
Как оптимизация сравнения ускоряет сортировку Python
 Просматривать:821
Просматривать:821
В этом тексте термины Python и CPython, который является эталонной реализацией языка, используются как взаимозаменяемые. Эта статья посвящена конкретно CPython и не касается какой-либо другой реализации Python.
Python — это прекрасный язык, который позволяет программисту выражать свои идеи простыми словами, оставляя за кадром сложность фактической реализации.
Одна из вещей, которую он абстрагирует, — это сортировка.
Вы легко найдете ответ на вопрос «как реализована сортировка в Python?» что почти всегда отвечает на другой вопрос: «Какой алгоритм сортировки использует Python?».
Однако это часто оставляет за собой некоторые интересные детали реализации.
Есть одна деталь реализации, которая, на мой взгляд, недостаточно обсуждается, хотя она была представлена более семи лет назад в Python 3.7:
sorted() и list.sort() были оптимизированы для распространенных случаев и теперь работают на 40–75 % быстрее. (Предоставлено Эллиотом Гороховским в bpo-28685.)
Но прежде чем мы начнем...
Краткое введение в сортировку в Python
Когда вам нужно отсортировать список в Python, у вас есть два варианта:
- Метод списка: list.sort(*, key=None,verse=False), который сортирует заданный список на месте
- Встроенная функция: sorted(iterable, /, *, key=None, reverse= False), который возвращает отсортированный список без изменения его аргумента
Если вам нужно отсортировать любую другую встроенную итерацию, вы можете использовать только sorted независимо от типа итерации или генератора, переданного в качестве параметра.
sorted всегда возвращает список, поскольку внутри него используется list.sort.
Вот грубый эквивалент реализации сортировки C в CPython, переписанной на чистом Python:
def sorted(iterable: Iterable[Any], key=None, reverse=False):
new_list = list(iterable)
new_list.sort(key=key, reverse=reverse)
return new_list
Да, это так просто.
Как Python ускоряет сортировку
Как сказано во внутренней документации Python по сортировке:
Иногда можно заменить более быстрые сравнения конкретных типов на более медленные, общие PyObject_RichCompareBool
А вкратце эту оптимизацию можно описать так:
Когда список однороден, Python использует функцию сравнения для конкретного типа
Что такое однородный список?
Однородный список — это список, содержащий элементы только одного типа.
Например:
homogeneous = [1, 2, 3, 4]
С другой стороны, это не однородный список:
heterogeneous = [1, "2", (3, ), {'4': 4}]
Интересно, что в официальном руководстве по Python говорится:
Списки изменяемы, а их элементы обычно однородны и доступны путем перебора списка
Примечание о кортежах
В том же руководстве говорится:
Кортежи неизменяемы, и обычно содержат гетерогенную последовательность элементов
Итак, если вы когда-нибудь задавались вопросом, когда использовать кортеж или список, вот практическое правило:
если элементы одного типа, используйте список, в противном случае используйте кортеж
Подождите, а как насчет массивов?
Python реализует объект-контейнер однородного массива для числовых значений.
Однако, начиная с Python 3.12, массивы не реализуют собственный метод сортировки.
Единственный способ их сортировки — использовать sorted, который внутренне создает список из массива, удаляя при этом любую информацию, связанную с типом.
Почему помогает использование функции сравнения для конкретного типа?
Сравнения в Python требуют больших затрат, поскольку перед выполнением фактического сравнения Python выполняет различные проверки.
Вот упрощенное объяснение того, что происходит внутри, когда вы сравниваете два значения в Python:
- Python проверяет, что значения, переданные в функцию сравнения, не равны NULL
- Если значения имеют разные типы, но правый операнд является подтипом левого, Python использует функцию сравнения правого операнда, но обратную (например, он будет использовать )
- Если значения имеют один и тот же тип или разные типы, но ни один из них не является подтипом другого:
- Python сначала попробует функцию сравнения левого операнда
- Если это не удастся, он попытается использовать функцию сравнения правого операнда, но в обратном порядке.
- Если и это не помогло, и сравнение выполняется на равенство или неравенство, оно вернет сравнение идентификаторов (верно для значений, которые ссылаются на один и тот же объект в памяти)
- В противном случае выдается ошибка TypeError
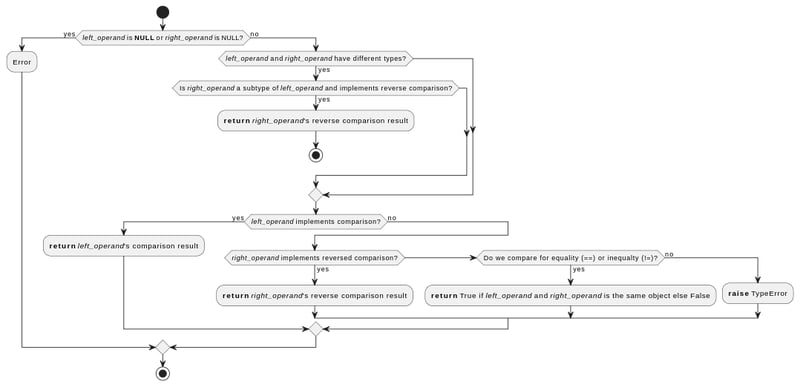
Кроме того, собственные функции сравнения каждого типа реализуют дополнительные проверки.
