 Primeira página > Programação > Rastreando Saúde com Engenharia de Dados - Capítulo Otimização de Refeições
Primeira página > Programação > Rastreando Saúde com Engenharia de Dados - Capítulo Otimização de Refeições
Rastreando Saúde com Engenharia de Dados - Capítulo Otimização de Refeições
 Navegar:163
Navegar:163
Introdução
Olá pessoal! Este será meu primeiro post, então seja duro comigo, critique-me onde você acha que posso melhorar e com certeza levarei isso em consideração na próxima vez.
Nos últimos meses, tenho me dedicado profundamente à saúde, principalmente fazendo exercícios e observando o que como, e agora que acho que tenho um conhecimento sólido sobre isso, queria ver como posso otimizar ainda mais o caso haja algumas coisas que eu possa ter perdido.
Objetivos
Para este capítulo, desejo estudar minhas refeições ao longo de minha jornada de saúde e concluir com um plano de refeições para a próxima semana que (1) atinja minhas necessidades mínimas de proteína, (2) não ultrapasse meu limite de calorias, (3) atende aos meus requisitos mínimos de fibra e (4) minimiza custos.
Conjunto de dados
Começamos apresentando o conjunto de dados, os alimentos que rastreamos usando o Cronometer. O Cronometer tem trabalhado comigo lado a lado em minha jornada e agora estarei exportando os dados que inseri para analisar por mim mesmo com os objetivos que listei anteriormente.
Felizmente para mim, o Cronometer me permite exportar dados para um arquivo .csv com facilidade em seu site.
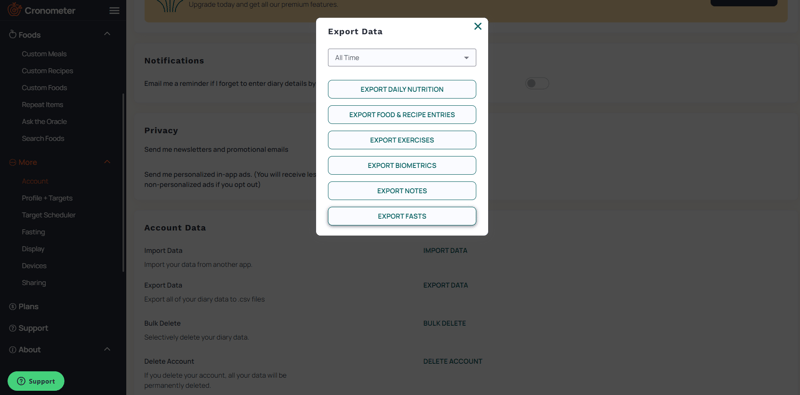
Para este capítulo, exportaremos apenas o conjunto de dados 'Entradas de alimentos e receitas'.
Começamos examinando os dados que obtivemos de 'Entradas de alimentos e receitas'. O conjunto de dados é muito abrangente, o que tenho certeza que será ótimo para capítulos futuros! Neste capítulo, queremos limitá-lo ao nome do alimento, sua quantidade, proteínas, calorias e fibras.
# Importing and checking out the dataset
df = pd.read_csv("servings.csv")
df.head()
Pré-processamento de dados
Já temos algumas colunas definidas para nós, em ‘Nome do alimento’, ‘Quantidade’, ‘Energia (kcal)’, ‘Fibra (g)’ e ‘Proteína (g)’. Perfeito! Agora, a única coisa que falta é obter o custo de cada alimento em uma determinada quantia, pois não estava sendo rastreado no conjunto de dados. Felizmente para mim, fui eu quem inseriu os dados em primeiro lugar para poder inserir os preços que conheço. No entanto, não inserirei preços para todos os alimentos. Em vez disso, pedimos ao nosso bom e velho amigo ChatGPT uma estimativa e preenchemos os preços que sabemos ajustando o arquivo .csv. Armazenamos o novo conjunto de dados em 'cost.csv', que derivamos pegando as colunas 'Nome do alimento' e 'Quantidade' do conjunto de dados original.
# Group by 'Food Name' and collect unique 'Amount' for each group
grouped_df = df.groupby('Food Name')['Amount'].unique().reset_index()
# Expand the DataFrame so each unique 'Food Name' and 'Amount' is on a separate row
expanded_df = grouped_df.explode('Amount')
# Export the DataFrame to a CSV file
expanded_df.to_csv('grouped_food_names_amounts.csv')
# Read the added costs and save as a new DataFrame
df_cost = pd.read_csv("cost.csv").dropna()
df_cost.head()
Alguns alimentos foram descartados simplesmente porque eram estranhamente específicos e não estariam no escopo dos dados de serem de baixa caloria, nutritivos e/ou baratos (ou simplesmente porque eu não poderia me incomodar em fazer a receita novamente ). Precisaríamos então mesclar dois quadros de dados, o conjunto de dados original e aquele com o custo, para obter o suposto conjunto de dados “final”. Como o conjunto de dados original contém entradas para cada alimento, isso significa que o conjunto de dados original contém várias entradas do mesmo alimento, especialmente aqueles que como repetidamente (ou seja, ovos, peito de frango, arroz). Também queremos preencher colunas sem valores com '0', pois a fonte mais provável de problemas aqui seriam as colunas 'Energia', 'Fibra', 'Proteína' e 'Preço'.
