 титульная страница > программирование > Преобразуйте строку в CamelCase, используя эту функцию в Javascript.
титульная страница > программирование > Преобразуйте строку в CamelCase, используя эту функцию в Javascript.
Преобразуйте строку в CamelCase, используя эту функцию в Javascript.
 Просматривать:255
Просматривать:255
Вы когда-нибудь нуждались в преобразовании строки в CamelCase? Я нашел интересный фрагмент кода, изучая репозиторий Supabase с открытым исходным кодом. Вот метод, который они используют:
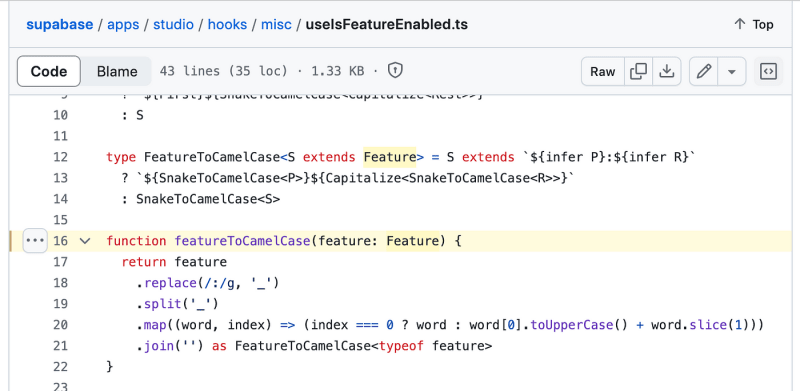
function featureToCamelCase(feature: Feature) {
return feature
.replace(/:/g, '\_')
.split('\_')
.map((word, index) => (index === 0 ? word : word\[0\].toUpperCase() word.slice(1)))
.join('') as FeatureToCamelCase
}
Эта функция довольно удобна. Он заменяет двоеточия на подчеркивания, разбивает строку на слова, а затем сопоставляет каждое слово, чтобы преобразовать его в верблюжий регистр. Первое слово сохраняется в нижнем регистре, а в последующих словах первый символ пишется с заглавной буквы, а затем снова объединяется. Просто, но эффективно!
Я столкнулся с другим подходом к Stack Overflow, в котором не используются регулярные выражения. Вот альтернатива:
function toCamelCase(str) {
return str.split(' ').map(function(word, index) {
// If it is the first word make sure to lowercase all the chars.
if (index == 0) {
return word.toLowerCase();
}
// If it is not the first word only upper case the first char and lowercase the rest.
return word.charAt(0).toUpperCase() word.slice(1).toLowerCase();
}).join('');
}
Этот фрагмент кода из SO содержит комментарии, объясняющие, что делает этот код, за исключением того, что он не использует никаких регулярных выражений. Код, найденный в способе преобразования строки в CamelCase в Supabase, очень похож на этот ответ SO, за исключением комментариев и используемого регулярного выражения.
.replace(/:/g, '\_')
Этот метод разбивает строку на пробелы, а затем сопоставляет каждое слово. Первое слово полностью пишется строчными буквами, а последующие слова пишутся с заглавной буквы в первом символе, а остальные слова — в нижнем регистре. Наконец, слова снова соединяются вместе, образуя строку в верблюжьем регистре.
В одном интересном комментарии пользователя Stack Overflow упоминается преимущество этого подхода в производительности:
“ 1 за неиспользование регулярных выражений, даже если вопрос требовал решения с их использованием. Это гораздо более понятное решение, а также явный выигрыш в производительности (поскольку обработка сложных регулярных выражений — гораздо более сложная задача, чем просто перебирать кучу строк и объединять их фрагменты). См. jsperf.com/camel-casing-regexp-or-character-manipulation/1 , где я взял некоторые из примеров здесь вместе с этим (а также мой собственный скромный улучшение производительности, хотя в большинстве случаев я, вероятно, предпочел бы эту версию для ясности)».
Оба метода имеют свои преимущества. Подход с использованием регулярных выражений в коде Supabase является кратким и использует мощные методы манипулирования строками. С другой стороны, подход без регулярных выражений хвалят за его ясность и производительность, поскольку он позволяет избежать вычислительных затрат, связанных с регулярными выражениями.
Выбрать между ними можно следующим образом:
- Используйте подход с регулярными выражениями, если вам нужно компактное однострочное решение, использующее мощные возможности JavaScript по регулярным выражениям. Также не забудьте добавить комментарии, объясняющие, что делает ваше регулярное выражение, чтобы это было понятно вам в будущем или следующему разработчику, работающему с вашим кодом.
- Выберите метод без регулярных выражений, если вы отдаете предпочтение читаемости и производительности, особенно при работе с более длинными строками или при многократном выполнении этого преобразования.
