 титульная страница > программирование > Создание приложения RAG с помощью LlamaIndex.ts и Azure OpenAI: начало работы!
титульная страница > программирование > Создание приложения RAG с помощью LlamaIndex.ts и Azure OpenAI: начало работы!
Создание приложения RAG с помощью LlamaIndex.ts и Azure OpenAI: начало работы!
 Просматривать:538
Просматривать:538
Поскольку ИИ продолжает формировать то, как мы работаем и взаимодействуем с технологиями, многие компании ищут способы использовать свои собственные данные в интеллектуальных приложениях. Если вы использовали такие инструменты, как ChatGPT или Azure OpenAI, вы уже знакомы с тем, как генеративный ИИ может улучшить процессы и улучшить взаимодействие с пользователем. Однако для получения по-настоящему персонализированных и релевантных ответов ваши приложения должны включать ваши собственные данные.
Именно здесь на помощь приходит технология дополненной генерации данных (RAG), обеспечивающая структурированный подход к интеграции поиска данных с ответами на основе искусственного интеллекта. С помощью таких платформ, как LlamaIndex, вы можете легко встроить эту возможность в свои решения, раскрывая весь потенциал ваших бизнес-данных.
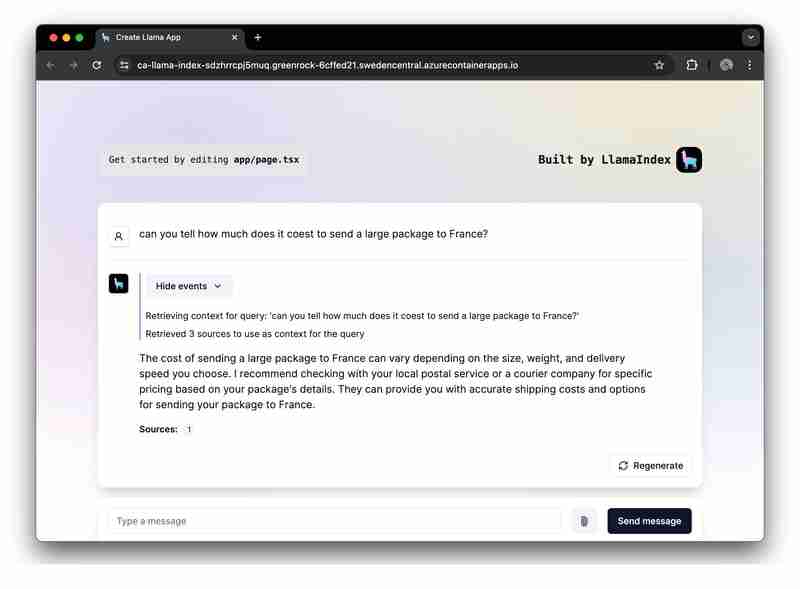
Хотите быстро запустить и изучить приложение? Кликните сюда.
Что такое RAG — генерация с расширенным поиском?
Поисковая дополненная генерация (RAG) — это платформа нейронной сети, которая расширяет возможности генерации текста с помощью искусственного интеллекта, включая компонент поиска для доступа к соответствующей информации и интеграции ваших собственных данных. Он состоит из двух основных частей:
- Retriever: плотная модель извлечения (например, на основе BERT), которая выполняет поиск в большом корпусе документов, чтобы найти соответствующие отрывки или информацию, связанную с данным запросом.
- Генератор: модель последовательности-последовательности (например, на основе BART или T5), которая принимает запрос и полученный текст в качестве входных данных и генерирует последовательный, контекстуально обогащенный ответ.
Поиск находит соответствующие документы, а генератор использует их для создания более точных и информативных ответов. Эта комбинация позволяет модели RAG эффективно использовать внешние знания, улучшая качество и релевантность создаваемого текста.
Как LlamaIndex реализует RAG?
Чтобы реализовать систему RAG с использованием LlamaIndex, выполните следующие общие шаги:
Прием данных:
- Загрузите свои документы в LlamaIndex.ts с помощью загрузчика документов, такого как SimpleDirectoryReader, который помогает импортировать данные из различных источников, таких как PDF-файлы, API или базы данных SQL.
- Разбивайте большие документы на более мелкие, удобные части с помощью SentenceSplitter.
Создание индекса:
- Создайте векторный индекс этих фрагментов документа с помощью VectorStoreIndex, что позволит эффективно выполнять поиск по сходству на основе встраивания.
- При необходимости для сложных наборов данных используйте методы рекурсивного поиска для управления иерархически структурированными данными и получения соответствующих разделов на основе запросов пользователей.
Настройка механизма запросов:
- Преобразуйте векторный индекс в механизм запросов с помощью asQueryEngine с такими параметрами, как схожестьTopK, чтобы определить, сколько наиболее важных документов следует получить.
