 титульная страница > программирование > API данных для Amazon Aurora Serverless с AWS SDK для Java — часть Aurora Serverless vata API соответствует DevOps Guru или нет?
титульная страница > программирование > API данных для Amazon Aurora Serverless с AWS SDK для Java — часть Aurora Serverless vata API соответствует DevOps Guru или нет?
API данных для Amazon Aurora Serverless с AWS SDK для Java — часть Aurora Serverless vata API соответствует DevOps Guru или нет?
 Просматривать:441
Просматривать:441
Введение
В моей статье Amazon DevOps Guru для бессерверных приложений. Часть 10. Обнаружение аномалий в Aurora Serverless v2 мы узнали, что DevOps Guru смог успешно обнаружить аномалии с помощью базы данных Aurora (Serverless v2) PostgreSQL в случае функции Lambda с управлением Java 21. среда выполнения была подключена к нему через JDBC. Мы масштабировали нашу базу данных всего с 0,5 до 1 ACU и создали очень высокую нагрузку на базу данных, вызывая функцию Lambda для извлечения продукта по идентификатору несколько сотен раз одновременно в течение нескольких минут. Мы увидели, что DevOps Guru правильно указал на возросшую сумму подключений к базе данных и постоянно высокую нагрузку на базу данных (ЦП). В этой статье я хотел бы выяснить, обнаружит ли DevOps Guru аномалию, проведя тот же эксперимент, но используя Data API для Aurora Serverless v2 с AWS SDK для Java вместо JDBC.
Обнаружение аномалий в Aurora Serverless v2 с помощью Data API
Давайте рассмотрим наш пример приложения и воспользуемся шаблоном SAM для создания инфраструктуры и развертывания приложения, описанного на следующем рисунке:
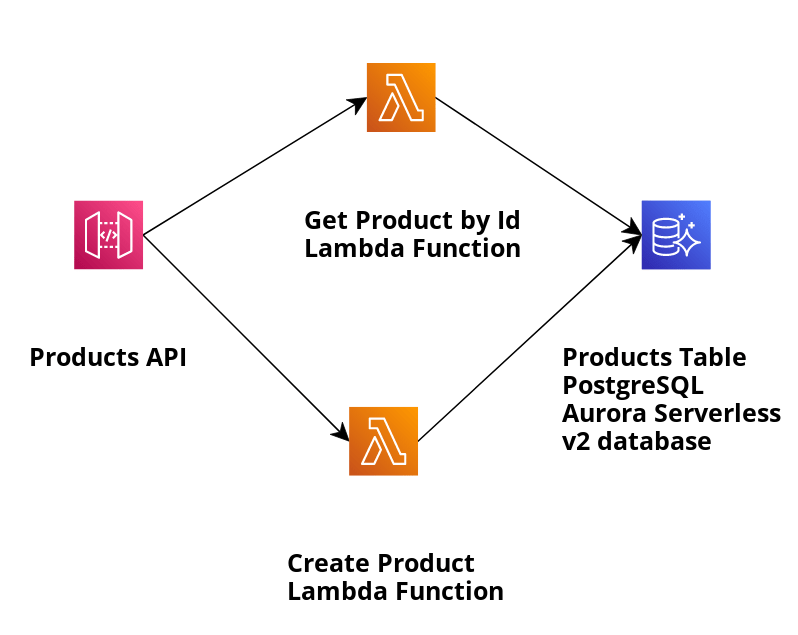
Приложение создает продукты, хранящиеся в базе данных PostgreSQL Aurora Serverless v2, и извлекает их по идентификатору с помощью Data API. Соответствующая функция Lambda, которую мы будем использовать для получения продукта по его идентификатору, — это GetProductByIdViaAuroraServerlessV2DataApi, а ее реализация обработчика — GetProductByIdViaAuroraServerlessV2DataApiHandler.
Как и в предыдущей статье, мы используем инструмент «hey» для проведения такого стресс-теста
hey -z 15m -c 300 -H "X-API-Key: XXXa6XXXX" https://XXX.execute-api.eu-central-1.amazonaws.com/prod/productsWithDataApi/1
В этом примере мы вызываем конечную точку шлюза API с 300 одновременными контейнерами на 15 минут. За конечной точкой prod/productsWithoutDataApi будет вызвана лямбда-функция GetProductByIdViaAuroraServerlessV2WithoutDataApi, которая получит продукт по идентификатору 1 из базы данных PostgreSQL Aurora Serverless v2.
