 титульная страница > программирование > Magic Mushrooms: исследование и обработка нулевых данных с помощью Mage
титульная страница > программирование > Magic Mushrooms: исследование и обработка нулевых данных с помощью Mage
Magic Mushrooms: исследование и обработка нулевых данных с помощью Mage
 Просматривать:629
Просматривать:629
Mage — это мощный инструмент для задач ETL с функциями, позволяющими исследовать и анализировать данные, быстрой визуализацией с помощью шаблонов графиков и рядом других функций, которые превращают вашу работу с данными в нечто волшебное.
При обработке данных во время процесса ETL часто обнаруживаются недостающие данные, которые могут вызвать проблемы в будущем. В зависимости от действий, которые мы собираемся выполнять с набором данных, пустые данные могут быть весьма разрушительными.
Чтобы определить отсутствие данных в нашем наборе данных, мы можем использовать Python и библиотеку pandas для проверки данных, которые представляют нулевые значения, кроме того, мы можем создавать графики, которые еще более четко показывают влияние этих нулевых значений в наш набор данных.
Наш конвейер состоит из 4 этапов: начиная с загрузки данных, двух этапов обработки и экспорта данных.
Загрузчик данных
В этой статье мы будем использовать набор данных: Двоичное предсказание ядовитых грибов, которое доступно на Kaggle в рамках конкурса. Давайте воспользуемся набором обучающих данных, доступным на веб-сайте.
Давайте создадим шаг загрузчика данных, используя Python, чтобы иметь возможность загружать данные, которые мы собираемся использовать. Перед этим шагом я создал таблицу в базе данных Postgres, которая есть локально на моем компьютере, чтобы иметь возможность загружать данные. Поскольку данные находятся в Postgres, мы будем использовать уже определенный шаблон загрузки Postgres в Mage.
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from os import path if 'data_loader' not in globals(): from mage_ai.data_preparation.decorators import data_loader if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @data_loader def load_data_from_postgres(*args, **kwargs): """ Template for loading data from a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ query = 'SELECT * FROM mushroom' # Specify your SQL query here config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: return loader.load(query) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
В функции load_data_from_postgres() мы определим запрос, который будем использовать для загрузки таблицы в базу данных. В моем случае я настроил информацию о банке в файле io_config.yaml, где она определена как конфигурация по умолчанию, поэтому нам нужно только передать имя по умолчанию в переменную config_profile.
После выполнения блока мы воспользуемся функцией «Добавить диаграмму», которая предоставит информацию о наших данных через уже определенные шаблоны. Просто нажмите на значок рядом с кнопкой воспроизведения, отмеченный на изображении желтой линией.

Для дальнейшего изучения нашего набора данных мы выберем два параметра: summay_overview и Feature_profiles. С помощью summary_overview мы получаем информацию о количестве столбцов и строк в наборе данных. Мы также можем просмотреть общее количество столбцов по типам, например общее количество категориальных, числовых и логических столбцов. Feature_profiles, с другой стороны, представляет более описательную информацию о данных, такую как: тип, минимальное значение, максимальное значение. Среди другой информации мы можем даже визуализировать недостающие значения, которые являются предметом нашего рассмотрения.
Чтобы иметь возможность больше сосредоточиться на отсутствующих данных, давайте воспользуемся шаблоном: % отсутствующих значений, гистограмма с процентом отсутствующих данных в каждом из столбцов.
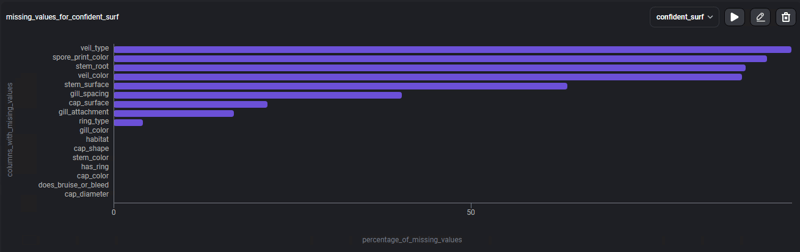
На графике представлены 4 столбца, в которых пропущенные значения соответствуют более чем 80% его содержимого, и другие столбцы, в которых представлены пропущенные значения, но в меньших количествах. Эта информация теперь позволяет нам искать различные стратегии для решения этой проблемы. нулевые данные
Трансформаторные колонны
Для столбцов, которые имеют более 80% нулевых значений, стратегия, которой мы будем следовать, будет заключаться в удалении столбцов из фрейма данных, выбирая столбцы, которые мы собираемся исключить из фрейма данных. Используя блок TRANSFORMER на языке Python, мы выберем опцию Удаление столбца .
from mage_ai.data_cleaner.transformer_actions.base import BaseAction from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action from pandas import DataFrame if 'transformer' not in globals(): from mage_ai.data_preparation.decorators import transformer if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @transformer def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame: """ Execute Transformer Action: ActionType.REMOVE Docs: https://docs.mage.ai/guides/transformer-blocks#remove-columns """ action = build_transformer_action( df, action_type=ActionType.REMOVE, arguments=['veil_type', 'spore_print_color', 'stem_root', 'veil_color'], axis=Axis.COLUMN, ) return BaseAction(action).execute(df) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
Внутри функции execute_transformer_action() мы вставим список с названием столбцов, которые хотим исключить из набора данных, в переменную аргументов, после этого шага просто выполняем блок.
