
Как загрузить и установить Llama 2 локально
 Просматривать:503
Просматривать:503
Имея это в виду, мы создали пошаговое руководство о том, как использовать Text-Generation-WebUI для загрузки квантованного Llama 2 LLM локально на ваш компьютер.
Зачем устанавливать Llama 2 локально
Есть много причин, по которым люди предпочитают запускать Llama 2 напрямую. Некоторые делают это из соображений конфиденциальности, некоторые — для настройки, а третьи — для работы в автономном режиме. Если вы исследуете, настраиваете или интегрируете Llama 2 в свои проекты, то доступ к Llama 2 через API может вам не подойти. Смысл локального запуска LLM на вашем ПК состоит в том, чтобы уменьшить зависимость от сторонних инструментов искусственного интеллекта и использовать искусственный интеллект в любое время и в любом месте, не беспокоясь об утечке потенциально конфиденциальных данных компаниям и другим организациям.
С учетом сказанного, давайте начнем с пошагового руководства по локальной установке Llama 2.
Шаг 1. Установите инструмент сборки Visual Studio 2019
Чтобы упростить задачу, мы будем использовать установщик Text-Generation-WebUI (программы, используемой для загрузки Llama 2 с графическим интерфейсом) в один клик. . Однако для работы этого установщика необходимо загрузить Visual Studio 2019 Build Tool и установить необходимые ресурсы.
Скачать:Visual Studio 2019 (бесплатно)
Загрузите версию программного обеспечения для сообщества. Теперь установите Visual Studio 2019 и откройте программное обеспечение. После открытия установите флажок «Разработка настольных компьютеров на C» и нажмите «Установить».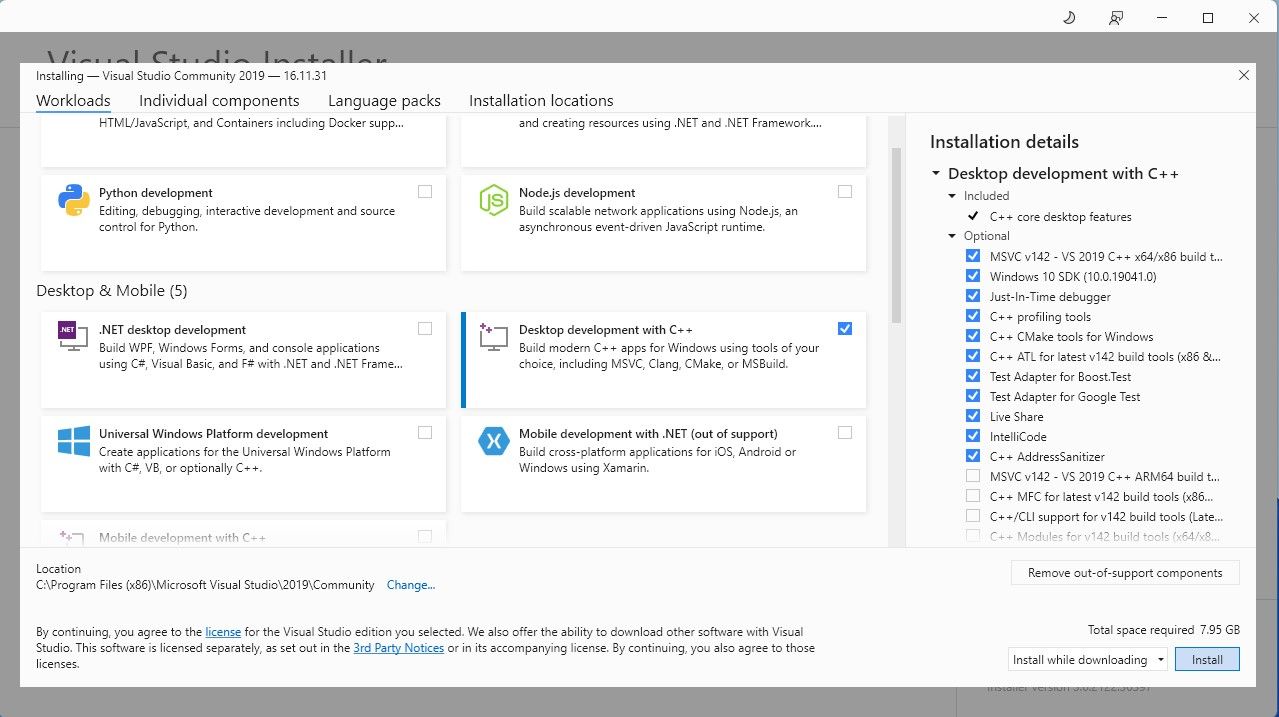
Теперь, когда у вас установлена разработка настольных компьютеров на C, пришло время загрузить установщик Text-Generation-WebUI в один клик.
Шаг 2. Установите Text-Generation-WebUI
Программа установки Text-Generation-WebUI в один клик представляет собой сценарий, который автоматически создает необходимые папки и настраивает среду Conda и все необходимые требования. для запуска модели ИИ.
Чтобы установить скрипт, загрузите установщик в один клик, нажав «Код» > «Загрузить ZIP».