Мы настроили в нашем [шаблоне SAM]((https://github.com/Vadym79/AWSLambdaJavaAuroraServerlessV2DataApi/blob/master/template.yaml) кластер базы данных Aurora для масштабирования от минимальной емкости 0,5 до максимальной емкости 1 ACU (что составляет очень маленький размер базы данных) в случае повышенной нагрузки в целях экономии.
AuroraServerlessV2Cluster:
Type: 'AWS::RDS::DBCluster'
...
ServerlessV2ScalingConfiguration:
MinCapacity: 0.5
MaxCapacity: 1
База данных Aurora (Serverless v2) управляет максимальным количеством доступных подключений к базе данных пропорционально размеру базы данных (в нашем случае настройка ACU), а также с помощью Data API для Aurora Serverless v2 (что является огромным отличием от версии 1, которая станет поддержка прекращена в конце 2024 года, когда была жесткая квота в 1000 подключений к базе данных в секунду). Для получения дополнительной информации прочтите документацию о максимальном количестве подключений для Aurora Serverless v2. Таким образом, с увеличением количества вызовов мы ожидаем вскоре достичь максимального количества доступных подключений к базе данных и высокой загрузки базы данных (ЦП), так что база данных не сможет отвечать на запросы новых функций Lambda для получения продукта по id (тогда тоже столкнется с Lambda). Тем самым мы спровоцируем аномалию и хотим выяснить, сможет ли DevOps Guru ее обнаружить. И это удалось, вроде.... Возникло следующее понимание:
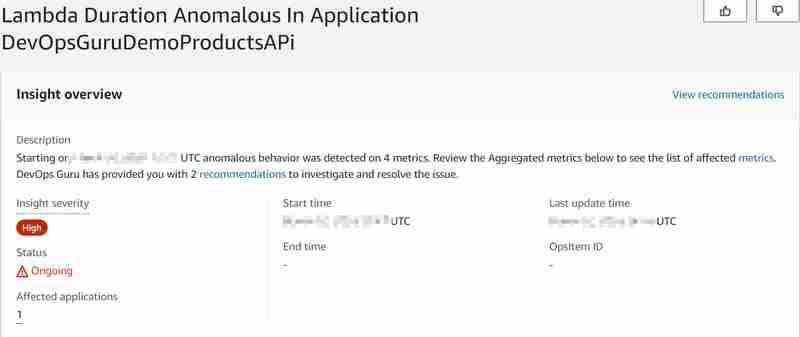
И были выявлены следующие совокупные аномальные показатели:
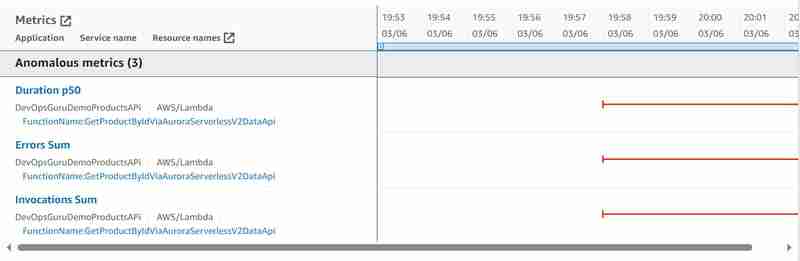
По сравнению с агрегированными аномальными метриками, выявленными в случае использования JDBC вместо Data API, описанными в моей статье Amazon DevOps Guru для бессерверных приложений. Часть 10. Обнаружение аномалий в Aurora Serverless v2, мы полностью запутались в аномальных метриках базы данных Aurora: подключение к базе данных сумма и загрузка базы данных (ЦП), но правильно увидеть ошибку в Lambda, которая произошла в течение определенного времени из 15 секунд, поскольку база данных не могла ответить.
 .
.
