 титульная страница > программирование > Разработка эффективных алгоритмов. Измерение эффективности алгоритмов с использованием обозначения Big O
титульная страница > программирование > Разработка эффективных алгоритмов. Измерение эффективности алгоритмов с использованием обозначения Big O
Разработка эффективных алгоритмов. Измерение эффективности алгоритмов с использованием обозначения Big O
 Просматривать:692
Просматривать:692
Разработка алгоритма заключается в разработке математического процесса решения проблемы. Анализ алгоритма предназначен для прогнозирования производительности алгоритма. В предыдущих двух главах были представлены классические структуры данных (списки, стеки, очереди, очереди с приоритетами, наборы и карты) и применены их для решения проблем. В этой главе на различных примерах будут представлены общие алгоритмические методы (динамическое программирование, принцип «разделяй и властвуй» и возврат с возвратом) для разработки эффективных алгоритмов.
Обозначение Big O позволяет получить функцию для измерения временной сложности алгоритма на основе размера входных данных. Вы можете игнорировать мультипликативные константы и недоминирующие члены в функции. Предположим, что два алгоритма выполняют одну и ту же задачу, например поиск (линейный поиск или бинарный поиск). Какая из них лучше? Чтобы ответить на этот вопрос, вы можете реализовать эти алгоритмы и запустить программы, чтобы получить время выполнения. Но с этим подходом есть две проблемы:
- Во-первых, на компьютере одновременно выполняется множество задач. Время выполнения конкретной программы зависит от загрузки системы.
- Во-вторых, время выполнения зависит от конкретного ввода. Рассмотрим, например, линейный поиск и бинарный поиск. Если элемент, который нужно найти, оказывается первым в списке, линейный поиск найдет элемент быстрее, чем двоичный поиск.
Очень сложно сравнивать алгоритмы, измеряя время их выполнения. Чтобы преодолеть эти проблемы, был разработан теоретический подход для анализа алгоритмов, независимых от компьютеров и конкретных входных данных. Этот подход аппроксимирует влияние изменения на размер входных данных. Таким образом, вы можете увидеть, насколько быстро увеличивается время выполнения алгоритма с увеличением размера входных данных, поэтому вы можете сравнить два алгоритма, исследуя их скорости роста.
Рассмотрим линейный поиск. Алгоритм линейного поиска последовательно сравнивает ключ с элементами массива, пока ключ не будет найден или массив не будет исчерпан. Если ключа нет в массиве, требуется сравнение n для массива размером n. Если ключ находится в массиве, в среднем требуется n/2 сравнений. Время выполнения алгоритма пропорционально размеру массива. Если вы удвоите размер массива, вы ожидаете, что количество сравнений удвоится. Алгоритм растет с линейной скоростью. Темп роста имеет порядок n. Ученые-компьютерщики используют обозначение Big O для обозначения «порядка величины». Используя эти обозначения, сложность алгоритма линейного поиска равна O(n), что произносится как «порядка n». Мы называем алгоритм с временной сложностью O(n) линейным алгоритмом, и он демонстрирует линейную скорость роста.
Для одного и того же размера входных данных время выполнения алгоритма может различаться в зависимости от входных данных. Входные данные, которые приводят к наименьшему времени выполнения, называются входными данными для наилучшего случая, а входные данные, которые приводят к наибольшему времени выполнения, называются входными данными для входными данными для наихудшего случая. Анализ наилучшего случая и
Анализ наихудшего случая заключается в анализе алгоритмов на предмет их входных данных в лучшем и худшем случае. Анализ наилучшего и наихудшего случая не является репрезентативным, но анализ наихудшего случая очень полезен. Вы можете быть уверены, что алгоритм никогда не будет медленнее, чем в худшем случае.
Анализ среднего случая пытается определить среднее количество времени среди всех возможных входных данных одинакового размера. Анализ среднего случая идеален, но его сложно выполнить, поскольку для многих задач трудно определить относительные вероятности и распределения различных входных данных. Анализ наихудшего случая выполнить легче, поэтому анализ обычно проводится для наихудшего случая.
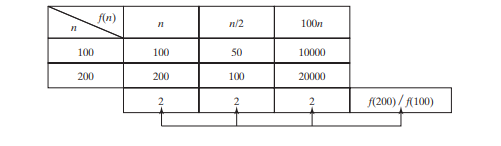
Алгоритм линейного поиска требует сравнений n в худшем случае и сравнений n/2 в среднем случае, если вы почти всегда ищете что-то, что известно о наличии в списке. Используя обозначение Big O, в обоих случаях требуется время O(n). Мультипликативную константу (1/2) можно опустить. Анализ алгоритма ориентирован на скорость роста. Мультипликативные константы не влияют на темпы роста. Темп роста для n/2 или 100_n_ такой же, как и для n, как показано в таблице ниже, Темпы роста. Следовательно, O(n) = O(n/2) = O(100n).
Рассмотрим алгоритм поиска максимального числа в массиве из n элементов. Чтобы найти максимальное число, если n равно 2, требуется одно сравнение; если n равно 3, два сравнения. В общем случае требуется n–1 сравнений, чтобы найти максимальное число в списке из n элементов. Анализ алгоритма предназначен для большого размера входных данных. Если размер входных данных невелик, оценка эффективности алгоритма не имеет значения. По мере увеличения n часть n в выражении n - 1 доминирует над сложностью. Обозначение Big O позволяет игнорировать недоминирующую часть (например, -1 в
выражение n - 1) и выделите важную часть (например, n в выражении n - 1). Следовательно, сложность этого алгоритма равна O(n).