Загрузка:Установщик Text-Generation-WebUI (бесплатно)
После загрузки извлеките ZIP-файл в нужное вам место, а затем откройте извлеченную папку. В папке прокрутите вниз и найдите подходящую стартовую программу для вашей операционной системы. Запустите программы, дважды щелкнув соответствующий скрипт. Если вы используете Windows, выберите пакетный файл start_windows для MacOS, выберите сценарий оболочки start_macos для Linux, сценарий оболочки start_linux.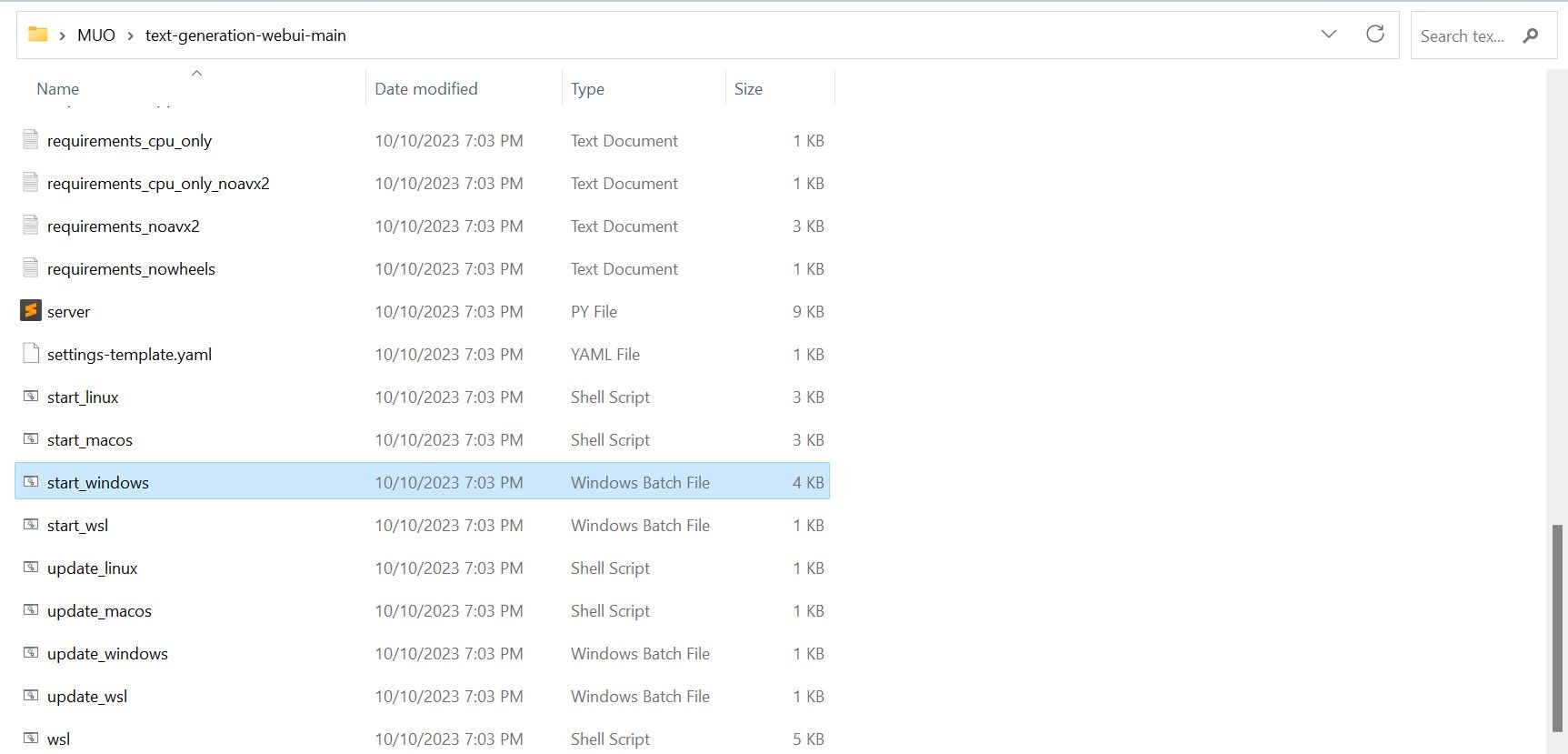
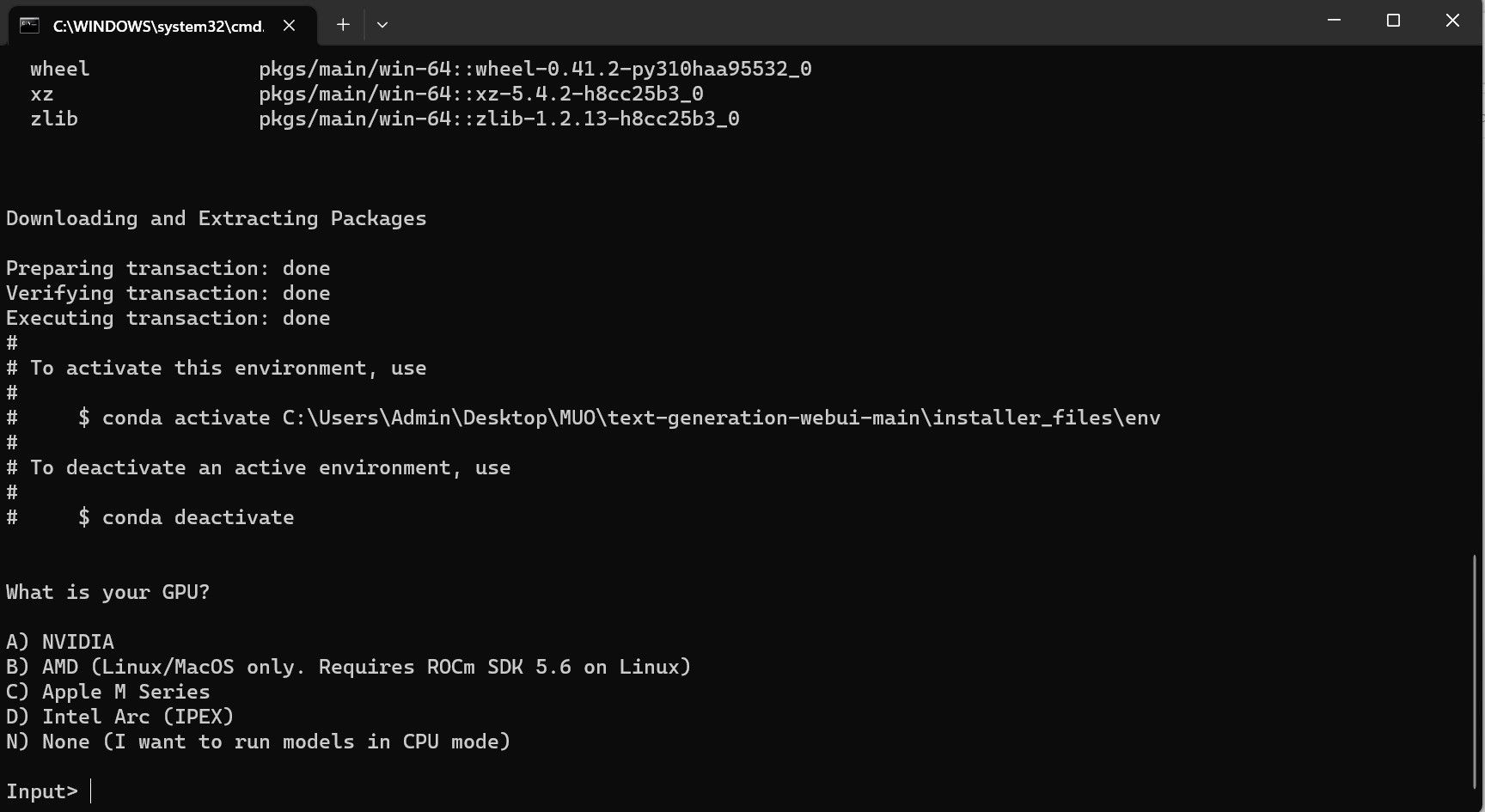
Ваш антивирус может создать предупреждение; это нормально. Подсказка — это просто ложное срабатывание антивируса при запуске командного файла или сценария. Нажмите «Выполнить в любом случае». Откроется терминал и начнется установка. Вначале установка приостановится и спросит