 титульная страница > программирование > Создание быстрой и эффективной системы семантического поиска с использованием OpenVINO и Postgres
титульная страница > программирование > Создание быстрой и эффективной системы семантического поиска с использованием OpenVINO и Postgres
Создание быстрой и эффективной системы семантического поиска с использованием OpenVINO и Postgres
 Просматривать:184
Просматривать:184

Фото Real-Napster на Pixabay
В одном из моих недавних проектов мне пришлось создать систему семантического поиска, которая могла бы масштабироваться с высокой производительностью и предоставлять ответы в режиме реального времени для поиска в отчетах. Для этого мы использовали PostgreSQL с pgvector на AWS RDS в сочетании с AWS Lambda. Задача заключалась в том, чтобы позволить пользователям осуществлять поиск, используя запросы на естественном языке, вместо того, чтобы полагаться на жесткие ключевые слова, при этом гарантируя, что ответы будут менее 1-2 секунд или даже меньше и могут использовать только ресурсы процессора.
В этом посте я расскажу о шагах, которые я предпринял для создания этой поисковой системы, от поиска до изменения рейтинга, а также об оптимизации, выполненной с использованием OpenVINO и интеллектуальной пакетной обработки для токенизации.
Обзор семантического поиска: поиск и изменение ранжирования
Современные поисковые системы обычно состоят из двух основных этапов: поиск и переранжирование.
1) Извлечение: Первый шаг включает в себя получение подмножества соответствующих документов на основе запроса пользователя. Это можно сделать с помощью предварительно обученных моделей внедрения, таких как малые и большие внедрения OpenAI, модели Embed Cohere или внедрения mxbai Mixbread. Поиск направлен на сужение пула документов путем измерения их сходства с запросом.
Вот упрощенный пример использования библиотеки преобразователей предложений Huggingface для поиска, которая является одной из моих любимых библиотек для этого:
from sentence_transformers import SentenceTransformer
import numpy as np
# Load a pre-trained sentence transformer model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# Sample query and documents (vectorize the query and the documents)
query = "How do I fix a broken landing gear?"
documents = ["Report 1 on landing gear failure", "Report 2 on engine problems"]
# Get embeddings for query and documents
query_embedding = model.encode(query)
document_embeddings = model.encode(documents)
# Calculate cosine similarity between query and documents
similarities = np.dot(document_embeddings, query_embedding)
# Retrieve top-k most relevant documents
top_k = np.argsort(similarities)[-5:]
print("Top 5 documents:", [documents[i] for i in top_k])
2) Реранжирование: После получения наиболее релевантных документов мы дополнительно улучшаем рейтинг этих документов с помощью модели кросс-кодирования. На этом этапе каждый документ более точно оценивается по отношению к запросу, уделяя особое внимание более глубокому пониманию контекста.
Изменение рейтинга полезно, поскольку оно добавляет дополнительный уровень уточнения за счет более точной оценки релевантности каждого документа.
Вот пример кода для изменения рейтинга с использованием кросс-кодировщика/ms-marco-TinyBERT-L-2-v2, облегченного кросс-кодировщика:
from sentence_transformers import CrossEncoder
# Load the cross-encoder model
cross_encoder = CrossEncoder("cross-encoder/ms-marco-TinyBERT-L-2-v2")
# Use the cross-encoder to rerank top-k retrieved documents
query_document_pairs = [(query, doc) for doc in documents]
scores = cross_encoder.predict(query_document_pairs)
# Rank documents based on the new scores
top_k_reranked = np.argsort(scores)[-5:]
print("Top 5 reranked documents:", [documents[i] for i in top_k_reranked])
Выявление узких мест: стоимость токенизации и прогнозирования
В ходе разработки я обнаружил, что этапы токенизации и прогнозирования занимают довольно много времени при обработке 1000 отчетов с настройками по умолчанию для преобразователей предложений. Это создало узкое место в производительности, тем более что мы стремились получать ответы в реальном времени.
