
Оценка модели классификации машинного обучения
 Просматривать:271
Просматривать:271
Контур
- Какова цель оценки модели?
- Какова цель оценки модели и какие общие процедуры оценки?
- Как используется точность классификации и каковы ее особенности? ограничения?
- Как матрица путаницы описывает эффективность классификатор?
- Какие показатели можно вычислить на основе матрицы путаницы?
Tцель оценки модели — ответить на вопрос;
как выбирать между разными моделями?
Процесс оценки машинного обучения помогает определить, насколько модель надежна и эффективна для ее применения. Это включает в себя оценку различных факторов, таких как производительность, показатели и точность прогнозов или принятия решений.
Независимо от того, какую модель вы решите использовать, вам нужен способ выбора между моделями: разные типы моделей, параметры настройки и функции. Также вам понадобится процедура оценки модели, чтобы оценить, насколько хорошо модель будет обобщаться на невидимые данные. Наконец, вам нужна процедура оценки, которая будет сочетаться с другой процедурой для количественной оценки эффективности вашей модели.
Прежде чем продолжить, давайте рассмотрим некоторые различные процедуры оценки моделей и то, как они работают.
Модельные процедуры оценки и как они работают.
-
Обучение и тестирование на одних и тех же данных
- Награждает слишком сложные модели, которые «подгоняют» обучающие данные и не обязательно обобщают
-
Разделение обучения/тестирования
- Разделите набор данных на две части, чтобы модель можно было обучить и протестировать на разных данных
- Лучшая оценка эффективности за пределами выборки, но все же оценка с «высокой дисперсией»
- Полезно благодаря скорости, простоте и гибкости
-
K-кратная перекрестная проверка
- Систематически создавайте K-разделения поездов/тестов и усредняйте результаты вместе
- Еще лучшая оценка эффективности за пределами выборки
- Выполняется в «K» раз медленнее, чем разделение поезд/тест.
Из вышесказанного мы можем сделать следующий вывод:
Обучение и тестирование на одних и тех же данных — это классическая причина переобучения, при которой вы строите слишком сложную модель, которая не обобщается на новые данные и на самом деле бесполезна.
Train_Test_Split обеспечивает гораздо лучшую оценку производительности за пределами выборки.
K-кратная перекрестная проверка более эффективна за счет систематического разделения тестов K-поезда и усреднения результатов вместе.
Подводя итог, можно сказать, что train_tests_split по-прежнему выгоден для перекрестной проверки благодаря своей скорости и простоте, и именно это мы и будем использовать в этом учебном руководстве.
Показатели оценки модели:
Вам всегда понадобится метрика оценки, соответствующая выбранной вами процедуре, и ваш выбор метрики зависит от проблемы, которую вы решаете. Для задач классификации вы можете использовать точность классификации. Но в этом руководстве мы сосредоточимся на других важных показателях оценки классификации.
Прежде чем мы изучим какие-либо новые показатели оценки, давайте рассмотрим точность классификации и поговорим о ее сильных и слабых сторонах.
Точность классификации
Для этого руководства мы выбрали набор данных о диабете индейцев пима, который включает данные о состоянии здоровья и статусе диабета 768 пациентов.
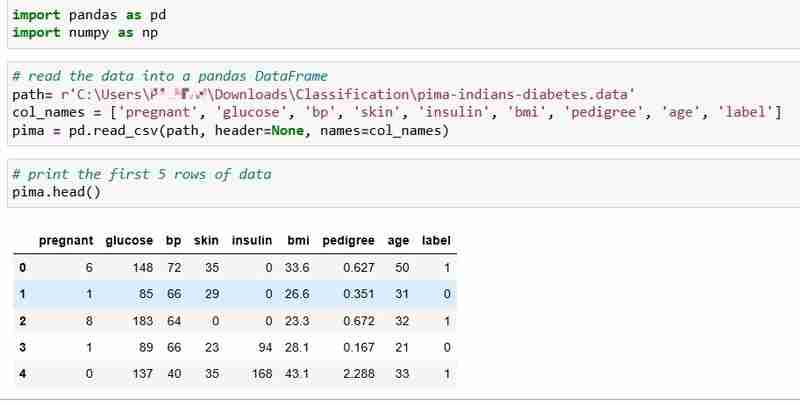
Давайте прочитаем данные и распечатаем первые 5 строк данных. В столбце метки указано 1, если у пациента диабет, и 0, если у пациента нет диабета, и мы намерены ответить на вопрос:
Вопрос: Можем ли мы предсказать статус диабета пациента, учитывая его показатели здоровья?
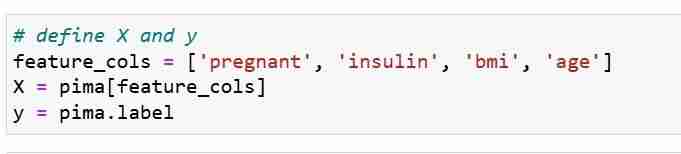
Мы определяем метрики наших функций X и вектор ответа Y. Мы используем train_test_split, чтобы разделить X и Y на наборы для обучения и тестирования.
