
O princípio para construir CNNs regulares equivalentes
 Navegar:488
Navegar:488
The one principle is simply stated as 'Let the kernel rotate' and we will focus in this article on how you can apply it in your architectures.
Equivariant architectures allow us to train models which are indifferent to certain group actions.
To understand what this exactly means, let us train this simple CNN model on the MNIST dataset (a dataset of handwritten digits from 0-9).
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.cl1 = nn.Conv2d(in_channels=1, out_channels=8, kernel_size=3, padding=1)
self.max_1 = nn.MaxPool2d(kernel_size=2)
self.cl2 = nn.Conv2d(in_channels=8, out_channels=16, kernel_size=3, padding=1)
self.max_2 = nn.MaxPool2d(kernel_size=2)
self.cl3 = nn.Conv2d(in_channels=16, out_channels=16, kernel_size=7)
self.dense = nn.Linear(in_features=16, out_features=10)
def forward(self, x: torch.Tensor):
x = nn.functional.silu(self.cl1(x))
x = self.max_1(x)
x = nn.functional.silu(self.cl2(x))
x = self.max_2(x)
x = nn.functional.silu(self.cl3(x))
x = x.view(len(x), -1)
logits = self.dense(x)
return logits
| Accuracy on test | Accuracy on 90-degree rotated test |
|---|---|
| 97.3% | 15.1% |
Table 1: Test accuracy of the SimpleCNN model
As expected, we get over 95% accuracy on the testing dataset, but what if we rotate the image by 90 degrees? Without any countermeasures applied, the results drop to just slightly better than guessing. This model would be useless for general applications.
In contrast, let us train a similar equivariant architecture with the same number of parameters, where the group actions are exactly the 90-degree rotations.
| Accuracy on test | Accuracy on 90-degree rotated test |
|---|---|
| 96.5% | 96.5% |
Table 2: Test accuracy of the EqCNN model with the same amount of parameters as the SimpleCNN model
The accuracy remains the same, and we did not even opt for data augmentation.
These models become even more impressive with 3D data, but we will stick with this example to explore the core idea.
In case you want to test it out for yourself, you can access all code written in both PyTorch and JAX for free under Github-Repo, and training with Docker or Podman is possible with just two commands.
Have fun!
So What is Equivariance?
Equivariant architectures guarantee stability of features under certain group actions. Groups are simple structures where group elements can be combined, reversed, or do nothing.
You can look up the formal definition on Wikipedia if you are interested.
For our purposes, you can think of a group of 90-degree rotations acting on square images. We can rotate an image by 90, 180, 270, or 360 degrees. To reverse the action, we apply a 270, 180, 90, or 0-degree rotation respectively. It is straightforward to see that we can combine, reverse, or do nothing with the group denoted as C4 . The image visualizes all actions on an image.