Например, при сравнении строк Python проверит, занимают ли строковые символы более одного байта памяти, а сравнение с плавающей запятой будет сравнивать пару чисел с плавающей запятой, а также число с плавающей запятой и целое число по-разному.
Более подробное объяснение и диаграмму можно найти здесь: Добавление оптимизации сортировки с учетом данных в CPython
До того, как была введена эта оптимизация, Python должен был выполнять все эти различные проверки, специфичные и не специфичные для типа, каждый раз, когда во время сортировки сравнивались два значения.
Предварительная проверка типов элементов списка
Не существует волшебного способа узнать, относятся ли все элементы списка к одному и тому же типу, кроме как перебирать список и проверять каждый элемент.
Python делает почти именно это — проверяет типы ключей сортировки, сгенерированных ключевой функцией, переданной в list.sort или отсортированных в качестве параметра
Создание списка ключей
Если предоставлена ключевая функция, Python использует ее для создания списка ключей, в противном случае он использует собственные значения списка в качестве ключей сортировки.
В упрощенном виде построение ключей можно выразить в виде следующего кода Python.
if key is None:
keys = list_items
else:
keys = [key(list_item) for list_item in list_item]
Обратите внимание, что ключи, используемые внутри CPython, представляют собой массив C ссылок на объекты CPython, а не список Python
После создания ключей Python проверяет их типы.
Проверка типа ключа
При проверке типов ключей алгоритм сортировки Python пытается определить, все ли элементы в массиве ключей являются строковыми, int, float или кортежами или просто относятся к одному и тому же типу с некоторыми ограничениями для базовых типов.
Стоит отметить, что проверка типов клавиш требует дополнительной работы. Python делает это, потому что обычно это окупается за счет ускорения фактической сортировки, особенно для длинных списков.
ограничения int
int не должен не быть большим числом
Практически это означает, что для работы этой оптимизации целое число должно быть меньше 2^30 - 1 (это может варьироваться в зависимости от платформы)
В качестве примечания, вот отличная статья, в которой объясняется, как Python обрабатывает большие целые числа: # Как Python реализует сверхдлинные целые числа?
ограничения строки
Все символы строки должны занимать менее 1 байта памяти, то есть они должны быть представлены целочисленными значениями в диапазоне 0–255
На практике это означает, что строки должны состоять только из латинских символов, пробелов и некоторых специальных символов, найденных в таблице ASCII.
ограничения с плавающей запятой
Для работы этой оптимизации не существует ограничений для чисел с плавающей запятой.
ограничения кортежа
- Проверяется только тип первого элемента
- Сам этот элемент не должен быть кортежем
- Если все кортежи имеют один и тот же тип для своего первого элемента, к ним применяется оптимизация сравнения.
- Все остальные элементы сравниваются как обычно
Как я могу применить эти знания?
Во-первых, разве это не интересно знать?
Во-вторых, упоминание этих знаний может быть приятным штрихом на собеседовании с разработчиком Python.
Что касается реальной разработки кода, понимание этой оптимизации может помочь вам улучшить производительность сортировки.
Оптимизируйте, разумно выбирая тип значений
Согласно тесту PR, в котором представлена эта оптимизация, сортировка списка, состоящего только из чисел с плавающей запятой, а не списка чисел с плавающей запятой даже с одним целым числом в конце, происходит почти в два раза быстрее.
Итак, когда придет время оптимизировать список, преобразуйте его следующим образом
floats_and_int = [1.0, -1.0, -0.5, 3]
В список, который выглядит так
just_floats = [1.0, -1.0, -0.5, 3.0] # note that 3.0 is a float now
может улучшить производительность.
Оптимизация с помощью ключей для списков объектов
Хотя оптимизация сортировки в Python хорошо работает со встроенными типами, важно понимать, как она взаимодействует с пользовательскими классами.
При сортировке объектов пользовательских классов Python использует определяемые вами методы сравнения, такие как __lt__ (меньше) или __gt__ (больше).
Однако оптимизация для конкретного типа не применяется к пользовательским классам.
Python всегда будет использовать общий метод сравнения для этих объектов.
Вот пример:
class MyClass:
def __init__(self, value):
self.value = value
def __lt__(self, other):
return self.value
В этом случае Python будет использовать метод __lt__ для сравнения, но оптимизация для конкретного типа не принесет пользы. Сортировка по-прежнему будет работать корректно, но может быть не так быстро, как сортировка встроенных типов.
Если производительность имеет решающее значение при сортировке пользовательских объектов, рассмотрите возможность использования ключевой функции, которая возвращает встроенный тип:
sorted_list = sorted(my_list, key=lambda x: x.value)
Послесловие
Преждевременная оптимизация, особенно в Python, — это зло.
Вам не следует разрабатывать все свое приложение с учетом конкретных оптимизаций в CPython, но полезно знать об этих оптимизациях: хорошее знание своих инструментов — это способ стать более опытным разработчиком.