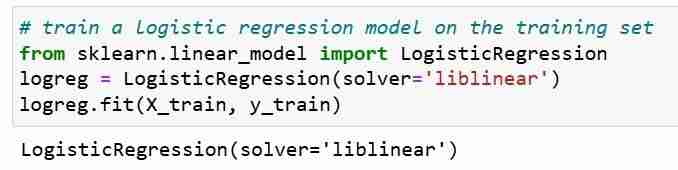
Далее мы обучаем модель логистической регрессии на обучающем наборе. На этапе подгонки объект модели logreg изучает взаимосвязь между X_train и Y_train. Наконец, мы делаем прогнозы классов для тестовых наборов.

Теперь, когда мы сделали прогноз для тестового набора, мы можем вычислить точность классификации, которая представляет собой просто процент правильных прогнозов.
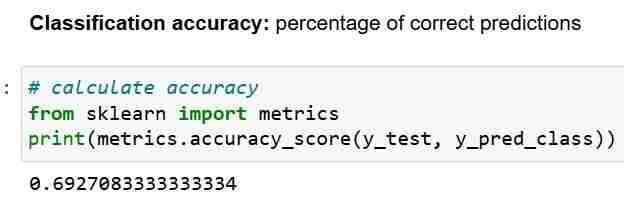
Однако каждый раз, когда вы используете точность классификации в качестве показателя оценки, важно сравнивать ее с Нулевой точностью, которая представляет собой точность, которой можно достичь, всегда прогнозируя наиболее часто встречающийся класс.

Нулевая точность отвечает на вопрос; если бы моя модель предсказывала преобладающий класс в 100 процентах случаев, как часто она была бы верной? В приведенном выше сценарии 32% числа y_test равны 1 (единицам). Другими словами, глупая модель, предсказывающая, что у пациентов диабет, будет верной в 68% случаев (что равно нулям). Это обеспечивает базовый уровень, относительно которого мы могли бы измерить нашу логистическую регрессию. модель.
Когда мы сравниваем нулевую точность 68% и точность модели 69%, наша модель выглядит не очень хорошо. Это демонстрирует один из недостатков точности классификации как показателя оценки модели. Точность классификации ничего не говорит нам о базовом распределении тестового теста.
В итоге:
- Точность классификации — это самый простой для понимания показатель классификации
- Но он не сообщает вам основное распределение значений ответа
- И он не сообщает вам, какие "типы" ошибок делает ваш классификатор.
Теперь посмотрим на матрицу путаницы.
Матрица путаницы
Матрица путаницы — это таблица, описывающая эффективность модели классификации.
Это полезно, чтобы помочь вам понять производительность вашего классификатора, но это не показатель оценки модели; так что вы не можете сказать scikit научиться выбирать модель с лучшей матрицей путаницы. Однако существует множество показателей, которые можно рассчитать на основе матрицы путаницы и напрямую использовать для выбора между моделями.
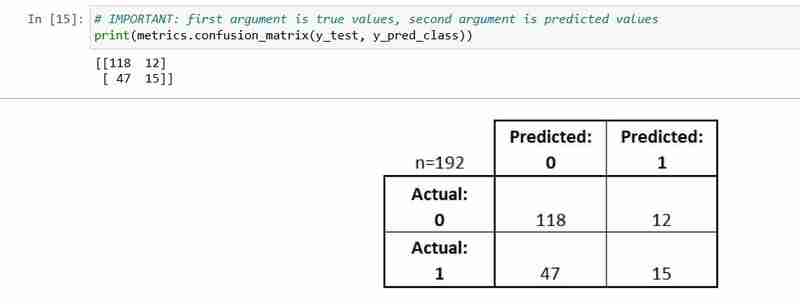
- Каждое наблюдение в тестовом наборе представлено в ровно одном блоке
- Это матрица 2x2, поскольку существует 2 класса ответов
- Показанный здесь формат не универсальный
Давайте объясним некоторые основные термины.