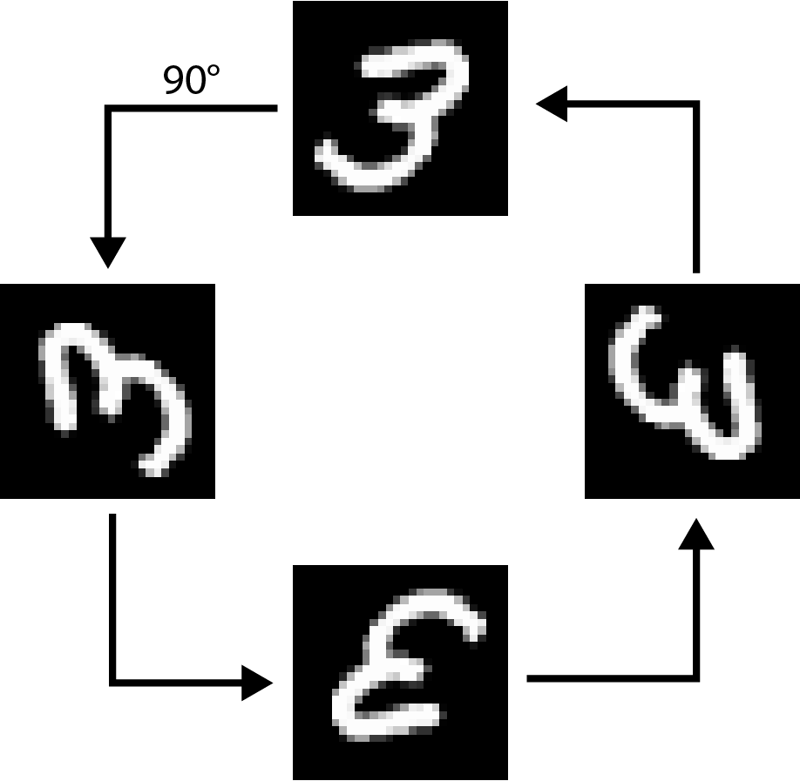
Figure 1: Rotated MNIST image by 90°, 180°, 270°, 360°, respectively
Now, given an input image
x
, our CNN model classifier
fθ
, and an arbitrary 90-degree rotation
g
, the equivariant property can be expressed as
fθ(rotate x by g)=fθ(x)
Generally speaking, we want our image-based model to have the same outputs when rotated.
As such, equivariant models promise us architectures with baked-in symmetries. In the following section, we will see how our principle can be applied to achieve this property.
How to Make Our CNN Equivariant
The problem is the following: When the image rotates, the features rotate too. But as already hinted, we could also compute the features for each rotation upfront by rotating the kernel.
We could actually rotate the kernel, but it is much easier to rotate the feature map itself, thus avoiding interference with PyTorch's autodifferentiation algorithm altogether.
So, in code, our CNN kernel
x = nn.functional.silu(self.cl1(x))
now acts on all four rotated images:
x_0 = x x_90 = torch.rot90(x, k=1, dims=(2, 3)) x_180 = torch.rot90(x, k=2, dims=(2, 3)) x_270 = torch.rot90(x, k=3, dims=(2, 3)) x_0 = nn.functional.silu(self.cl1(x_0)) x_90 = nn.functional.silu(self.cl1(x_90)) x_180 = nn.functional.silu(self.cl1(x_180)) x_270 = nn.functional.silu(self.cl1(x_270))
Or more compactly written as a 3D convolution:
self.cl1 = nn.Conv3d(in_channels=1, out_channels=8, kernel_size=(1, 3, 3)) ... x = torch.stack([x_0, x_90, x_180, x_270], dim=-3) x = nn.functional.silu(self.cl1(x))
The resulting equivariant model has just a few lines more compared to the version above:
class EqCNN(nn.Module):
def __init__(self):
super(EqCNN, self).__init__()
self.cl1 = nn.Conv3d(in_channels=1, out_channels=8, kernel_size=(1, 3, 3))
self.max_1 = nn.MaxPool3d(kernel_size=(1, 2, 2))
self.cl2 = nn.Conv3d(in_channels=8, out_channels=16, kernel_size=(1, 3, 3))
self.max_2 = nn.MaxPool3d(kernel_size=(1, 2, 2))
self.cl3 = nn.Conv3d(in_channels=16, out_channels=16, kernel_size=(1, 5, 5))
self.dense = nn.Linear(in_features=16, out_features=10)
def forward(self, x: torch.Tensor):
x_0 = x
x_90 = torch.rot90(x, k=1, dims=(2, 3))
x_180 = torch.rot90(x, k=2, dims=(2, 3))
x_270 = torch.rot90(x, k=3, dims=(2, 3))
x = torch.stack([x_0, x_90, x_180, x_270], dim=-3)
x = nn.functional.silu(self.cl1(x))
x = self.max_1(x)
x = nn.functional.silu(self.cl2(x))
x = self.max_2(x)
x = nn.functional.silu(self.cl3(x))
x = x.squeeze()
x = torch.max(x, dim=-1).values
logits = self.dense(x)
return logits
But why is this equivariant to rotations?