вас, какой графический процессор вы используете. Выберите подходящий тип графического процессора, установленного на вашем компьютере, и нажмите Enter. Для тех, у кого нет выделенной видеокарты, выберите «Нет» (я хочу запускать модели в режиме ЦП). Имейте в виду, что работа в режиме ЦП происходит намного медленнее по сравнению с работой модели с выделенным графическим процессором.
 После завершения настройки вы можете запустить Text-Generation-WebUI локально. Вы можете сделать это, открыв предпочитаемый веб-браузер и введя указанный IP-адрес в URL-адресе.
После завершения настройки вы можете запустить Text-Generation-WebUI локально. Вы можете сделать это, открыв предпочитаемый веб-браузер и введя указанный IP-адрес в URL-адресе.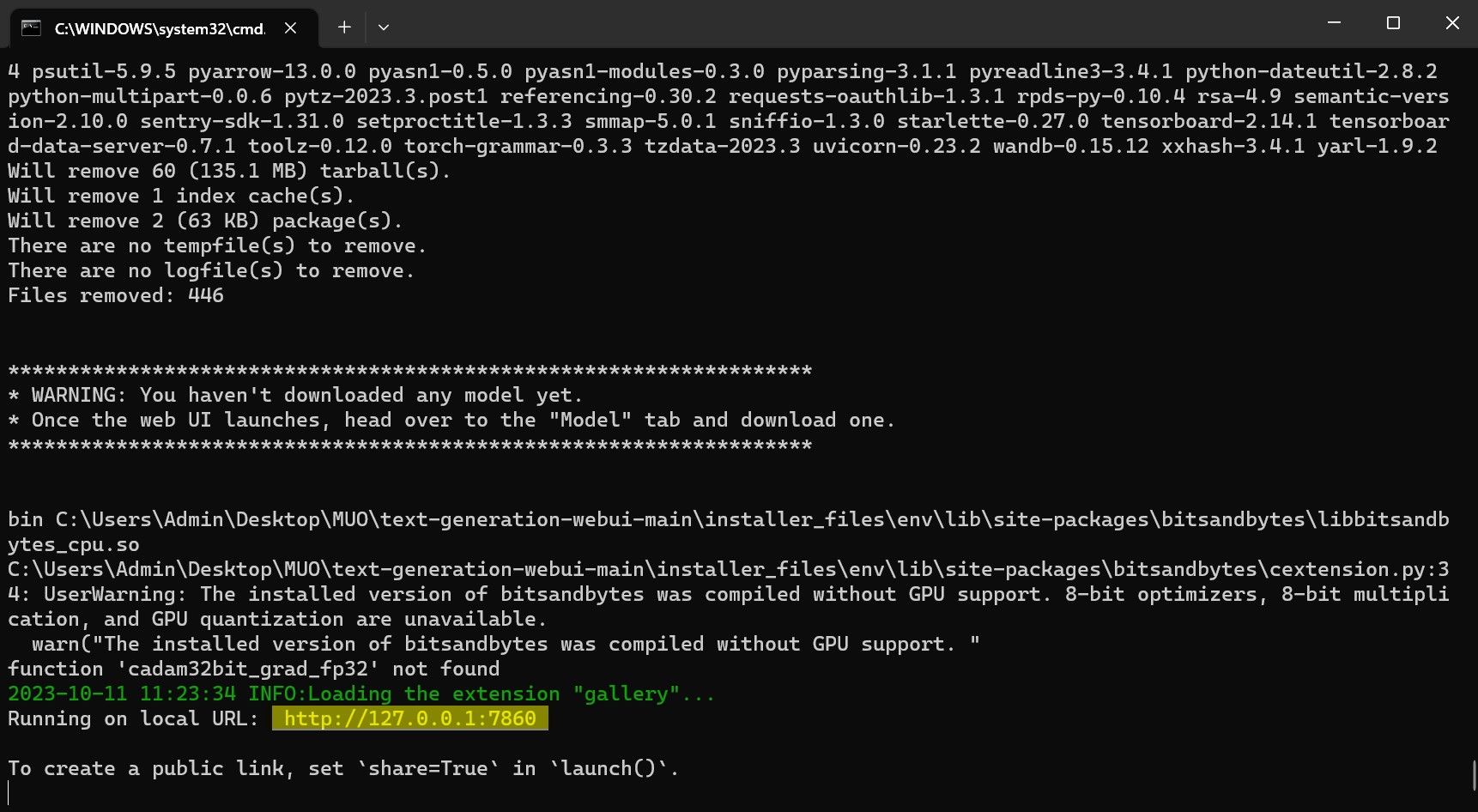 Теперь веб-интерфейс готов к использованию.