Хотите узнать, как собрать shadcn-ui/ui с нуля? Ознакомьтесь с сборкой с нуля
Обо мне:
Веб-сайт: https://ramunarasinga.com/
Linkedin: https://www.linkedin.com/in/ramu-narasinga-189361128/
Github: https://github.com/Ramu-Narasinga
Электронная почта: [email protected]
Собрать shadcn-ui/ui с нуля
Использованная литература:
- https://github.com/supabase/supabase/blob/master/apps/studio/hooks/misc/useIsFeatureEnabled.ts#L16
- https://stackoverflow.com/a/35976812
-
 Как обойти блоки веб -сайтов с помощью запросов Python и фальшивых пользовательских агентов?Как смоделировать поведение браузера с помощью запросов Python и фальшивых пользовательских агентов библиотеки Python - это мощный инструмент ...программирование Опубликовано в 2025-03-31
Как обойти блоки веб -сайтов с помощью запросов Python и фальшивых пользовательских агентов?Как смоделировать поведение браузера с помощью запросов Python и фальшивых пользовательских агентов библиотеки Python - это мощный инструмент ...программирование Опубликовано в 2025-03-31 -
Как преобразовать столбец DataFrame Pandas в формат DateTime и фильтр по дате?Transform Pandas DataFrame в Format DateTime сценарий: данные в данных Pandas DataFrame часто существует в различных форматах, включая строк...программирование Опубликовано в 2025-03-31
-
Как разрешить \ "Отказалось загрузить сценарий ... \" Ошибки из -за политики безопасности контента Android?Представление Mystery: Directive Policive Policive Content Security столкновение с загадочной ошибкой »отказалась загрузить скрипт ...» при ра...программирование Опубликовано в 2025-03-31
-
Как разрешить расходы на путь модуля в Go Mod с помощью директивы «Заменить»?Распространение пути преодоления модуля в Go Mod При использовании MOD можно столкнуться с конфликтом, где 3 -й пакет импортирует другой пакет...программирование Опубликовано в 2025-03-31
-
Как я могу объединить таблицы базы данных с различным числом столбцов?объединенные таблицы с разными столбцами ] может столкнуться с проблемами при попытке объединить таблицы баз данных с разными столбцами. Просто...программирование Опубликовано в 2025-03-31
-
Как проверить, есть ли у объекта конкретный атрибут в Python?Метод для определения атрибута объекта Этот запрос ищет метод для проверки присутствия конкретного атрибута в объекте. Рассмотрим следующий пр...программирование Опубликовано в 2025-03-31
-
Почему Microsoft Visual C ++ не может правильно реализовать двухфазной экземпляры?загадка «Сломанная» двухфазное матричное экземпляры в Microsoft Visual C Задача: пользователи обычно выражают обеспокоенность Microsoft Visu...программирование Опубликовано в 2025-03-31
-
Как я могу обрабатывать имена файлов UTF-8 в функциях файловой системы PHP?обработка UTF-8 имен файлов в функциях файловой системы PHP При создании папок, содержащих utf-8, с использованием функции PHP MkDir, вы может...программирование Опубликовано в 2025-03-31
-
Как исправить \ "mysql_config не найдена \" Ошибка при установке MySQL-Python на Ubuntu/Linux?mysql-python error: "mysql_config не найдено" попытка установить Mysql-python на Ubuntu/linux box может столкнуться с сообщением об ...программирование Опубликовано в 2025-03-31
-
Множествометоды являются FNS, которые можно вызвать на Objects ] Массивы являются объектами, следовательно, они также имеют методы в JS. ] ] Срез (...программирование Опубликовано в 2025-03-31
-
Как проанализировать массивы JSON в Go, используя пакет `json`?] MARSING JSON Arrays в Go с пакетом JSON задача: Как вы можете проанализировать строку json, представляющую массив в Go, используя JSON Pack...программирование Опубликовано в 2025-03-31
-
Как упростить анализ JSON в PHP для многомерных массивов?sacksing json с php пытаться анализировать данные JSON в PHP может быть сложной, особенно при работе с многомерными массивами. Чтобы упростить п...программирование Опубликовано в 2025-03-31
-
Почему `body {margin: 0; } `Всегда удалять верхний край в CSS?адресация поля тела в CSS для начинающих веб -разработчиков, удаление поля элемента тела может быть запутанной задачей. Часто предоставляемый ...программирование Опубликовано в 2025-03-31
-
Как правильно вставить Blobs (изображения) в MySQL с помощью PHP?вставьте Blobs в базы данных MySQL с PHP При попытке сохранить изображение в базе данных MySQL, вы можете столкнуться с проблемой. Это руково...программирование Опубликовано в 2025-03-31
-
Как я могу настроить оптимизацию компиляции в компиляторе GO?настройка оптимизации компиляции в GO Compiler процесс компиляции по умолчанию в GO следует за конкретной стратегией оптимизации. Однако польз...программирование Опубликовано в 2025-03-31















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