First, observe that we get four copies of each feature map at each stage. At the end of the pipeline, we combine all of them with a max operation.
This is key, the max operation is indifferent to which place the rotated version of the feature ends up in.
To understand what is happening, let us plot the feature maps after the first convolution stage.
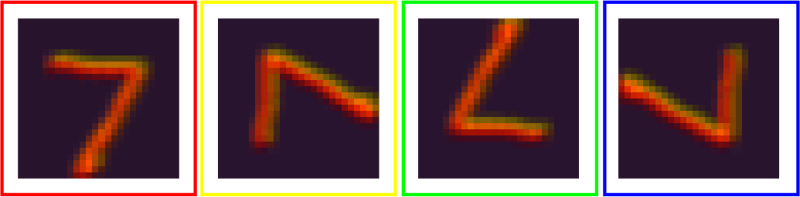
Figure 2: Feature maps for all four rotations
And now the same features after we rotate the input by 90 degrees.
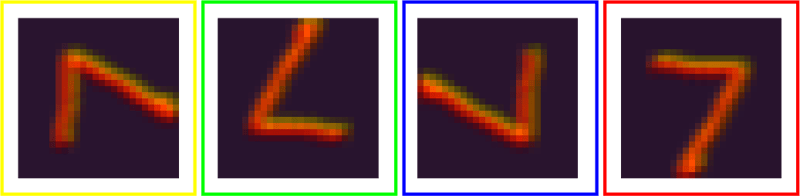
Figure 3: Feature maps for all four rotations after the input image was rotated
I color-coded the corresponding maps. Each feature map is shifted by one. As the final max operator computes the same result for these shifted feature maps, we obtain the same results.
In my code, I did not rotate back after the final convolution, since my kernels condense the image to a one-dimensional array. If you want to expand on this example, you would need to account for this fact.
Accounting for group actions or "kernel rotations" plays a vital role in the design of more sophisticated architectures.
Is it a Free Lunch?
No, we pay in computational speed, inductive bias, and a more complex implementation.
The latter point is somewhat solved with libraries such as E3NN, where most of the heavy math is abstracted away. Nevertheless, one needs to account for a lot during architecture design.
One superficial weakness is the 4x computational cost for computing all rotated feature layers. However, modern hardware with mass parallelization can easily counteract this load. In contrast, training a simple CNN with data augmentation would easily exceed 10x in training time. This gets even worse for 3D rotations where data augmentation would require about 500x the training amount to compensate for all possible rotations.
Overall, equivariance model design is more often than not a price worth paying if one wants stable features.
What is Next?
Equivariant model designs have exploded in recent years, and in this article, we barely scratched the surface. In fact, we did not even exploit the full C4 group yet. We could have used full 3D kernels. However, our model already achieves over 95% accuracy, so there is little reason to go further with this example.
Besides CNNs, researchers have successfully translated these principles to continuous groups, including SO(2) (the group of all rotations in the plane) and SE(3) (the group of all translations and rotations in 3D space).
In my experience, these models are absolutely mind-blowing and achieve performance, when trained from scratch, comparable to the performance of foundation models trained on multiple times larger datasets.
Let me know if you want me to write more on this topic.
Further References
In case you want a formal introduction to this topic, here is an excellent compilation of papers, covering the complete history of equivariance in Machine Learning.
AEN
I actually plan to create a deep-dive, hands-on tutorial on this topic. You can already sign up for my mailing list, and I will provide you with free versions over time, along with a direct channel for feedback and Q&A.