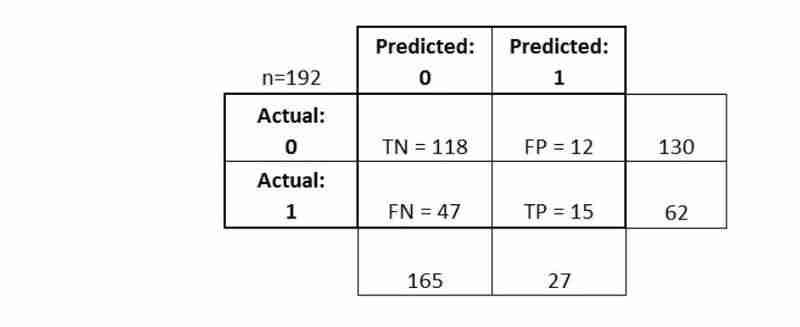
- Истинно положительные результаты (TP): мы правильно предсказали, что у них действительно диабет
- Истинно отрицательные значения (TN): мы правильно предсказали, что у них нет диабета
- Ложноположительные результаты (FP): мы неверно предсказали, что у них действительно диабет («ошибка I типа»)
- Ложноотрицательные результаты (FN): мы неправильно предсказали, что у них нет диабета («ошибка II типа»)
Давайте посмотрим, как можно рассчитать метрики


В заключение:
- Матрица путаницы дает вам более полную картину эффективности вашего классификатора
- Также позволяет рассчитывать различные показатели классификации, и эти показатели могут помочь при выборе модели
-
 Объект: обложка не удается в IE и Edge, как исправить?object-fit: cover не удастся в IE и Edge, как исправить? В CSS для поддержания постоянной высоты изображения работает беспрепятственно через брау...программирование Опубликовано в 2025-07-04
Объект: обложка не удается в IE и Edge, как исправить?object-fit: cover не удастся в IE и Edge, как исправить? В CSS для поддержания постоянной высоты изображения работает беспрепятственно через брау...программирование Опубликовано в 2025-07-04 -
Как упростить анализ JSON в PHP для многомерных массивов?sacksing json с php пытаться анализировать данные JSON в PHP может быть сложной, особенно при работе с многомерными массивами. Чтобы упростить п...программирование Опубликовано в 2025-07-04
-
Как избежать утечек памяти при наречном языке?утечка памяти в срезах Go Понимание утечек памяти в ломтиках Go может быть вызовом. Эта статья направлена на то, чтобы дать разъяснение, изу...программирование Опубликовано в 2025-07-04
-
Как сортировать ключи от Javascript объекта в алфавитном порядке?Как сортировать объекты javascript по Key Если у вас есть объект JavaScript, вы можете реорганизовать его свойства алфавитно для улучшенных це...программирование Опубликовано в 2025-07-04
-
Методы доступа и управления переменными среды Pythonдоступа к переменным среды в Python для доступа к переменным среды в Python Использовать os.environ объект, который представляет картировани...программирование Опубликовано в 2025-07-04
-
Нужно ли мне явно удалить распределения кучи в C ++ до выхода программы?явное удаление в C, несмотря на exit программы При работе с распределением динамической памятью в C разработчики часто задаются вопросом, необ...программирование Опубликовано в 2025-07-04
-
Почему Firefox отображает изображения, используя свойство CSS `content`?отображение изображений с URL содержимого в Firefox возникала проблема, где некоторые браузеры, в частности, Firefox, не отображаются изображе...программирование Опубликовано в 2025-07-04
-
Разрешает ли Java несколько типов возврата: более пристальный взгляд на общие методы?множественные типы возврата в Java: a miscessception presvelired в сфере программирования Java, может возникнуть признание метода, оставляя ра...программирование Опубликовано в 2025-07-04
-
Как эффективно изменить атрибут CSS «: после» псевдоэлемента с использованием jQuery?понимание ограничений псевдо-элементов в jQuery: доступ к ": после" selector в веб-разработке, псевдо-элементы, такие как ": по...программирование Опубликовано в 2025-07-04
-
Как я могу эффективно прочитать большой файл в обратном порядке с помощью Python?Чтение файла в обратном порядке в Python Если вы работаете с большим файлом, и вам необходимо прочитать его содержимое с последней строки до п...программирование Опубликовано в 2025-07-04
-
Как я могу эффективно получить значения атрибутов из файлов XML с помощью PHP?получение значений атрибутов из файлов XML в php каждый разработчик сталкивается с необходимостью проанализировать файлы XML и извлекать опред...программирование Опубликовано в 2025-07-04
-
Как эффективно повторить строковые символы для вдавления в C#?повторяя строку для вдавления , когда обрабатывает строку, основанную на глубине элемента, удобно иметь эффективный способ вернуть строку, повт...программирование Опубликовано в 2025-07-04
-
Как я могу настроить оптимизацию компиляции в компиляторе GO?настройка оптимизации компиляции в GO Compiler процесс компиляции по умолчанию в GO следует за конкретной стратегией оптимизации. Однако польз...программирование Опубликовано в 2025-07-04
-
Эффективный метод проверки для струн Java, которые не являются пустыми и не нулевыми, если строка не является нулевой и не пустой , чтобы определить, не является ли строка не нулевой и не пустой, Java предоставляет различные мет...программирование Опубликовано в 2025-07-04
-
Почему изображения все еще имеют границы в Chrome? `Граница: нет;` НЕПРАВИЛЬНОЕ РЕШЕНИЕ] Удаление границы изображения в Chrome . Одна частая проблема, встречающаяся при работе с изображениями в Chrome, и IE9 - это появление постоян...программирование Опубликовано в 2025-07-04















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