Так в чем же разница? Давайте рассмотрим оба инцидента, которые мы воспроизвели в кластере PostgreSQL Aurora Serverless v2 с JDBC (Non Data API) и Data API:
С точки зрения использования/масштабирования ACU они оба выглядят одинаково:
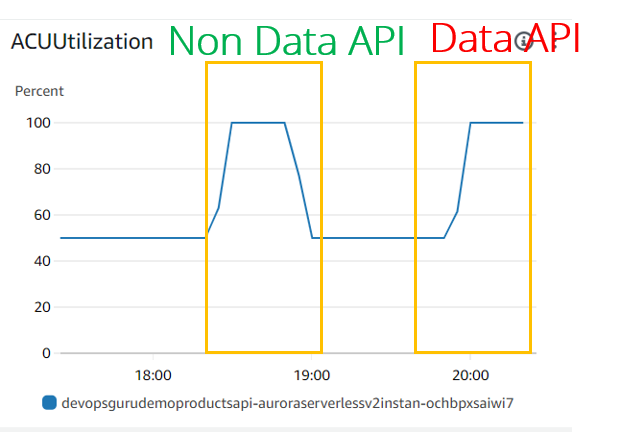
Что касается других показателей базы данных, таких как загрузка ЦП, DatabaseConnection DBLoad(CPU), существуют огромные различия:
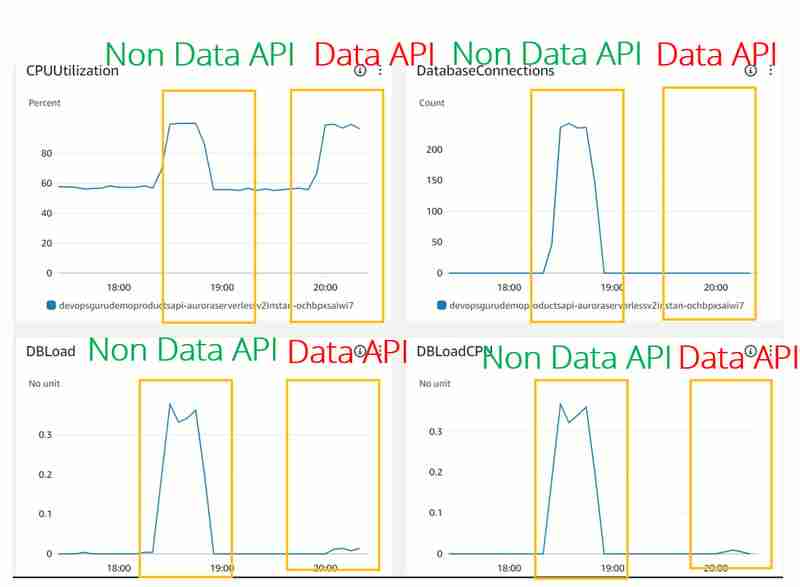
- Загрузка ЦП выглядит одинаково для случаев JDBC (API без данных) и API данных. Но DevOps Guru, похоже, не учитывает эту метрику, поскольку мы не видели ее даже в эксперименте JDBC
- DBLoad(CPU), что очень мало для использования Data API. Похоже, что для Dat API перед базой данных Aurora Serverless v2 есть некий балансировщик нагрузки, который отслеживает использование соединения и защищает базу данных от перегрузки.
- Метрика DatabaseConnection не отображается (или отображается как 0) для использования Data API. Причина в том, что мы не управляем подключением к базе данных для Data API, это делается за нас с другой стороны. Конечно, они по-прежнему играют важную роль, которую мы узнали в разделе «Максимальное количество подключений для Aurora Serverless v2», но эта метрика, похоже, доступна извне в метриках CloudWatch, и даже DevOps Guru не имеет доступа к реальным цифрам.
При этом и очень низком уровне DBLoad (ЦП) не было получено никакой информации DevOps Guru для кластера Aurora Serverless v2 с использованием Data API по сравнению со сценарием использования JDBC.