Теперь веб-интерфейс готов к использованию.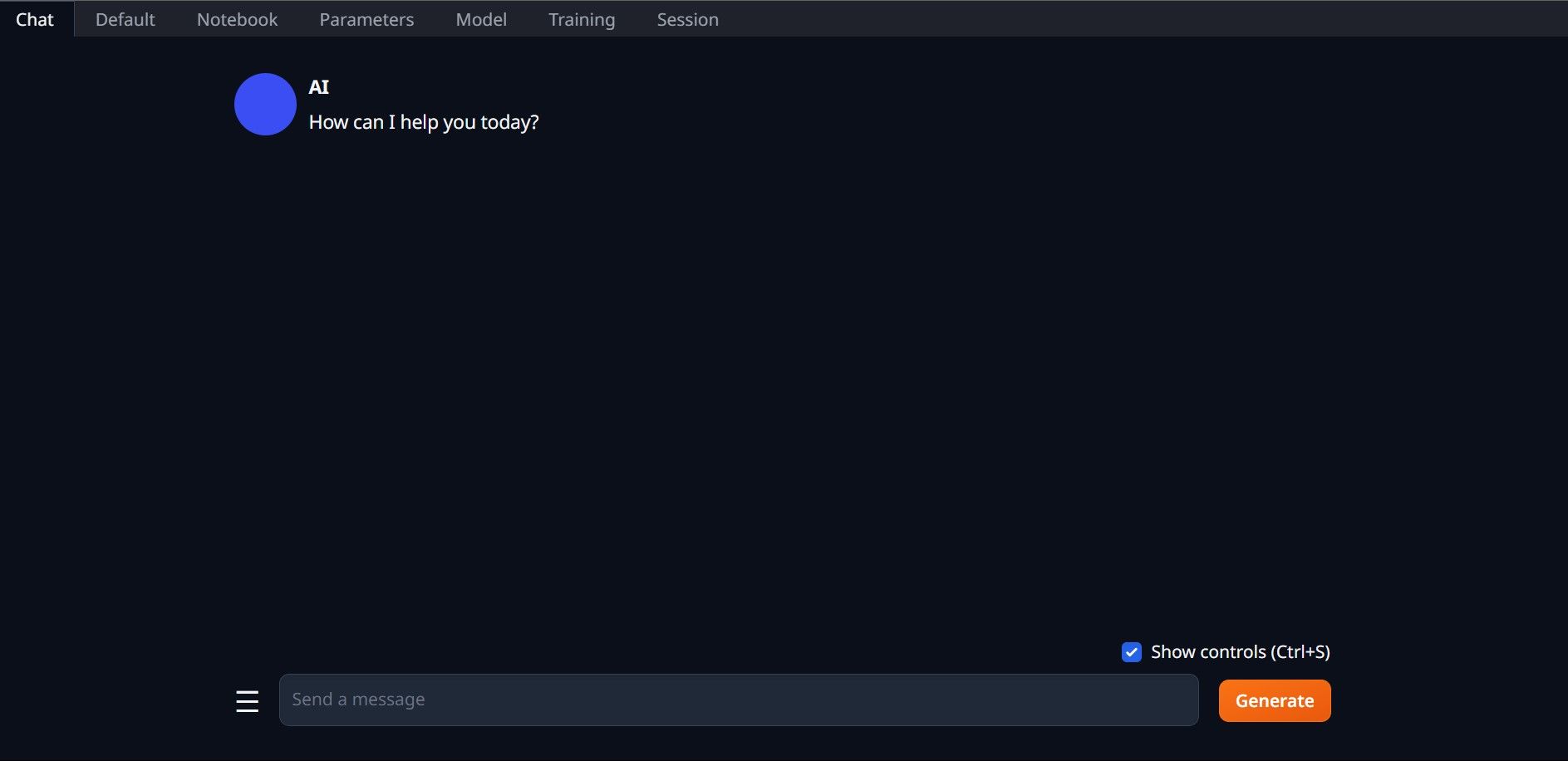
Однако программа представляет собой всего лишь загрузчик модели. Давайте скачаем Llama 2 для запуска загрузчика моделей.
Шаг 3. Загрузите модель Llama 2
При принятии решения о том, какая версия Llama 2 вам нужна, необходимо учитывать немало факторов. К ним относятся параметры, квантование, оптимизация оборудования, размер и использование. Вся эта информация будет указана в названии модели.