Трансформатор Заполните пропущенные значения
Теперь для столбцов, которые имеют менее 80% нулевых значений, мы будем использовать стратегию Заполнить отсутствующие значения, поскольку в некоторых случаях, несмотря на отсутствие данных, мы заменим их такими значениями, как в среднем или модном, он может удовлетворить потребности в данных, не вызывая большого количества изменений в наборе данных, в зависимости от вашей конечной цели.
В некоторых задачах, таких как классификация, замена отсутствующих данных значением, соответствующим (режим, среднее, медиана) для набора данных, может способствовать алгоритму классификации, который мог бы прийти к другим выводам, если бы данные были удалены. как и в другой стратегии, которую мы использовали.
Чтобы принять решение относительно того, какое измерение мы будем использовать, мы снова воспользуемся функцией Mage Добавить диаграмму. Используя шаблон Наиболее частые значения мы можем визуализировать режим и частоту появления этого значения в каждом из столбцов.
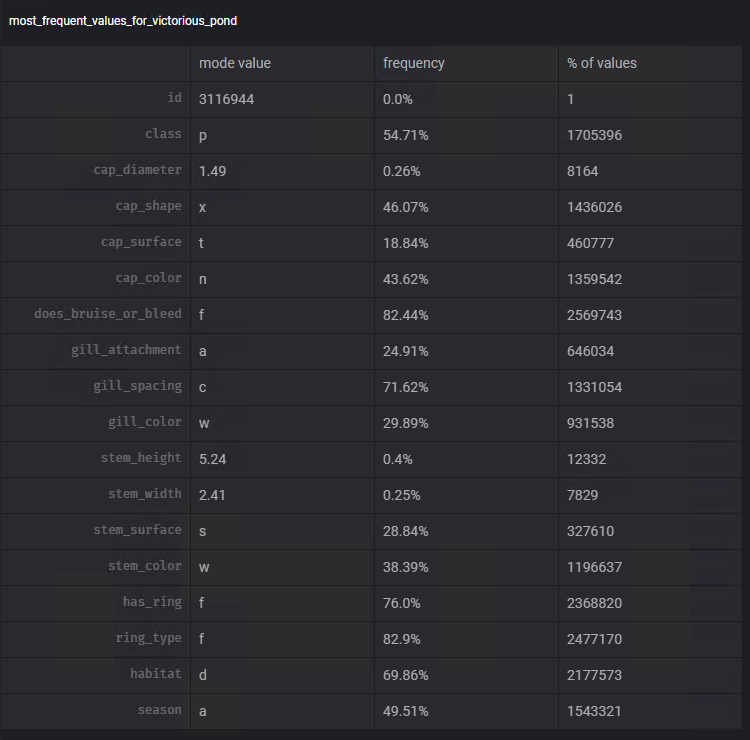
Следуя шагам, аналогичным предыдущим, мы воспользуемся преобразователем Заполним пропущенные значения, чтобы выполнить задачу по вычитанию недостающих данных, используя режим каждого из столбцов: steam_surface, gill_spacing, cap_surface , жаберное_прикрепление, тип_кольца.
from mage_ai.data_cleaner.transformer_actions.constants import ImputationStrategy
from mage_ai.data_cleaner.transformer_actions.base import BaseAction
from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis
from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action
from pandas import DataFrame
if 'transformer' not in globals():
from mage_ai.data_preparation.decorators import transformer
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@transformer
def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame:
"""
Execute Transformer Action: ActionType.IMPUTE
Docs: https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values
"""
action = build_transformer_action(
df,
action_type=ActionType.IMPUTE,
arguments=df.columns, # Specify columns to impute
axis=Axis.COLUMN,
options={'strategy': ImputationStrategy.MODE}, # Specify imputation strategy
)
return BaseAction(action).execute(df)
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'
В функции execute_transformer_action() мы определяем стратегию замены данных в словаре Python. Чтобы получить дополнительные варианты замены, просто откройте документацию по трансформатору: https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values.
Экспортер данных
При выполнении всех преобразований мы сохраним наш уже обработанный набор данных в той же базе данных Postgres, но теперь под другим именем, чтобы мы могли различать его. Используя блок Data Exporter и выбрав Postgres, мы определим схему и таблицу, которую хотим сохранить, помня, что конфигурации базы данных предварительно сохраняются в файле io_config.yaml.