merged_df = pd.merge(df, df_cost, on=['Food Name', 'Amount'], how='inner') specified_columns = ['Food Name', 'Amount', 'Energy (kcal)', 'Fiber (g)', 'Protein (g)', 'Price'] final_df = merged_df[specified_columns].drop_duplicates() final_df.fillna(0, inplace=True) final_df.head()
Otimização
Perfeito! Nosso conjunto de dados está finalizado e agora começamos com a segunda parte, otimização. Relembrando os objetivos do estudo, queremos identificar o menor custo dada uma quantidade mínima de proteínas e fibras, e uma quantidade máxima de calorias. A opção aqui é forçar cada combinação, mas na indústria o termo apropriado é "Programação Linear" ou "Otimização Linear", mas não me cite sobre isso. Desta vez, usaremos puLP que é uma biblioteca Python que visa fazer exatamente isso. Não sei muito sobre como usá-lo além de seguir o modelo, então navegue na documentação em vez de ler minha explicação pouco profissional de como funciona. Mas para aqueles que querem ouvir minha explicação casual sobre o assunto, estamos basicamente resolvendo para y = ax1 bx2 cx3 ... zxn.
O modelo que seguiremos é o modelo do Estudo de Caso do problema de Blending, onde seguimos objetivos semelhantes, mas neste caso, queremos misturar nossas refeições ao longo do dia. Para começar, precisaríamos converter o DataFrame em dicionários, especificamente, o 'Nome do alimento' como uma lista de variáveis independentes que servem como uma série de x's, depois Energia, Fibra, Proteína e Preço como um dicionário tal que 'Nome do alimento': valor para cada um. Observe que o Valor será renunciado de agora em diante e, em vez disso, será concatenado com o 'Nome do Alimento', pois não o usaremos quantitativamente.
# Concatenate Amount into Food Name
final_df['Food Name'] = final_df['Food Name'] ' ' final_df['Amount'].astype(str)
food_names = final_df['Food Name'].tolist()
# Create dictionaries for 'Energy', 'Fiber', 'Protein', and 'Price'
energy_dict = final_df.set_index('Food Name')['Energy (kcal)'].to_dict()
fiber_dict = final_df.set_index('Food Name')['Fiber (g)'].to_dict()
fiber_dict['Gardenia, High Fiber Wheat Raisin Loaf 1.00 Slice'] = 3
fiber_dict['Gardenia, High Fiber Wheat Raisin Loaf 2.00 Slice'] = 6
protein_dict = final_df.set_index('Food Name')['Protein (g)'].to_dict()
price_dict = final_df.set_index('Food Name')['Price'].to_dict()
# Display the results
print("Food Names Array:", food_names)
print("Energy Dictionary:", energy_dict)
print("Fiber Dictionary:", fiber_dict)
print("Protein Dictionary:", protein_dict)
print("Price Dictionary:", price_dict)
Para quem não tem visão aguçada, continue rolando. Para aqueles que notaram as estranhas 2 linhas de código, deixe-me explicar. Eu vi isso enquanto fazia compras, mas as informações nutricionais do pão de passas de trigo com alto teor de fibra da Gardenia não têm, na verdade, 1 fatia com 9 gramas de fibra, ele tem 2 fatias por 6 gramas. Isso é um grande problema e me causou uma dor imensurável saber que os valores podem estar incorretos devido a uma entrada incorreta de dados ou a uma mudança de ingredientes que fez com que os dados ficassem desatualizados. De qualquer forma, eu precisava que essa justiça fosse corrigida e não aceitarei menos Fiber do que mereço. Se movendo.
Vamos direto inserir nossos valores usando o modelo dos dados do estudo de caso. Definimos variáveis para representar os valores mínimos que queremos de Proteína e Fibra, bem como o máximo de calorias que estamos dispostos a consumir. Em seguida, deixamos o código do modelo mágico fazer seu trabalho e obter os resultados.
# Set variables
min_protein = 120
min_fiber = 40
max_energy = 1500
# Just read the case study at https://coin-or.github.io/pulp/CaseStudies/a_blending_problem.html. They explain it way better than I ever could.
prob = LpProblem("Meal Optimization", LpMinimize)
food_vars = LpVariable.dicts("Food", food_names, 0)
prob = (
lpSum([price_dict[i] * food_vars[i] for i in food_names]),
"Total Cost of Food daily",
)
prob = (
lpSum([energy_dict[i] * food_vars[i] for i in food_names]) = min_fiber,
"FiberRequirement",
)
prob = (
lpSum([protein_dict[i] * food_vars[i] for i in food_names]) >= min_protein,
"ProteinRequirement",
)
prob.writeLP("MealOptimization.lp")
prob.solve()
print("Status:", LpStatus[prob.status])
for v in prob.variables():
if v.varValue > 0:
print(v.name, "=", v.varValue)
print("Total Cost of Food per day = ", value(prob.objective))
Resultados

Para obter 120 gramas de proteína e 40 gramas de fibra, eu precisaria gastar 128 pesos filipinos em 269 gramas de filé de peito de frango e 526 gramas de feijão mungo. Isso não parece nada ruim, considerando o quanto eu amo os dois ingredientes. Com certeza vou experimentar, talvez por uma semana ou um mês, só para ver quanto dinheiro eu economizaria apesar de ter nutrição suficiente.