Параметры: количество параметров, используемых для обучения модели. Большие параметры делают модели более функциональными, но за счет производительности. Использование: Может быть стандартным или чатом. Модель чата оптимизирована для использования в качестве чат-бота, например ChatGPT, тогда как стандартной является модель по умолчанию. Оптимизация оборудования: относится к тому, какое оборудование лучше всего работает с моделью. GPTQ означает, что модель оптимизирована для работы на выделенном графическом процессоре, а GGML оптимизирован для работы на центральном процессоре. Квантование: обозначает точность весов и активаций в модели. Для вывода оптимальна точность q4. Размер: Относится к размеру конкретной модели.Обратите внимание, что некоторые модели могут быть устроены по-разному и могут даже отображать разные типы информации. Однако этот тип соглашения об именах довольно распространен в библиотеке модели HuggingFace, поэтому его все же стоит понять.

В этом примере модель можно идентифицировать как модель Llama 2 среднего размера, обученную на 13 миллиардах параметров, оптимизированную для вывода чата с использованием выделенного ЦП.
Для тех, кто работает на выделенном графическом процессоре, выберите модель GPTQ, а для тех, кто использует ЦП, выберите GGML. Если вы хотите общаться с моделью так же, как с ChatGPT, выберите чат, но если вы хотите поэкспериментировать с моделью со всеми ее возможностями, используйте стандартную модель. Что касается параметров, знайте, что использование более крупных моделей обеспечит лучшие результаты за счет производительности. Лично я бы рекомендовал вам начать с модели 7B. Что касается квантования, используйте q4, поскольку он предназначен только для вывода.
Загрузка:GGML (бесплатно)
Загрузка:GPTQ (бесплатно)
Теперь, когда вы знаете, какая версия Llama 2 вам нужна, скачайте нужную модель. .
В моем случае, поскольку я запускаю это на ультрабуке, я буду использовать модель GGML, настроенную для чата, llama-2-7b-chat-ggmlv3.q4_K_S.bin.
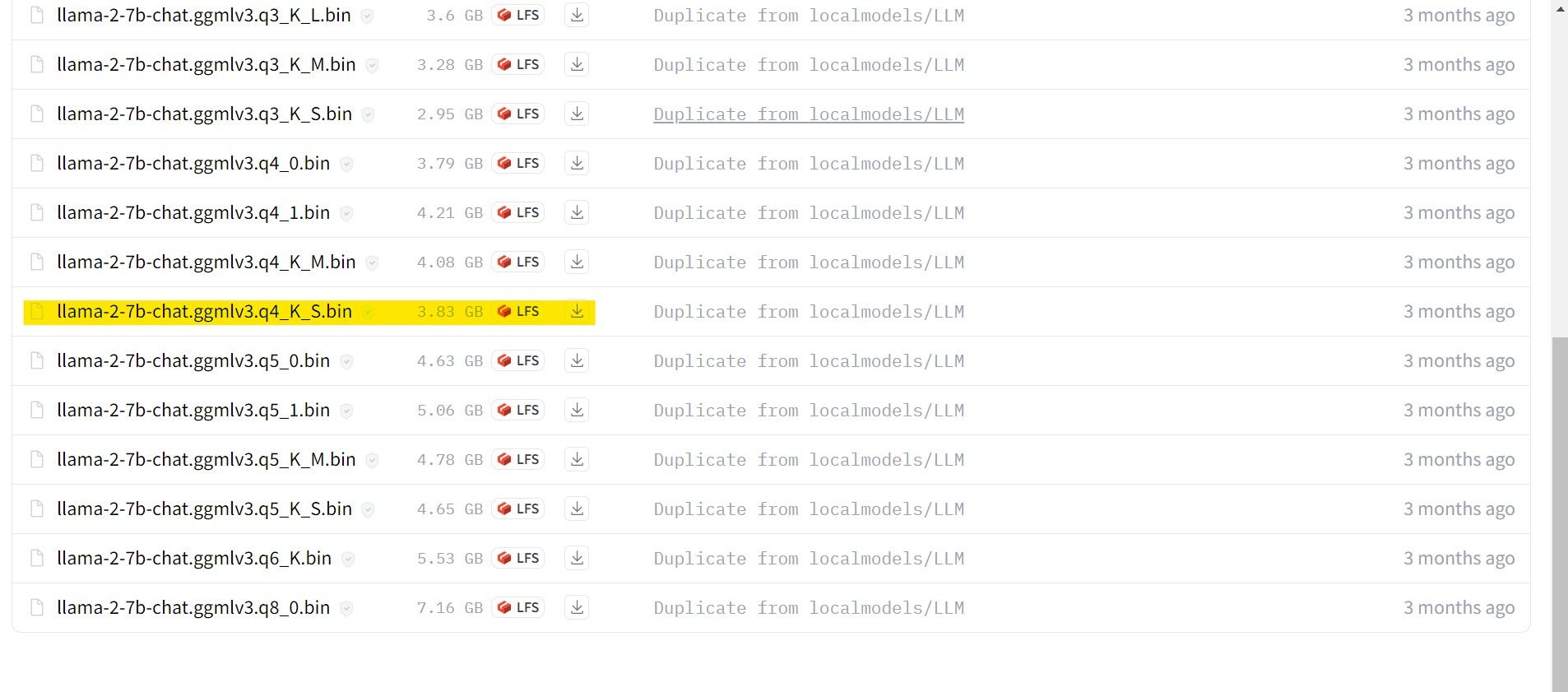
После завершения загрузки поместите модель в text-generation-webui-main > models.