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from pandas import DataFrame from os import path if 'data_exporter' not in globals(): from mage_ai.data_preparation.decorators import data_exporter @data_exporter def export_data_to_postgres(df: DataFrame, **kwargs) -> None: """ Template for exporting data to a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ schema_name = 'public' # Specify the name of the schema to export data to table_name = 'mushroom_clean' # Specify the name of the table to export data to config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: loader.export( df, schema_name, table_name, index=False, # Specifies whether to include index in exported table if_exists='replace', #Specify resolution policy if table name already exists )
Спасибо и увидимся в следующий раз?
репозиторий -> https://github.com/DeadPunnk/Mushrooms/tree/main
-
 Почему Java не может создать общие массивы?enderic Mrue Creation Error Вопрос: ] при попытке создать массив общих классов, используя выражение: ArrayList [2]; public static ArrayLi...программирование Опубликовано в 2025-07-12
Почему Java не может создать общие массивы?enderic Mrue Creation Error Вопрос: ] при попытке создать массив общих классов, используя выражение: ArrayList [2]; public static ArrayLi...программирование Опубликовано в 2025-07-12 -
Как эффективно вставить данные в несколько таблиц MySQL в одну транзакцию?mysql вставьте в несколько таблиц , пытаясь вставить данные в несколько таблиц с одним запросом MySQL, может дать неожиданные результаты. Хотя ...программирование Опубликовано в 2025-07-12
-
Как снять анонимные обработчики событий JavaScript чисто?] удаление слушателей анонимных событий добавление слушателей анонимных событий в элементы обеспечивают гибкость и простоту, но когда пришло врем...программирование Опубликовано в 2025-07-12
-
Существует ли разница в производительности между использованием зала и итератора для сбора сбора в Java?для каждого цикла Vs. iterator: эффективность в сборе Traversal введение при переселении коллекции в Java, выборе между использованием для...программирование Опубликовано в 2025-07-12
-
Почему мое фоновое изображение CSS появляется?Устранение неисправностей: CSS Фоновое изображение не отображается Вы столкнулись с проблемой, где ваше фоновое изображение не загружается, не...программирование Опубликовано в 2025-07-12
-
Как проанализировать числа в экспоненциальной нотации с помощью Decimal.parse ()?анализирует число из экспоненциальной нотации При попытке проанализировать строку, выраженную в экспоненциальной нотации, используя Tecimal.pa...программирование Опубликовано в 2025-07-12
-
Советы по плавающим изображениям в правой стороне дна и обертывание текстаПлавание изображения в правое внизу с текстом, обернутым вокруг в веб -дизайне, иногда желательно плавать изображение в нижний правый угол стр...программирование Опубликовано в 2025-07-12
-
Как правильно использовать как запросы с параметрами PDO?Использование подобных запросов в PDO При попытке реализовать подобные запросы в PDO, вы можете столкнуться с проблемами, подобными тем, котор...программирование Опубликовано в 2025-07-12
-
Как создать плавную анимацию CSS в левом правом для Div в его контейнере?generic css анимация для левого правого движения В этой статье мы рассмотрим создание общей анимации CSS, чтобы переместить дивирование влево ...программирование Опубликовано в 2025-07-12
-
Почему изображения все еще имеют границы в Chrome? `Граница: нет;` НЕПРАВИЛЬНОЕ РЕШЕНИЕ] Удаление границы изображения в Chrome . Одна частая проблема, встречающаяся при работе с изображениями в Chrome, и IE9 - это появление постоян...программирование Опубликовано в 2025-07-12
-
Почему Firefox отображает изображения, используя свойство CSS `content`?отображение изображений с URL содержимого в Firefox возникала проблема, где некоторые браузеры, в частности, Firefox, не отображаются изображе...программирование Опубликовано в 2025-07-12
-
Как избежать утечек памяти при наречном языке?утечка памяти в срезах Go Понимание утечек памяти в ломтиках Go может быть вызовом. Эта статья направлена на то, чтобы дать разъяснение, изучи...программирование Опубликовано в 2025-07-12
-
Объект: обложка не удается в IE и Edge, как исправить?object-fit: cover не удастся в IE и Edge, как исправить? В CSS для поддержания постоянной высоты изображения работает беспрепятственно через брау...программирование Опубликовано в 2025-07-12
-
FOSTAPI CUSTEM 404 Руководство по созданию страницCustom 404 не найдена страницей с FastApi , чтобы создать пользовательскую страницу 404, не найденная, FastApi предлагает несколько подходов. С...программирование Опубликовано в 2025-07-12
-
Какой метод более эффективен для обнаружения с точки зрения полигона: трассировка лучей или matplotlib \ path.contains_points?эффективное обнаружение с пунктом-в полигоне в Python определение того, находится ли точка в полигоне частой задачей в вычислительной геометрии....программирование Опубликовано в 2025-07-12















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