Este capítulo de Tracking Health with Data Engineering foi isso, se você quiser ver os dados que trabalhei neste capítulo, visite o repositório ou visite o notebook desta página. Deixe um comentário se tiver algum e tente se manter saudável.
-
 Como resolver \ "Recusou -se a carregar erros de script ..." devido à política de segurança de conteúdo do Android?revelando o mistério: Erros de diretiva de política de segurança do conteúdo encontrando o erro enigmático "recusou -se a carregar o scri...Programação Postado em 2025-04-27
Como resolver \ "Recusou -se a carregar erros de script ..." devido à política de segurança de conteúdo do Android?revelando o mistério: Erros de diretiva de política de segurança do conteúdo encontrando o erro enigmático "recusou -se a carregar o scri...Programação Postado em 2025-04-27 -
Maneira eficiente do Python de remover tags html do textoremovendo tags html em python para uma representação textual intocada manipular respostas html geralmente envolve a extração de texto relevant...Programação Postado em 2025-04-27
-
Como combinar dados de três tabelas MySQL em uma nova tabela?mysql: Criando uma nova tabela a partir de dados e colunas de três tabelas pergunta: como eu posso criar uma tabela que a tabela se selecio...Programação Postado em 2025-04-27
-
Posso migrar minha criptografia de McRypt para OpenSSL e descriptografar dados criptografados por McRypt usando o OpenSSL?Atualizando minha biblioteca de criptografia de McRypt para OpenSSL posso atualizar minha biblioteca de criptografia de McHRPT para openssl? N...Programação Postado em 2025-04-27
-
A diferença entre o processamento de sobrecarga de sobrecarga de função PHP e C ++php function sobrecarregando: desvendando o enigma de uma perspectiva C como um desenvolvedor C experiente se aventurando no reino do PHP, você ...Programação Postado em 2025-04-27
-
Por que não está aparecendo na minha imagem de fundo do CSS?SOLHAÇÃO DE TRABALHO: CSS Imagem de fundo não apareceu Você encontrou um problema em que sua imagem em segundo plano falha, apesar das seguint...Programação Postado em 2025-04-27
-
Como analisar as matrizes json em Go usando o pacote `json`?analisando as matrizes json em go com o pacote json Problem: como você pode analisar uma string json representando um array em Go usando o p...Programação Postado em 2025-04-27
-
Como adicionar eixos e tags aos arquivos PNG em Java?como anotar um arquivo png com eixos e etiquetas em java adicionar eixos e etiquetas a uma imagem png existente pode ser um desafio. Em vez de...Programação Postado em 2025-04-27
-
Como corrigir “Erro geral: o servidor MySQL 2006 desapareceu” ao inserir dados?Como resolver "Erro geral: o servidor MySQL de 2006 desapareceu" ao inserir registrosIntrodução:A inserção de dados em um banco de dados MyS...Programação Postado em 2025-04-27
-
Você pode usar o CSS para colorir a saída do console no Chrome e no Firefox?exibindo cores no javascript Console é possível usar o console do Chrome para exibir texto colorido, como vermelho para erros, laranja para al...Programação Postado em 2025-04-27
-
Qual método para declarar várias variáveis em JavaScript é mais sustentável?declarando várias variáveis em javascript: explorando dois métodos em javascript, os desenvolvedores geralmente encontram a necessidade de d...Programação Postado em 2025-04-27
-
Como posso substituir com eficiência várias substringas em uma string java?substituindo várias substâncias em uma string com eficiência em java quando confrontado com a necessidade de substituir várias substringas den...Programação Postado em 2025-04-27
-
Como inserir com eficiência dados em várias tabelas MySQL em uma transação?mysql Inserir em múltiplas tabelas tentando inserir dados em várias tabelas com uma única consulta MySQL pode produzir resultados inesperados....Programação Postado em 2025-04-27
-
Como remover emojis das cordas em Python: um guia para iniciantes para corrigir erros comuns?removendo emojis de strings em python o código Python fornecido para remover emojis falha porque contém syntaxe erros. As cadeias de unicode d...Programação Postado em 2025-04-27
-
Por que o Microsoft Visual C ++ falha ao implementar corretamente a instanciação do modelo bifásico?O mistério do modelo de duas fases "quebrado" bifásia instanciação no Microsoft Visual C Declaração de Problema: STRAGLES Expressa...Programação Postado em 2025-04-27















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