See you around :)
-
 Configurações do usuário do aplicativo Android e a melhor maneira de armazenar dados confidenciaisarmazenando configurações do usuário em aplicativos Android: explorando as opções uma das considerações principais ao desenvolver aplicativos An...Programação Postado em 2025-04-19
Configurações do usuário do aplicativo Android e a melhor maneira de armazenar dados confidenciaisarmazenando configurações do usuário em aplicativos Android: explorando as opções uma das considerações principais ao desenvolver aplicativos An...Programação Postado em 2025-04-19 -
Eval () vs. AST.LITERAL_EVAL (): Qual função Python é mais segura para a entrada do usuário?pesando avaliação () e ast.literal_eval () na python Security Ao lidar com a entrada do usuário, é imperativo priorizar a segurança. Eval (), ...Programação Postado em 2025-04-19
-
Por que minhas imagens não podem ser enviadas para o banco de dados MySQL?carregando imagens no banco de dados MySQL usando o código php nesta pergunta de programação, um usuário encontra um problema ao tentar fazer up...Programação Postado em 2025-04-19
-
Como resolver discrepâncias do caminho do módulo no Go Mod usando a diretiva substituição?superando a discrepância do caminho do módulo em Go Mod Ao utilizar Go Mod, é possível encontrar um conflito em que um pacote de terceiros imp...Programação Postado em 2025-04-19
-
Como configurar o carregamento preguiçoso para o relacionamento jpa onetoone?configurando declarativamente a busca preguiçosa para o jpa onetoone relações Uma otimização comum em aplicativos JPA é ativar a busca lento p...Programação Postado em 2025-04-19
-
Qual método é mais eficiente para a detecção de ponto em polígono: rastreamento de raio ou path.contains_points?detecção de ponto-em-polígono eficiente em python determinar se um ponto está dentro de um polígono é uma tarefa frequente na geometria computac...Programação Postado em 2025-04-19
-
VariedadeOs métodos são FNs que podem ser chamados em objetos Matrizes são objetos, portanto, eles também têm métodos no JS. Flice (Begin): Extra...Programação Postado em 2025-04-19
-
Você pode usar o CSS para colorir a saída do console no Chrome e no Firefox?exibindo cores no javascript Console é possível usar o console do Chrome para exibir texto colorido, como vermelho para erros, laranja para al...Programação Postado em 2025-04-19
-
Como distinguir corretamente os valores não definidos e nulos em Go?distinguindo corretamente entre não definido vs. valores vazios Ao trabalhar com estruturas em Go, pode ser crucial para diferenciar os valores ...Programação Postado em 2025-04-19
-
Como acessar dinamicamente variáveis globais em JavaScript?acessando variáveis globais dinamicamente pelo nome em javascript obtendo acesso a variáveis globais durante o tempo de execução pode ser um...Programação Postado em 2025-04-19
-
Por que não está aparecendo na minha imagem de fundo do CSS?SOLHAÇÃO DE TRABALHO: CSS Imagem de fundo não apareceu Você encontrou um problema em que sua imagem em segundo plano falha, apesar das seguint...Programação Postado em 2025-04-19
-
Quando evitar campos de java estático e por quêexplorando a natureza e as nuances dos campos estáticos em java Problem: desenvolvedores geralmente encontram a necessidade de compartilha...Programação Postado em 2025-04-19
-
Como exibir corretamente a data e a hora atuais em formato "dd/mm/yyyy hh: mm: ss.ss" em java?como exibir a data e a hora atuais em "dd/mm/yyyy hh: mm: ss.ss" formato no código java fornecido, o problema com a exibição da data...Programação Postado em 2025-04-19
-
Como enviar uma solicitação de postagem bruta com o CURL no PHP?como enviar uma solicitação de postagem bruta usando o CURL em php em php, o CURL é uma biblioteca popular para enviar http requests. Este art...Programação Postado em 2025-04-19
-
Como verificar se um objeto tem um atributo específico no Python?Método para determinar o atributo de objeto Existence Esta consulta busca um método para verificar a presença de um atributo específico em um ...Programação Postado em 2025-04-19















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