Я провел второй эксперимент, подключившись к кластеру Aurora Serverless v2 напрямую, и написал сценарий для создания нагрузочного теста, написав сценарий, который извлекает продукт по идентификатору несколько сотен раз, используя стандартный способ (не-Data API). Аналогично тому, как мы это делали с инструментом «hey», но обращаемся напрямую к базе данных вместо вызова Api Gateway. После того, как я подверг базу данных нагрузке, я начал тот же эксперимент с инструментом «эй», как описано выше, и хотел посмотреть, что произойдет. Была получена такая же информация, но на этот раз со следующими аномальными показателями:
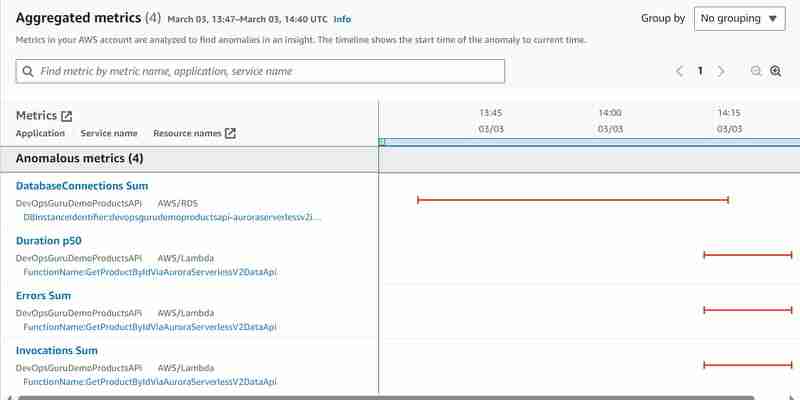
Теперь мы видим как минимум дополнительную аномальную метрику суммы подключений к базе данных Aurora Serverless v2, но метрики DBLoad(CPU) по-прежнему отсутствуют.
Аномалии на графике выглядят следующим образом:
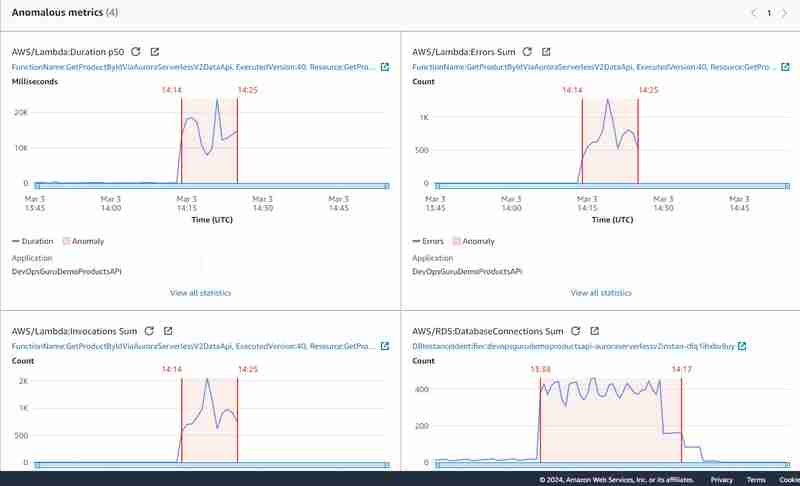
Конечно, эксперимент не был чистым, так как я выполнил 2 нагрузочных теста друг за другом и частично параллельно: первый с подключением к базе данных напрямую без использования API Gateway, а второй с использованием Data API. Это подтвердило мое первоначальное предположение о том, что метрики суммы подключений к базе данных являются очень важным критерием для получения информации DevOps Guru для Aurora Serverless v2 (и для RDS в целом) и в целом не раскрываются в случае использования Data API.
Я уже связался с командой Devops Guru и поделился с ними своими мыслями, ожидая, что они улучшат сервис. Или, прежде всего, будет исправлено предоставление подключения к базе данных в качестве метрики CloudWatch для использования Aurora Serverless v2 с API данных.
Заключение
В этой статье мы узнали, что DevOps Guru может успешно обнаруживать аномалии с базой данных Aurora (Serverless v2) PostgreSQL в случае функции Lambda с управляемой средой выполнения Java 21, подключенной к ней через API данных, но может показывать только аномальные метрики, связанные с функцией Lambda. время ожидания истекло, поскольку база данных не ответила. Основная причина этого, по-видимому, заключается в том, что подключение к базе данных в качестве метрики CloudWatch не отображается (или всегда отображается как 0) в случае использования Aurora Serverless v2 с Data API. Метрики базы данных Aurora Serverless v2 (сумма подключений к базе данных) были показаны только во время второго искусственного эксперимента.
-
 Помимо операторов if: где еще можно использовать тип с явным преобразованием bool без приведения?Контекстное преобразование в bool разрешено без приведения Ваш класс определяет явное преобразование в bool, что позволяет использовать его экземпляр ...программирование Опубликовано 18 ноября 2024 г.
