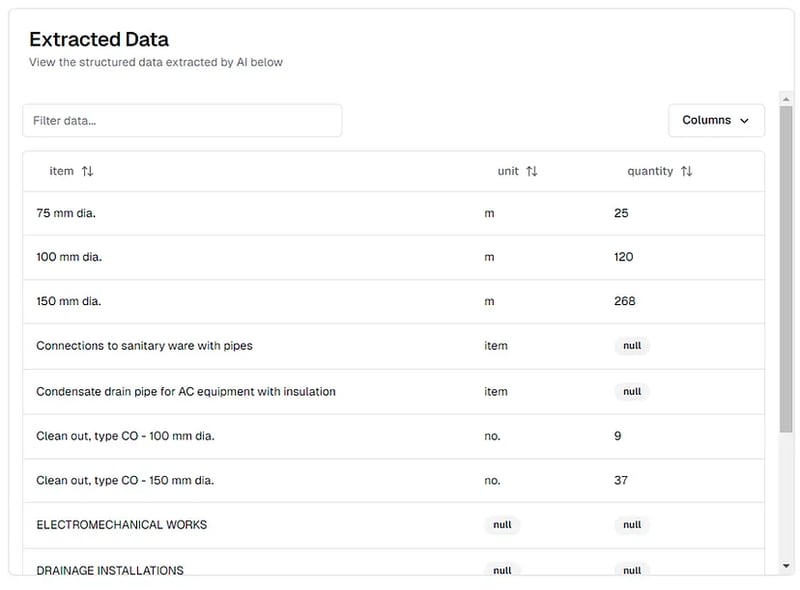
Результаты извлечения PDF-файла с объемами работ, просмотренные на платформе thepi.pe
Обработка результатов
Результаты извлечения возвращаются в виде списка словарей. Мы можем обработать эти результаты, чтобы создать DataFrame pandas:
import pandas as pd df = pd.DataFrame(results) # Display the first few rows of the DataFrame print(df.head())
При этом создается DataFrame со всей извлеченной информацией, включая текстовое содержимое и описания визуальных элементов, таких как рисунки и таблицы.
Экспорт в разные форматы
Теперь, когда у нас есть данные в DataFrame, мы можем легко экспортировать их в различные форматы. Вот несколько вариантов:
Экспорт в Excel
df.to_excel("extracted_research_data.xlsx", index=False, sheet_name="Research Data")
При этом создается файл Excel с именем «extracted_research_data.xlsx» и листом с именем «Данные исследования». Параметр index=False предотвращает включение индекса DataFrame в качестве отдельного столбца.
Экспорт в CSV
Если вы предпочитаете более простой формат, вы можете экспортировать в CSV:
df.to_csv("extracted_research_data.csv", index=False)
При этом создается файл CSV, который можно открыть в Excel или любом текстовом редакторе.
Заключительные примечания
Ключ к успешному извлечению лежит в определении четкой схемы и использовании мультимодальных возможностей модели ИИ. По мере того, как вы освоитесь с этими методами, вы сможете изучить более продвинутые функции, такие как настраиваемые методы фрагментирования, настраиваемые подсказки для извлечения и интеграцию процесса извлечения в более крупные конвейеры данных.
-
 Как я могу эффективно получить значения атрибутов из файлов XML с помощью PHP?получение значений атрибутов из файлов XML в php каждый разработчик сталкивается с необходимостью проанализировать файлы XML и извлекать опред...программирование Опубликовано в 2025-04-27
Как я могу эффективно получить значения атрибутов из файлов XML с помощью PHP?получение значений атрибутов из файлов XML в php каждый разработчик сталкивается с необходимостью проанализировать файлы XML и извлекать опред...программирование Опубликовано в 2025-04-27 -
Как получить фактический визуализированный шрифт в JavaScript, когда атрибут шрифта CSS не определен?доступ к фактическому визуализации, когда он не определен в CSS при доступе к свойствам шрифта элемента, javascript object.Style.fontfamily и ...программирование Опубликовано в 2025-04-27
-
Как я могу выполнить несколько операторов SQL в одном запросе с помощью Node-Mysql?Поддержка запросов с несколькими Statement в Node-Mysql в Node.js возникает вопрос, когда выполняется несколько SQL-записей в одном запросе, и...программирование Опубликовано в 2025-04-27
-
Как отправить необработанный запрос по почте с Curl в PHP?Как отправить необработанный запрос Post, используя Curl в php в PHP, Curl является популярной библиотекой для отправки HTTP -запросов. Эта ст...программирование Опубликовано в 2025-04-27
-
Почему Java не может создать общие массивы?enderic Mrue Creation Error Вопрос: ] при попытке создать массив общих классов, используя выражение: ArrayList [2]; public static ArrayLi...программирование Опубликовано в 2025-04-27
-
Могу ли я перенести свой шифрование с McRypt в OpenSSL и расшифровывает данные, заполненные McRypt, используя OpenSSL?Обновление моей библиотеки шифрования с McRypt до OpenSSL Могу ли я обновить свою библиотеку шифрования с McRypt до OpenSSL? В OpenSSL можно л...программирование Опубликовано в 2025-04-27
-
Как я могу настроить оптимизацию компиляции в компиляторе GO?настройка оптимизации компиляции в GO Compiler процесс компиляции по умолчанию в GO следует за конкретной стратегией оптимизации. Однако польз...программирование Опубликовано в 2025-04-27
-
Как извлечь элементы из 2D массива? Использование указателя другого массива, используя массив Numpy в качестве индексов для 2 -го измерения другого массива для извлечения специфических элементов из 2D -массива, основан...программирование Опубликовано в 2025-04-27
-
Как я могу поддерживать пользовательский рендеринг JTable Cell после редактирования ячейки?поддержание рендеринга Jtable Cell после редактирования ячейки в jtable, реализация пользовательских элементов рендеринга ячейки и редактирова...программирование Опубликовано в 2025-04-27
-
Какой метод более эффективен для обнаружения с точки зрения полигона: трассировка лучей или matplotlib \ path.contains_points?эффективное обнаружение с пунктом-в полигоне в Python определение того, находится ли точка в полигоне частой задачей в вычислительной геометрии....программирование Опубликовано в 2025-04-27
-
Разрешить исключение \\ "Ошибка строкового значения \\"разрешение исключения неверного строкового значения при вставке эмоджи при попытке вставить строку, содержащую символы эмоджи в базу данных mysq...программирование Опубликовано в 2025-04-27
-
Как извлечь случайный элемент из массива в PHP?случайный выбор из массива в php, получение случайного элемента из массива может быть выполнено с легкостью. Рассмотрим следующий массив: ] $ite...программирование Опубликовано в 2025-04-27
-
Почему Microsoft Visual C ++ не может правильно реализовать двухфазной экземпляры?загадка «Сломанная» двухфазное матричное экземпляры в Microsoft Visual C Задача: пользователи обычно выражают обеспокоенность Microsoft Visu...программирование Опубликовано в 2025-04-27
-
Как Android отправляет данные POST на PHP Server?Отправка данных в Android введение Эта статья рассматривает необходимость отправки данных в сценарий PHP и отобразить результат в приложен...программирование Опубликовано в 2025-04-27
-
Почему выполнение JavaScript прекращается при использовании кнопки Firefox Back?Проблема истории навигации: Javascript перестает выполнять после использования кнопки Firefox Back пользователи Firefox могут столкнуться с пр...программирование Опубликовано в 2025-04-26















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