Ниже я профилировал свой код с помощью SnakeViz для визуализации производительности:
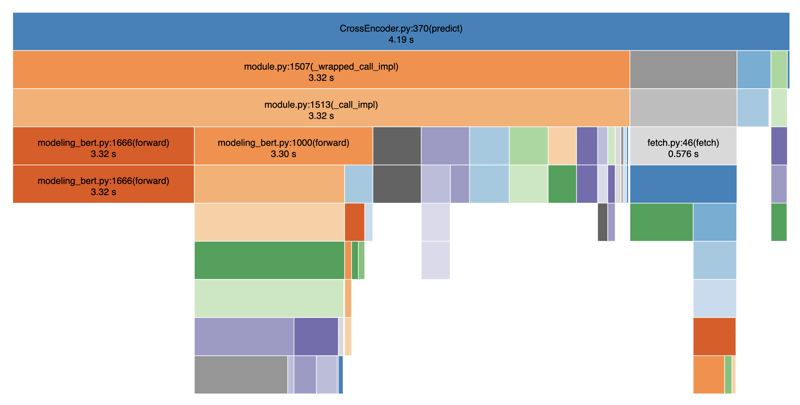
Как видите, этапы токенизации и прогнозирования выполняются непропорционально медленно, что приводит к значительным задержкам в предоставлении результатов поиска. В среднем это заняло около 4-5 секунд. Это связано с тем, что между этапами токенизации и прогнозирования существуют операции блокировки. Если мы также добавим другие операции, такие как вызов базы данных, фильтрацию и т. д., мы легко получим в общей сложности 8-9 секунд.
Оптимизация производительности с помощью OpenVINO
Вопрос, с которым я столкнулся, заключался в следующем: Можем ли мы сделать это быстрее? Ответ — да, используя OpenVINO, оптимизированный бэкэнд для вывода данных о ЦП. OpenVINO помогает ускорить вывод моделей глубокого обучения на оборудовании Intel, которое мы используем в AWS Lambda.
Пример кода для оптимизации OpenVINO
Вот как я интегрировал OpenVINO в поисковую систему, чтобы ускорить вывод:
import argparse
import numpy as np
import pandas as pd
from typing import Any
from openvino.runtime import Core
from transformers import AutoTokenizer
def load_openvino_model(model_path: str) -> Core:
core = Core()
model = core.read_model(model_path ".xml")
compiled_model = core.compile_model(model, "CPU")
return compiled_model
def rerank(
compiled_model: Core,
query: str,
results: list[str],
tokenizer: AutoTokenizer,
batch_size: int,
) -> np.ndarray[np.float32, Any]:
max_length = 512
all_logits = []
# Split results into batches
for i in range(0, len(results), batch_size):
batch_results = results[i : i batch_size]
inputs = tokenizer(
[(query, item) for item in batch_results],
padding=True,
truncation="longest_first",
max_length=max_length,
return_tensors="np",
)
# Extract input tensors (convert to NumPy arrays)
input_ids = inputs["input_ids"].astype(np.int32)
attention_mask = inputs["attention_mask"].astype(np.int32)
token_type_ids = inputs.get("token_type_ids", np.zeros_like(input_ids)).astype(
np.int32
)
infer_request = compiled_model.create_infer_request()
output = infer_request.infer(
{
"input_ids": input_ids,
"attention_mask": attention_mask,
"token_type_ids": token_type_ids,
}
)
logits = output["logits"]
all_logits.append(logits)
all_logits = np.concatenate(all_logits, axis=0)
return all_logits
def fetch_search_data(search_text: str) -> pd.DataFrame:
# Usually you would fetch the data from a database
df = pd.read_csv("cnbc_headlines.csv")
df = df[~df["Headlines"].isnull()]
texts = df["Headlines"].tolist()
# Load the model and rerank
openvino_model = load_openvino_model("cross-encoder-openvino-model/model")
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-2-v2")
rerank_scores = rerank(openvino_model, search_text, texts, tokenizer, batch_size=16)
# Add the rerank scores to the DataFrame and sort by the new scores
df["rerank_score"] = rerank_scores
df = df.sort_values(by="rerank_score", ascending=False)
return df
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Fetch search results with reranking using OpenVINO"
)
parser.add_argument(
"--search_text",
type=str,
required=True,
help="The search text to use for reranking",
)
args = parser.parse_args()
df = fetch_search_data(args.search_text)
print(df)
При таком подходе мы могли бы получить ускорение в 2–3 раза, сократив первоначальные 4–5 секунд до 1–2 секунд. Полный рабочий код находится на Github.