Помимо операторов if: где еще можно использовать тип с явным преобразованием bool без приведения?Контекстное преобразование в bool разрешено без приведения Ваш класс определяет явное преобразование в bool, что позволяет использовать его экземпляр ...программирование Опубликовано 18 ноября 2024 г. -
Как исправить «Неправильно сконфигурировано: ошибка загрузки модуля MySQLdb» в Django на macOS?Неправильная настройка MySQL: проблема с относительными путямиПри запуске сервера запуска Python Manage.py в Django вы можете столкнуться со следующей...программирование Опубликовано 18 ноября 2024 г.
-
Что случилось со смещением столбцов в бета-версии Bootstrap 4?Bootstrap 4 Beta: удаление и восстановление смещения столбцовBootstrap 4 в своей бета-версии 1 внес существенные изменения в способ столбцы были смеще...программирование Опубликовано 18 ноября 2024 г.
-
Как объединить два ассоциативных массива в PHP, сохранив при этом уникальные идентификаторы и обработав повторяющиеся имена?Объединение ассоциативных массивов в PHPВ PHP объединение двух ассоциативных массивов в один — распространенная задача. Рассмотрим следующий запрос:Оп...программирование Опубликовано 18 ноября 2024 г.
-
МножествоМетоды — это fns, которые можно вызывать на объектах Массивы — это объекты, поэтому в JS у них тоже есть методы. срез (начало): извлечь часть ...программирование Опубликовано 18 ноября 2024 г.
-
Как я могу получить покрытие кода с помощью интеграционных тестов для двоичного файла Go?Захват покрытия кода из двоичного файла GoПри выполнении модульных тестов захват покрытия кода прост. Однако сбор показателей покрытия во время интегр...программирование Опубликовано 18 ноября 2024 г.
-
Как импортировать базу данных в MySQL из терминала?Импорт базы данных в MySQL из терминалаИмпорт базы данных в MySQL с помощью терминала может обеспечить удобный способ управления данными. Чтобы эффект...программирование Опубликовано 18 ноября 2024 г.
-
Как перебирать параллельные массивы в шаблонах HTML с помощью функции index?Как перебирать параллельные массивы в HTML-шаблонах с использованием индексаВ этой статье рассматриваются трудности перебора параллельных массивов (од...программирование Опубликовано 18 ноября 2024 г.
-
Почему при переборе списка Python следует избегать удаления элементов?Списки Python: подводные камни удаления элементов во время итерацииИтерация по списку Python с одновременным удалением элементов может привести к неож...программирование Опубликовано 18 ноября 2024 г.
-
Как устранить двойные границы в CSS: контуры против отрицательных полей?Предотвращение двойных границ в CSSМногие веб-разработчики сталкиваются с распространенной проблемой при стилизации элементов рядом с границами. Из-за...программирование Опубликовано 18 ноября 2024 г.
-
Как встроить изображения в элементы Div, используя только CSS?Интеграция изображений в элементы div с помощью CSS: эффективное решениеВ веб-разработке часто желательно размещать изображения внутри элементов div. ...программирование Опубликовано 18 ноября 2024 г.
-
Как передать переменное количество аргументов функциям JavaScript?Передача переменного количества аргументов в функции JavaScriptJavaScript предлагает гибкость при передаче аргументов в функции, включая возможность о...программирование Опубликовано 18 ноября 2024 г.
-
Почему я не могу внедрить CSS в веб-страницы, используя сценарии контента для расширений?Проблемы внедрения CSS в скриптах контента для расширенийНесмотря на определение внедрения CSS в манифесте, ваш файл CSS по-прежнему отсутствует на ве...программирование Опубликовано 18 ноября 2024 г.
-
Раскройте свое мастерство Python: проект по сортировке уникальных символовГотовы ли вы отправиться в увлекательное путешествие по программированию на Python? Не ищите ничего, кроме курса LabEx.io «Проект: удаление дубликатов...программирование Опубликовано 18 ноября 2024 г.
-
Как я могу найти пользователей, у которых сегодня дни рождения, используя MySQL?Как определить пользователей с сегодняшним днем рождения с помощью MySQLОпределение того, является ли сегодня день рождения пользователя с помощью M...программирование Опубликовано 18 ноября 2024 г.















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