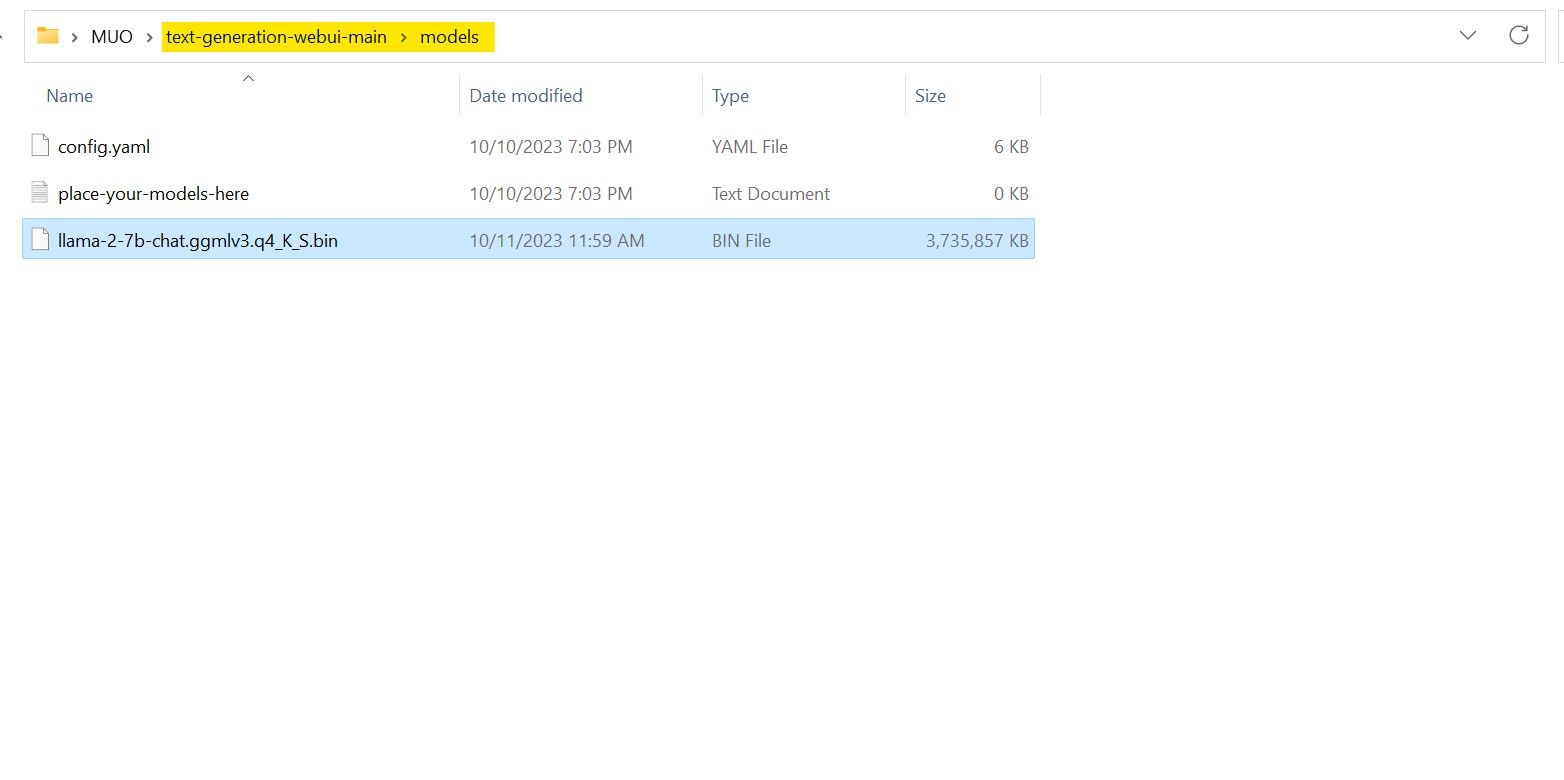
Теперь, когда ваша модель загружена и помещена в папку модели, пришло время настроить загрузчик модели.
Шаг 4. Настройка Text-Generation-WebUI
Теперь приступим к этапу настройки.
Еще раз откройте Text-Generation-WebUI, запустив файл start_(вашей ОС) (см. предыдущие шаги выше). На вкладках, расположенных над графическим интерфейсом, нажмите «Модель». Нажмите кнопку обновления в раскрывающемся меню модели и выберите свою модель. Теперь щелкните раскрывающееся