Точная настройка скорости: размер пакета и токенизация
Другим важным фактором повышения производительности стала оптимизация процесса токенизации и корректировка размера пакета и длины токена. Увеличив размер пакета (batch_size=16) и уменьшив длину токена (max_length=512), мы смогли распараллелить токенизацию и сократить накладные расходы на повторяющиеся операции. В наших экспериментах мы обнаружили, что значение Batch_size от 16 до 64 работает хорошо, а любое большее значение снижает производительность. Аналогичным образом мы остановились на значении max_length, равном 128, что вполне приемлемо, если средняя длина ваших отчетов относительно короткая. Благодаря этим изменениям мы добились общего ускорения в 8 раз, сократив время перераспределения до менее 1 секунды, даже на процессоре.
На практике это означало экспериментирование с различными размерами пакетов и длиной токенов, чтобы найти правильный баланс между скоростью и точностью для ваших данных. Благодаря этому мы значительно сократили время отклика, сделав поисковую систему масштабируемой даже при наличии 1000 отчетов.
Заключение
Используя OpenVINO и оптимизируя токенизацию и пакетную обработку, мы смогли создать высокопроизводительную систему семантического поиска, отвечающую требованиям реального времени при установке только на процессор. Фактически, мы получили общее ускорение в 8 раз. Сочетание поиска с использованием преобразователей предложений и переранжирования с помощью модели перекрестного кодирования создает мощный и удобный поиск.
Если вы создаете подобные системы с ограничениями по времени отклика и вычислительным ресурсам, я настоятельно рекомендую изучить OpenVINO и интеллектуальную пакетную обработку, чтобы повысить производительность.
Надеюсь, вам понравилась эта статья. Если эта статья оказалась для вас полезной, поставьте мне лайк, чтобы другие тоже могли ее найти, и поделитесь ею со своими друзьями. Следуйте за мной в Linkedin, чтобы быть в курсе моей работы. Спасибо за прочтение!
-
 Почему я получаю ошибку \ "class \ 'Ziparchive \' не найдена \" после установки archive_zip на моем сервере Linux?class 'Ziparchive' не найдена ошибка при установке Archive_zip на Linux Server симптома: при попытке запустить сценарий, который исп...программирование Опубликовано в 2025-07-03
Почему я получаю ошибку \ "class \ 'Ziparchive \' не найдена \" после установки archive_zip на моем сервере Linux?class 'Ziparchive' не найдена ошибка при установке Archive_zip на Linux Server симптома: при попытке запустить сценарий, который исп...программирование Опубликовано в 2025-07-03 -
Когда веб -приложение Go закроет подключение к базе данных?управление подключениями к базе данных в веб -приложениях GO в простых веб -приложениях, в которых используются базы данных, такие как PostgreSQ...программирование Опубликовано в 2025-07-03
-
Как Android отправляет данные POST на PHP Server?Отправка данных в Android введение Эта статья рассматривает необходимость отправки данных в сценарий PHP и отобразить результат в приложен...программирование Опубликовано в 2025-07-03
-
Как перенаправить несколько типов пользователей (студентов, учителей и администраторов) на их соответствующие действия в приложении Firebase?] red: Как перенаправить несколько типов пользователей на соответствующие действия понимание проблемы в огненном приложении, основанном авт...программирование Опубликовано в 2025-07-03
-
Как я могу программно выбрать весь текст в Div на мыши щелкнуть?программно выбрать текст div на мышью щелкнут Вопрос , данный элемент div с текстовым контентом, как пользователь может программно выбрать весь...программирование Опубликовано в 2025-07-03
