
ETL: извлечение имени человека из текста
 Просматривать:354
Просматривать:354
Допустим, мы хотим парсить chicagomusiccompass.com.
Как видите, в нем есть несколько карточек, каждая из которых представляет какое-то событие. Теперь давайте проверим следующее:
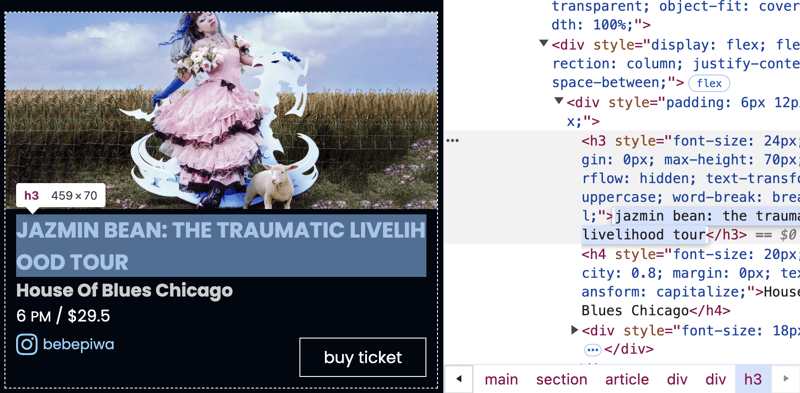
Обратите внимание, что название мероприятия:
jazmin bean: the traumatic livelihood tour
Итак, теперь вопрос: Как извлечь имя исполнителя из текста?
Как человек, я могу «легко» сказать, что Джазмин Бин — художник — просто загляните на их вики-страницу. Но написать код для извлечения этого имени может оказаться непросто.
Мы могли бы подумать: «Эй, что-нибудь перед : должно быть именем исполнителя», что кажется умным, не так ли? В этом случае это работает, а как насчет этого:
happy hour on the patio: kathryn & chris
Здесь порядок перевернут. Мы могли бы продолжать добавлять логику для обработки разных случаев, но вскоре мы получим массу хрупких правил, которые, вероятно, не охватят всего.
Именно здесь могут пригодиться модели Распознавания именованных объектов (NER). Они имеют открытый исходный код и могут помочь нам извлекать имена из текста. Он не сможет отследить все случаи, но в большинстве случаев они предоставят нам необходимую информацию.
Благодаря такому подходу извлечение данных становится намного проще. Я выбираю Python, потому что сообщество, занимающееся машинным обучением на Python, просто непобедимо.
from gliner import GLiNER
model = GLiNER.from_pretrained("urchade/gliner_base")
text = "jazmin bean: the traumatic livelihood tour"
labels = ["person", "bands", "projects"]
entities = model.predict_entities(text, labels)
for entity in entities:
print(entity["text"], "=>", entity["label"])
Что генерирует выходные данные:
jazmin bean => person
Теперь давайте посмотрим на другой случай:
happy hour on the patio: kathryn & chris
Выход:
kathryn => person chris => person
источник-GLiNER
Потрясающе, правда? Больше никакой утомительной логики для извлечения имен, просто используйте модель. Конечно, он не охватывает все возможные случаи, но для моего проекта такой уровень гибкости вполне подходит. Если вам нужна большая точность, вы всегда можете:
- Попробуйте другую модель
- Внести вклад в существующую модель
- Развивите проект и настройте его под свои нужды
Заключение
Разработчику программного обеспечения настоятельно рекомендуется быть в курсе инструментов в области машинного обучения. Не все можно решить с помощью простого программирования и логики — некоторые задачи лучше решать с помощью моделей и статистики.
-
 Как удалить префикс «data-» из строк с помощью JavaScriptУдаление префиксов из строк: удаление «данных-»Многие задачи программирования включают манипулирование строками. Одной из распространенных задач являе...программирование Опубликовано 7 ноября 2024 г.
Как удалить префикс «data-» из строк с помощью JavaScriptУдаление префиксов из строк: удаление «данных-»Многие задачи программирования включают манипулирование строками. Одной из распространенных задач являе...программирование Опубликовано 7 ноября 2024 г. -
## Как эффективно профилировать использование памяти PHP: альтернативы и лучшие практики XdebugАнализ потребления памяти PHPВы ищете способ тщательно изучить использование памяти PHP-страницей. В частности, вы стремитесь определить распределение...программирование Опубликовано 7 ноября 2024 г.
-
Как компоненты визуализируются в виртуальном DOM и как оптимизировать повторный рендерингПри создании современных веб-приложений эффективное обновление пользовательского интерфейса (пользовательский интерфейс) имеет важное значение для обе...программирование Опубликовано 7 ноября 2024 г.
-
Операции CRUD: что это такое и как их использовать?Операции CRUD: что это такое и как их использовать? Операции CRUD — создание, чтение, обновление и удаление — являются фундаментальными для л...программирование Опубликовано 7 ноября 2024 г.
-
Представляем бесплатный пакет утилит JavaБыстрый и простой в использовании набор инструментов программирования для разработчиков серверной части Java За свою профессиональную жизнь администра...программирование Опубликовано 7 ноября 2024 г.
-
Как получить ключи массива в цикле PHP foreach для вложенных массивов?PHP: получение ключей массива в цикле foreachВ PHP итерация по ассоциативному массиву с использованием цикла foreach обеспечивает доступ к обоим значе...программирование Опубликовано 7 ноября 2024 г.
-
Как преобразовать символы Latin1 в UTF-8 в таблице MySQL?Преобразовать символы Latin1 в таблице UTF8 в UTF8Вы обнаружили, что в ваших PHP-скриптах отсутствует необходимая функция mysql_set_charset для обеспе...программирование Опубликовано 7 ноября 2024 г.
-
Как использовать Zapcap API (API для субтитров)Интеграция API ZapCap для автоматической обработки видео в существующие системы — это простой процесс, призванный минимизировать сложность и максимизи...программирование Опубликовано 7 ноября 2024 г.
-
Изучите компоненты начальной загрузкиBootstrap 5, одна из самых популярных интерфейсных платформ, содержит ряд полезных компонентов и утилит, которые помогают разработчикам быстро создава...программирование Опубликовано 7 ноября 2024 г.
-
Упрощение управления SVG: преобразование путей в один JS-файл константПри создании приложений React.js эффективное управление значками SVG имеет решающее значение. SVG обеспечивает масштабируемость и гибкость, необходимы...программирование Опубликовано 7 ноября 2024 г.
-
Как позаботиться о структуре кода JavaScriptХорошо! Поддержание чистой и организованной базы кода JavaScript имеет важное значение для долгосрочного успеха проекта. Хорошо структурированная кодо...программирование Опубликовано 7 ноября 2024 г.
-
Можно ли настроить переполнение для потока влево?Можно ли настроить переполнение для перемещения влево?Переполнение обычно устраняется путем принудительного перемещения содержимого вправо, в результа...программирование Опубликовано 7 ноября 2024 г.
-
В чем принципиальная разница между и ?программирование Опубликовано 7 ноября 2024 г.
-
Как объединить массивы NumPy с разными типами данных, сохраняя типы данных?Объединение массивов с несколькими типами данных в NumPyЖелание объединить массивы, содержащие разные типы данных, в один массив с соответствующими ти...программирование Опубликовано 7 ноября 2024 г.
-
Как выровнять строчные блоки по горизонтали на одной линии?Выравнивание строковых блоков по горизонтали на одной линииПроблемаИнлайн-блоки имеют преимущества перед плавающими элементами, такие как выравнивание...программирование Опубликовано 7 ноября 2024 г.















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