меню загрузчика модели и выберите AutoGPTQ для тех, кто использует модель GTPQ, и ctransformers для тех, кто использует модель GGML. Наконец, нажмите «Загрузить», чтобы загрузить вашу модель.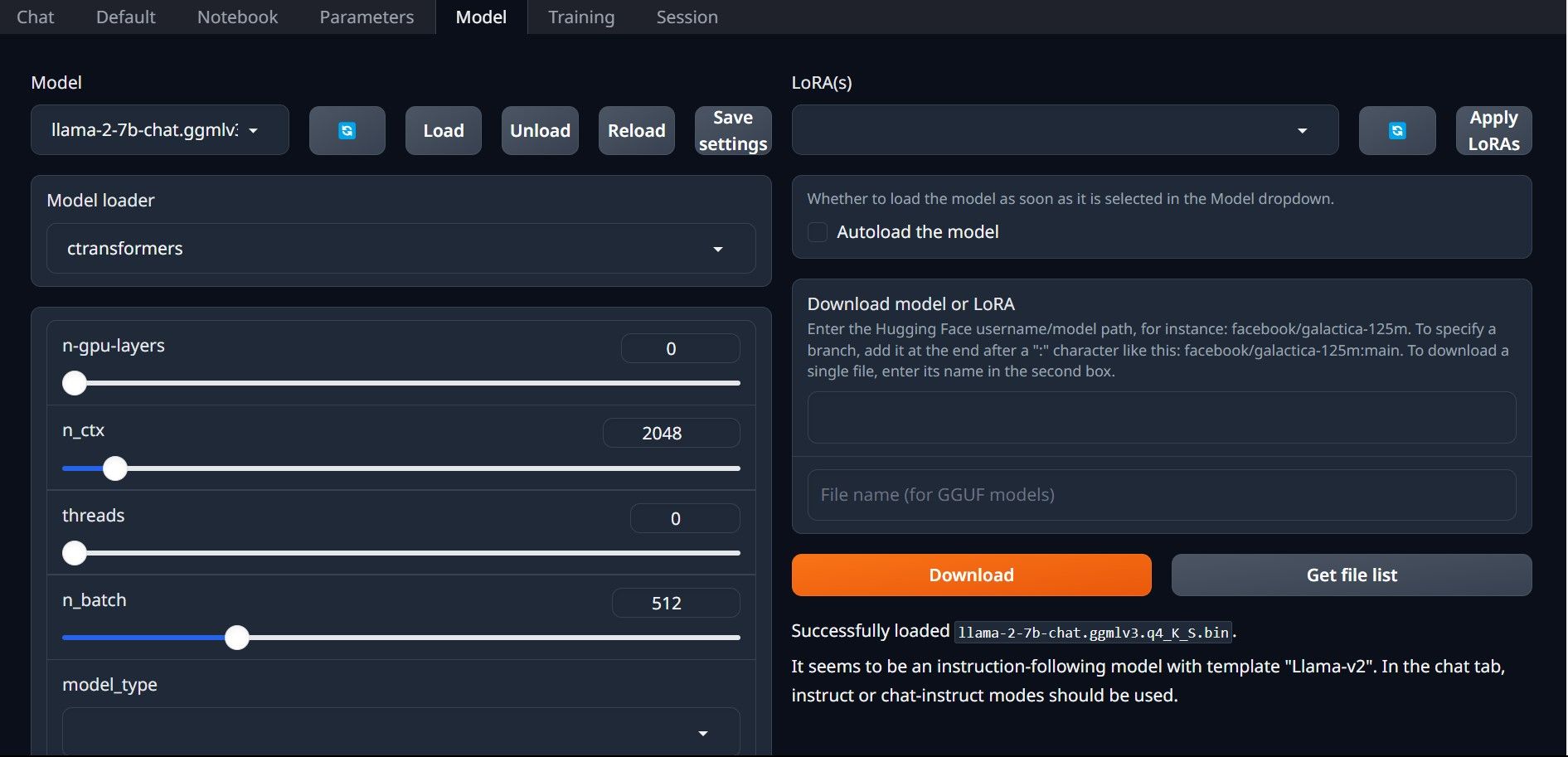 Чтобы использовать модель, откройте вкладку «Чат» и начните тестирование модели.
Чтобы использовать модель, откройте вкладку «Чат» и начните тестирование модели.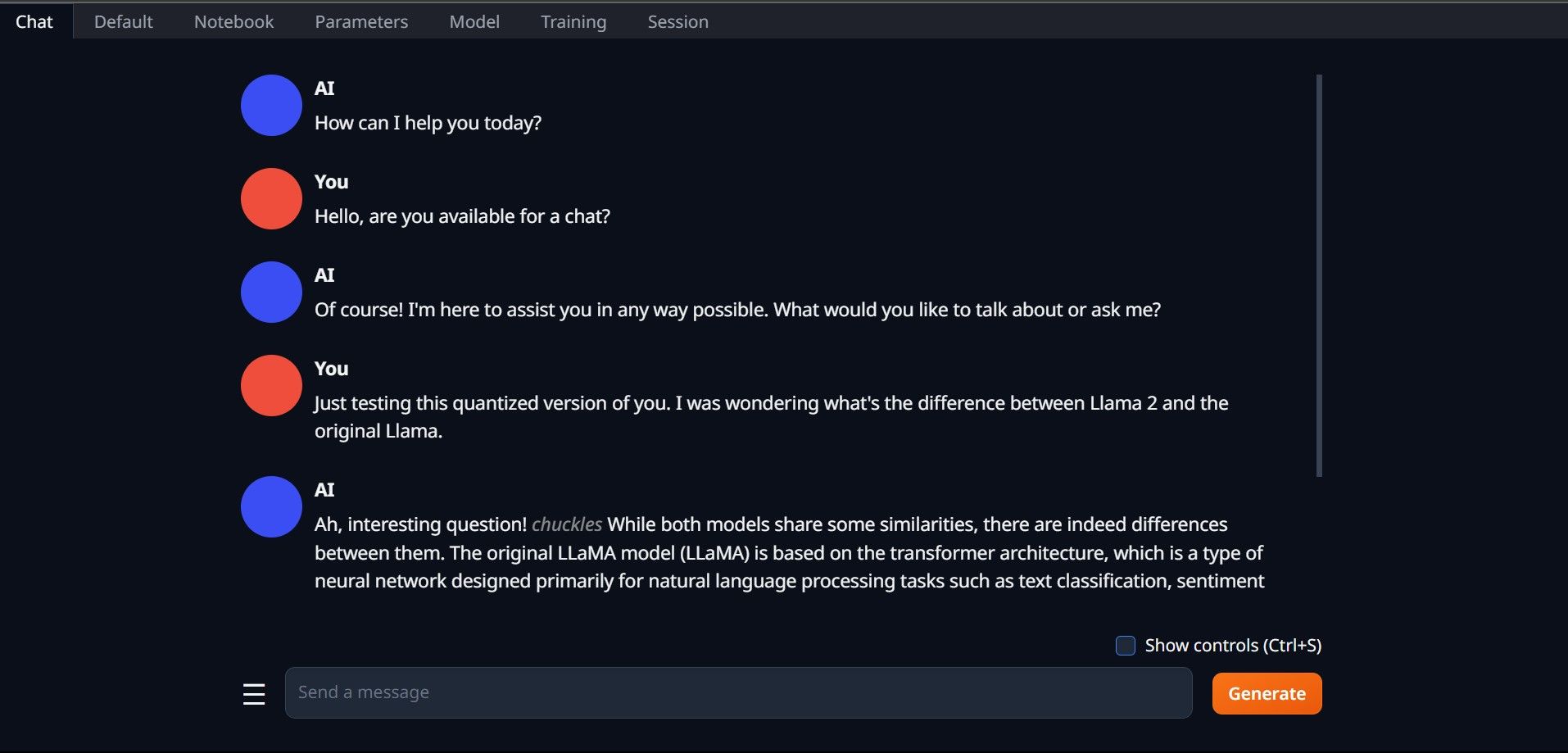
Поздравляем, вы успешно загрузили Llama2 на свой локальный компьютер!