- Для более сложных настроек создайте многоагентную систему, в которой каждый агент отвечает за определенные документы, а агент верхнего уровня координирует общий процесс поиска.
Поиск и генерация:
- Реализуйте конвейер RAG, определив целевую функцию, которая извлекает соответствующие фрагменты документов на основе запросов пользователей.
- Используйте RetrieverQueryEngine для выполнения фактического поиска и обработки запросов с дополнительными этапами постобработки, такими как повторное ранжирование полученных документов с помощью таких инструментов, как CohereRerank.
В качестве практического примера мы предоставили образец приложения, демонстрирующий полную реализацию RAG с использованием Azure OpenAI.
Пример практического применения RAG
Теперь мы сосредоточимся на создании приложения RAG с использованием LlamaIndex.ts (реализация LlamaIndex в TypeScipt) и Azure OpenAI и его развертывании в качестве бессерверных веб-приложений в приложениях-контейнерах Azure.
Требования для запуска образца
- Azure Developer CLI (azd): инструмент командной строки, позволяющий легко развернуть все приложение, включая серверную часть, внешний интерфейс и базы данных.
- Учетная запись Azure: для развертывания приложения вам понадобится учетная запись Azure. Чтобы начать работу, получите бесплатную учетную запись Azure и несколько кредитов.
На GitHub вы найдете проект для начала работы. Мы рекомендуем вам создать форк этого шаблона, чтобы вы могли свободно редактировать его при необходимости:

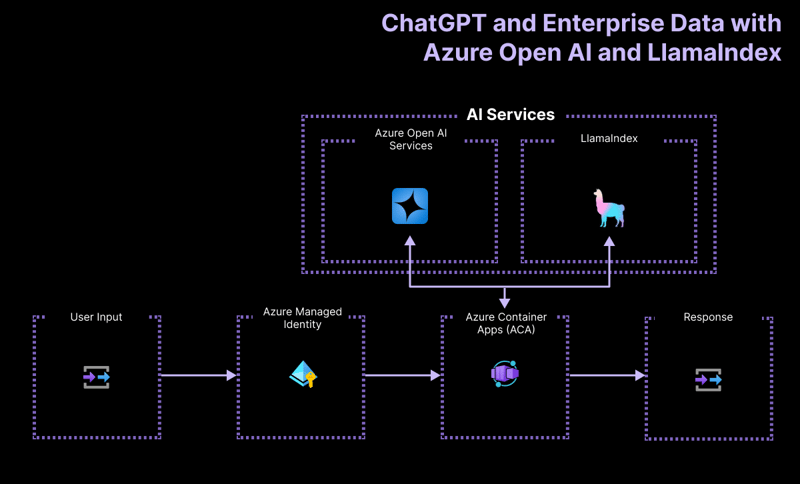
Высокоуровневая архитектура
Приложение проекта «Начало работы» построено на основе следующей архитектуры:
- Azure OpenAI: поставщик искусственного интеллекта, обрабатывающий запросы пользователя.
- LlamaIndex.ts: платформа, которая помогает принимать, преобразовывать и векторизировать контент (PDF-файлы) и создавать поисковый индекс.
- Приложения-контейнеры Azure: контейнерная среда, в которой размещается бессерверное приложение.
- Управляемая идентификация Azure: обеспечивает первоклассную безопасность и устраняет необходимость обработки учетных данных и ключей API.
Для получения более подробной информации о том, какие ресурсы развернуты, проверьте папку infra, доступную во всех наших примерах.
Примеры рабочих процессов пользователей
Пример приложения содержит логику для двух рабочих процессов:
-
Прием данных: данные извлекаются, векторизуются и создаются индексы поиска. Если вы хотите добавить больше файлов, например PDF-файлов или файлов Word, их следует добавить сюда.
npm run generate
Обслуживание запросов на подсказки: приложение получает подсказки пользователя, отправляет их в Azure OpenAI и дополняет эти подсказки, используя векторный индекс в качестве средства извлечения.
Запуск образца
Перед запуском примера убедитесь, что вы предоставили необходимые ресурсы Azure.
Чтобы запустить шаблон GitHub в GitHub Codespace, просто нажмите
В своем экземпляре Codespaces войдите в свою учетную запись Azure со своего терминала:
azd auth login
Предоставьте, упакуйте и разверните пример приложения в Azure с помощью одной команды:
azd up
Чтобы запустить и опробовать приложение локально, установите зависимости npm и запустите приложение:
npm install npm run dev
Приложение будет работать на порту 3000 в вашем экземпляре Codespaces или по адресу http://localhost:3000 в вашем браузере.
Заключение
В этом руководстве показано, как создать бессерверное приложение RAG (дополненная генерация данных) с использованием LlamaIndex.ts и Azure OpenAI, развернутого в Microsoft Azure. Следуя этому руководству, вы сможете использовать инфраструктуру Azure и возможности LlamaIndex для создания мощных приложений искусственного интеллекта, которые предоставляют контекстно-обогащенные ответы на основе ваших данных.