-
Как я могу настроить оптимизацию компиляции в компиляторе GO?настройка оптимизации компиляции в GO Compiler процесс компиляции по умолчанию в GO следует за конкретной стратегией оптимизации. Однако польз...программирование Опубликовано в 2025-07-03
-
Почему мое фоновое изображение CSS появляется?Устранение неисправностей: CSS Фоновое изображение не отображается Вы столкнулись с проблемой, где ваше фоновое изображение не загружается, не...программирование Опубликовано в 2025-07-03
-
Почему я получаю ошибку «не удалось найти внедрение ошибки с шаблоном запроса» в моем запросе Silverlight Linq?] запроса. Отсутствие реализации: разрешение «не удалось найти« ошибки в приложении Silverlight, попытка установить подключение к базе данных с...программирование Опубликовано в 2025-07-03
-
Как эффективно выбрать столбцы в DataFrames Pandas?Выбор столбцов в Pandas DataFrames При работе с задачами манипуляции с данными выбор конкретных столбцов становится необходимым. В Pandas есть...программирование Опубликовано в 2025-07-03
-
Почему левые соединения выглядят как внутриполомы при фильтрации в предложении «Где в правом таблице»?Left Join Conundrum: часы ведьмы, когда он превращается во внутреннее соединение в сфере мастера базы данных, выполнение сложных поисков данных ...программирование Опубликовано в 2025-07-03
-
Советы по плавающим изображениям в правой стороне дна и обертывание текстаПлавание изображения в правое внизу с текстом, обернутым вокруг в веб -дизайне, иногда желательно плавать изображение в нижний правый угол стр...программирование Опубликовано в 2025-07-03
-
Как упростить анализ JSON в PHP для многомерных массивов?sacksing json с php пытаться анализировать данные JSON в PHP может быть сложной, особенно при работе с многомерными массивами. Чтобы упростить п...программирование Опубликовано в 2025-07-03
-
Как эффективно повторить строковые символы для вдавления в C#?повторяя строку для вдавления , когда обрабатывает строку, основанную на глубине элемента, удобно иметь эффективный способ вернуть строку, повт...программирование Опубликовано в 2025-07-03
-
Как эффективно вставить данные в несколько таблиц MySQL в одну транзакцию?mysql вставьте в несколько таблиц , пытаясь вставить данные в несколько таблиц с одним запросом MySQL, может дать неожиданные результаты. Хотя ...программирование Опубликовано в 2025-07-03
-
Почему Java не может создать общие массивы?enderic Mrue Creation Error Вопрос: ] при попытке создать массив общих классов, используя выражение: ArrayList [2]; public static ArrayLi...программирование Опубликовано в 2025-07-03















Изучайте китайский
- 1 Как сказать «гулять» по-китайски? 走路 Китайское произношение, 走路 Изучение китайского языка
- 2 Как сказать «Сесть на самолет» по-китайски? 坐飞机 Китайское произношение, 坐飞机 Изучение китайского языка
- 3 Как сказать «сесть на поезд» по-китайски? 坐火车 Китайское произношение, 坐火车 Изучение китайского языка
- 4 Как сказать «поехать на автобусе» по-китайски? 坐车 Китайское произношение, 坐车 Изучение китайского языка
- 5 Как сказать «Ездить» по-китайски? 开车 Китайское произношение, 开车 Изучение китайского языка
- 6 Как будет плавание по-китайски? 游泳 Китайское произношение, 游泳 Изучение китайского языка
- 7 Как сказать «кататься на велосипеде» по-китайски? 骑自行车 Китайское произношение, 骑自行车 Изучение китайского языка
- 8 Как поздороваться по-китайски? 你好Китайское произношение, 你好Изучение китайского языка
- 9 Как сказать спасибо по-китайски? 谢谢Китайское произношение, 谢谢Изучение китайского языка
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