Обозначение Big O оценивает время выполнения алгоритма в зависимости от размера входных данных. Если время не связано с размером входных данных, говорят, что алгоритм использует постоянное время с обозначением O(1). Например, метод, который извлекает элемент по заданному индексу в массиве
занимает постоянное время, поскольку время не увеличивается с увеличением размера массива.
Следующие математические суммирования часто полезны при анализе алгоритмов:
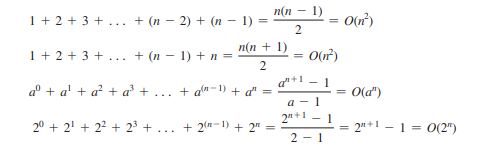
Временная сложность — это мера времени выполнения с использованием нотации Big-O. Аналогичным образом вы также можете измерить пространственную сложность, используя нотацию Big-O. Пространственная сложность измеряет объем памяти, используемый алгоритмом. Пространственная сложность большинства алгоритмов, представленных в книге, равна O(n). т. е. они демонстрируют линейную скорость роста входного размера. Например, пространственная сложность линейного поиска равна O(n).
-
 Использование WebSockets в Go для общения в реальном времениСоздание приложений, требующих обновлений в режиме реального времени, например приложений чата, живых уведомлений или инструментов для совместной рабо...программирование Опубликовано 21 декабря 2024 г.
Использование WebSockets в Go для общения в реальном времениСоздание приложений, требующих обновлений в режиме реального времени, например приложений чата, живых уведомлений или инструментов для совместной рабо...программирование Опубликовано 21 декабря 2024 г. -
Как реализовать функцию автоматического изменения размера текстовой области с помощью Prototype.js?Реализация автоматического изменения размера TextArea с помощью прототипаЧтобы улучшить взаимодействие с пользователем в вашем приложении для внутренн...программирование Опубликовано 21 декабря 2024 г.
-
Как настроить несколько источников данных в Spring Boot?Настройка нескольких источников данных в Spring BootВ Spring Boot использование нескольких источников данных позволяет изолировать управление доступом...программирование Опубликовано 21 декабря 2024 г.
-
Почему массив нулевой длины в C++ вызывает ошибку 2233 и как ее исправить?Работа с «массивом нулевой длины» в C В C ситуация «массива нулевой длины» может возникнуть в унаследованном коде. Сюда входят структуры, содержащие м...программирование Опубликовано 21 декабря 2024 г.
-
Как я могу стилизовать и обеспечить видимость HTML-тегов?Стилизация и видимость HTML-тегов Заявление о проблемеВ HTML тег используется для определения области изображения, которое можно связать с другим рес...программирование Опубликовано 21 декабря 2024 г.
-
Помимо операторов if: где еще можно использовать тип с явным преобразованием bool без приведения?Контекстное преобразование в bool разрешено без приведения Ваш класс определяет явное преобразование в bool, что позволяет использовать его экземпляр ...программирование Опубликовано 21 декабря 2024 г.
-
Как избежать глобальных переменных при доступе к объекту базы данных внутри класса?Использование глобальных переменных внутри классаСоздание функции нумерации страниц предполагает доступ к объекту базы данных из класса. Однако попытк...программирование Опубликовано 21 декабря 2024 г.
-
Как я могу найти пользователей, у которых сегодня дни рождения, используя MySQL?Как определить пользователей с сегодняшним днем рождения с помощью MySQLОпределение того, является ли сегодня день рождения пользователя с помощью M...программирование Опубликовано 21 декабря 2024 г.
-
Как я могу генерировать равномерно распределенные случайные числа в определенном диапазоне в C++?Генерация единых случайных чисел во всем диапазонеВы ищете метод равномерной генерации случайных чисел в заданном диапазоне [мин, макс]. Недостатки ra...программирование Опубликовано 21 декабря 2024 г.
-
Как я могу подавить значения нулевого поля во время сериализации Джексона?Обработка значений пустых полей в сериализации ДжексонаJackson, популярная библиотека сериализации Java, предоставляет различные параметры конфигураци...программирование Опубликовано 21 декабря 2024 г.
-
Как JavaScript может обнаружить активность вкладок браузера?Определение активности вкладок браузера с помощью JavaScriptПри веб-разработке часто желательно определить, активно ли используется вкладка браузера. ...программирование Опубликовано 21 декабря 2024 г.
-
Каковы ограничения на длину массивов в C++ и как их можно преодолеть?Исследование ограничений длины массива в C Несмотря на свою огромную полезность, массивы C накладывают определенные ограничения на свой размер. Степен...программирование Опубликовано 21 декабря 2024 г.
-
Как мы можем эффективно скомпилировать AST обратно в читаемый исходный код?Компиляция AST обратно в исходный кодКомпиляция абстрактного синтаксического дерева (AST) обратно в исходный код, часто называемая «prettyprinting» ,»...программирование Опубликовано 21 декабря 2024 г.
-
Почему IntelliJ показывает ошибки «Невозможно разрешить символ» после успешной компиляции?Ошибка инспектора IntelliJ «Невозможно разрешить символ», несмотря на успешную компиляциюПользователи IntelliJ могут столкнуться с запутанной ситуацие...программирование Опубликовано 21 декабря 2024 г.
-
Как просмотреть значения переменных таблицы во время отладки T-SQL в SSMS?Просмотр значений переменных таблицы во время отладкиПри отладке кода Transact-SQL (T-SQL) в SQL Server Management Studio (SSMS), может быть полезно п...программирование Опубликовано 21 декабря 2024 г.















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