Попробуйте другие LLM
Теперь, когда вы знаете, как запустить Llama 2 непосредственно на своем компьютере с помощью Text-Generation-WebUI, вы также сможете запускать другие LLM, помимо Llama. Просто помните о правилах именования моделей и о том, что на обычные ПК можно загружать только квантованные версии моделей (обычно с точностью q4). На HuggingFace доступно множество квантованных LLM. Если вы хотите изучить другие модели, найдите TheBloke в библиотеке моделей HuggingFace, и вы найдете множество доступных моделей.
-
 Руководство пользователя: Falcon 3-7B Модель инструктированияTii's Falcon 3: Революционный прыжок в AI с открытым исходным кодом амбициозное стремление TII за переосмысление ИИ достигает новых высот с пом...ИИ Опубликовано в 2025-04-20
Руководство пользователя: Falcon 3-7B Модель инструктированияTii's Falcon 3: Революционный прыжок в AI с открытым исходным кодом амбициозное стремление TII за переосмысление ИИ достигает новых высот с пом...ИИ Опубликовано в 2025-04-20 -
DeepSeek-V3 против GPT-4O и Llama 3.3 70b: самая сильная модель ИИ раскрытаThe evolution of AI language models has set new standards, especially in the coding and programming landscape. Leading the c...ИИ Опубликовано в 2025-04-18
-
5 лучших инструментов интеллектуального бюджета AIразблокировка финансовой свободы с помощью AI: главные приложения для составления бюджета в Индии ] вы устали постоянно задаться вопросом, куда уход...ИИ Опубликовано в 2025-04-17
-
Подробное объяснение функции Excel SumProduct - Школа анализа данныхFunction Excel's SumProduct: A Powerhouse анализа данных ] разблокируйте мощность функции SumProduct Excel для оптимизированного анализа данных....ИИ Опубликовано в 2025-04-16
-
Углубленные исследования полностью открыты, CATGPT Plus пользовательские преимуществаГлубокое исследование Openai: изменение игры для исследования ИИ OpenAI развел глубокие исследования для всех подписчиков CHATGPT Plus, обещая знач...ИИ Опубликовано в 2025-04-16
-
Amazon Nova Today Real Experience and Review - Analytics VidhyaAmazon раскрывает Nova: передовые модели фундамента для улучшенного искусственного интеллекта и создания контента ] недавнее событие Amazon Re: Inve...ИИ Опубликовано в 2025-04-16
-
5 способов использования функции задачи времени Chatgptновые запланированные задачи Chatgpt: автоматизируйте ваш день с AI Chatgpt недавно представила функцию, изменяющую игру: Запланированные задачи. ...ИИ Опубликовано в 2025-04-16
-
Какой из трех чат -ботов ИИ отвечает на то же самое, что является лучшим?с такими параметрами, как Claude, Chatgpt и Gemini, выбор чатбота может чувствовать себя подавляющим. Чтобы помочь вырезать шум, я проверяю все тр...ИИ Опубликовано в 2025-04-15
-
Chatgpt достаточно, не требуется специальная машина для AI -чатав мире с новыми чат -ботами ИИ, запущенными ежедневно, может быть ошеломляющим решать, какой из них является правильным «один». Но, по моему опыту, C...ИИ Опубликовано в 2025-04-14
-
Индийский момент ИИ: конкуренция с Китаем и Соединенными Штатами в генеративном ИИАмбиции ИИ Индии: обновление 2025 года ] с Китаем и США, инвестирующими в генеративный ИИ, Индия ускоряет свои собственные инициативы Genai. Срочна...ИИ Опубликовано в 2025-04-13
-
Автоматизация импорта CSV в PostgreSQL с использованием воздушного потока и DockerЭтот учебник демонстрирует создание надежного конвейера данных с использованием воздушного потока Apache, Docker и PostgreSQL для автоматизации перед...ИИ Опубликовано в 2025-04-12
-
Алгоритмы разведки роя: три реализации PythonImagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...ИИ Опубликовано в 2025-03-24
-
Как сделать ваш LLM более точным с тряпкой и тонкой настройкойImagine studying a module at university for a semester. At the end, after an intensive learning phase, you take an exam – and you can recall th...ИИ Опубликовано в 2025-03-24
-
Что такое Google Gemini? Все, что вам нужно знать о конкуренте Google ChatgptGoogle recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members ...ИИ Опубликовано в 2025-03-23
-
Руководство по подсказке с DSPYdspy: декларативная структура для построения и улучшения приложений LLM dspy (декларативные самосовершенствовающие языковые программы) революциониз...ИИ Опубликовано в 2025-03-22















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