Внимательное отношение к подобным оптимизациям позволит вам воспользоваться ими, когда этого требует ситуация, особенно когда производительность становится критической:
Рассмотрим сценарий, в котором ваша сортировка основана на временных метках: использование однородного списка целых чисел (временных меток Unix) вместо объектов datetime может эффективно использовать эту оптимизацию.
Однако важно помнить, что читаемость и удобство сопровождения кода должны иметь приоритет над такими оптимизациями.
Хотя важно знать об этих низкоуровневых деталях, не менее важно ценить высокоуровневые абстракции Python, которые делают его таким продуктивным языком.
Python — удивительный язык, и изучение его глубин поможет вам лучше его понять и стать лучшим программистом на Python.
-
 Повысьте успех разработки программного обеспечения: интеграция междисциплинарных навыков для достижения лучших результатовIn today's world of software development, success is more than just technical know-how. Teams that work well together and mix different skills in vari...программирование Опубликовано 7 ноября 2024 г.
Повысьте успех разработки программного обеспечения: интеграция междисциплинарных навыков для достижения лучших результатовIn today's world of software development, success is more than just technical know-how. Teams that work well together and mix different skills in vari...программирование Опубликовано 7 ноября 2024 г. -
WatchYourLAN - легкий сетевой IP-сканерОсновные возможности WatchYourLAN Отправлять уведомление, когда найден новый хост Отслеживание онлайн-/оффлайн-истории хостов Сохраняйте спис...программирование Опубликовано 7 ноября 2024 г.
-
Освоение глубоких ссылок и универсальных ссылок в React Native: OpenGraph Share и интеграция Node.jsСценарий Представьте, что у вас есть приложение для электронной коммерции под названием ShopEasy, и вы хотите, чтобы пользователи, которые на...программирование Опубликовано 7 ноября 2024 г.
-
Как я могу безопасно анализировать «расслабленный» JSON без использования eval?Разбор «расслабленного» JSON без рискованной оценкиJSON, широко используемый формат обмена данными, требует строгого синтаксиса с ключами в кавычках. ...программирование Опубликовано 7 ноября 2024 г.
-
Быстро и легко внедрите высокопроизводительную систему электронной коммерции с помощью Sponge+dtm.This article demonstrates how to use the Sponge framework to quickly build a simplified high-performance e-commerce system, implementing flash sale an...программирование Опубликовано 7 ноября 2024 г.
-
Что такое перехватчик выключения в Java и как его эффективно использовать?1. Понимание перехватчиков завершения работы Перехватчик завершения работы — это специальная конструкция в Java, которая позволяет вам зареги...программирование Опубликовано 7 ноября 2024 г.
-
Использование JavaScript для безопасного шифрования в веб-инструментахЭто метод, который разработчики используют для защиты конфиденциальной информации в программе от потенциальных злоумышленников. Шифрование преобразует...программирование Опубликовано 7 ноября 2024 г.
-
Как преобразовать java.util.Date в типы java.time?Преобразование java.util.Date в тип java.timeУстаревшие классы java.util.Date и Calendar известны своей сложностью и хлопотливость. Хотя для управлени...программирование Опубликовано 7 ноября 2024 г.
-
День f #daysofMiva Coding Challenge: значения и переменные в JSПривет, ребята. В последнее время я был настолько занят, что у меня даже не было времени задокументировать, как прошло мое путешествие? В любом случае...программирование Опубликовано 7 ноября 2024 г.
-
Ключевые особенности Python, которые нужно знать в 4Что общего у Spotify, Google, NASA и JP Morgan Chase? Все они ежедневно используют Python. Python — это впечатляющий и всесторонний язык программирова...программирование Опубликовано 7 ноября 2024 г.
-
Как можно реализовать оптимистическую блокировку в MySQL?Оптимистическая блокировка в MySQL: подробное объяснениеОптимистическая блокировка — это метод, используемый в системах управления базами данных для п...программирование Опубликовано 7 ноября 2024 г.
-
Как безопасно возвращать массивы из функций в C++?Возврат массивов из функций в C Попытка вернуть массивы из функций в C может привести к неожиданному поведению, как показано в следующем коде фрагмент...программирование Опубликовано 7 ноября 2024 г.
-
Как перенести атрибуты таблицы в CSS в HTML5?Переход атрибутов таблицы HTML5Функция проверки HTML5 Visual Studio определяет атрибуты cellpadding, cellspaceing, valign и align как недопустимые для...программирование Опубликовано 7 ноября 2024 г.
-
Почему я не могу использовать непостоянную переменную для определения размера массива в C++?Понимание ограничений на использование Const Int в качестве размера массиваВ C использование const int в качестве размера массива подлежит определенны...программирование Опубликовано 7 ноября 2024 г.
-
Как указать неоднозначный столбец user_id в предложении MySQL WHERE?Устранение неоднозначности в предложении WHERE 'user_id' MySQLПри работе с несколькими таблицами, которые имеют одно и то же имя столбца, MySQ...программирование Опубликовано 7 ноября 2024 г.















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