Мы рады видеть, что вы создадите с помощью этого приложения для начала работы. Не стесняйтесь создать его форк и поставить лайк репозиторию GitHub, чтобы получать последние обновления и функции.
-
 Как правильно использовать как запросы с параметрами PDO?Использование подобных запросов в PDO При попытке реализовать подобные запросы в PDO, вы можете столкнуться с проблемами, подобными тем, котор...программирование Опубликовано в 2025-07-08
Как правильно использовать как запросы с параметрами PDO?Использование подобных запросов в PDO При попытке реализовать подобные запросы в PDO, вы можете столкнуться с проблемами, подобными тем, котор...программирование Опубликовано в 2025-07-08 -
Как исправить \ "mysql_config не найдена \" Ошибка при установке MySQL-Python на Ubuntu/Linux?mysql-python error: "mysql_config не найдено" попытка установить Mysql-python на Ubuntu/linux box может столкнуться с сообщением об ...программирование Опубликовано в 2025-07-08
-
Как проанализировать числа в экспоненциальной нотации с помощью Decimal.parse ()?анализирует число из экспоненциальной нотации При попытке проанализировать строку, выраженную в экспоненциальной нотации, используя Tecimal.pa...программирование Опубликовано в 2025-07-08
-
Причины и решения для сбоя обнаружения лица: ошибка -215обработка ошибок: разрешение «ошибка: (-215)! Empty () в функции DetectMultiscale" в OpenCV при попытке использовать метод DeTectMultisca...программирование Опубликовано в 2025-07-08
-
Как правильно отобразить текущую дату и время в формате «DD/MM/yyyy HH: MM: Ss.SS» в Java?Как отобразить текущую дату и время в «dd/mm/yyyy hh: mm: ss.ss" format в предоставленном коде Java, выпуск с датой и временем в желании ...программирование Опубликовано в 2025-07-08
-
PHP Simplexml SAINGING XML Метод с пространством имен толстой кишкиparsing xml с пространством именами Colons в PHP Simplexml столкнулся с трудностями при разборе XML, содержащих теги Colons, такие как элемент...программирование Опубликовано в 2025-07-08
-
Как эффективно получить последнюю строку для каждого уникального идентификатора в PostgreSQL?postgresql: извлечение последней строки для каждого уникального идентификатора В Postgresql вы можете столкнуться с ситуациями, где вам необхо...программирование Опубликовано в 2025-07-08
-
Как я могу программно выбрать весь текст в Div на мыши щелкнуть?программно выбрать текст div на мышью щелкнут Вопрос , данный элемент div с текстовым контентом, как пользователь может программно выбрать весь...программирование Опубликовано в 2025-07-08
-
PHP Future: адаптация и инновациибудущее PHP будет достигнуто путем адаптации к новым технологическим тенденциям и внедрению инновационных функций: 1) адаптация к облачным вычисления...программирование Опубликовано в 2025-07-08
-
Eval () против AST.Literal_EVAL (): какая функция Python безопаснее для пользовательского ввода?взвешивание eval () и ast.literal_eval () в Python Security при обращении с вводом пользователя, это необходимо определить определение безопас...программирование Опубликовано в 2025-07-08
-
Можете ли вы использовать CSS для цветной консоли вывода в Chrome и Firefox?отображение цветов в консоли Javascript ] может ли использовать консоль Chrome для отображения цветного текста, такого как красный для ошибок, ...программирование Опубликовано в 2025-07-08
-
Как я могу настроить оптимизацию компиляции в компиляторе GO?настройка оптимизации компиляции в GO Compiler процесс компиляции по умолчанию в GO следует за конкретной стратегией оптимизации. Однако польз...программирование Опубликовано в 2025-07-08
-
Как загружать файлы с дополнительными параметрами с использованием кодирования Java.net.urlConnection и Multipart/Form Data?загрузка файлов с помощью http-запросов для загрузки файлов на сервер HTTP, в то же время представляя дополнительные параметры, Java.net.urlCo...программирование Опубликовано в 2025-07-08
-
Как объединить данные из трех таблиц MySQL в новую таблицу?mySQL: Creating a New Table from Data and Columns of Three TablesQuestion:How can I create a new table that combines selected data from three existing...программирование Опубликовано в 2025-07-08
-
Как разрешить расходы на путь модуля в Go Mod с помощью директивы «Заменить»?Распространение пути преодоления модуля в Go Mod При использовании MOD можно столкнуться с конфликтом, где 3 -й пакет импортирует другой пакет...программирование Опубликовано в 2025-07-08















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









