 Primeira página > Programação > O que é mais rápido e barato para converter arquivos na AWS: Polar ou Pandas?
Primeira página > Programação > O que é mais rápido e barato para converter arquivos na AWS: Polar ou Pandas?
O que é mais rápido e barato para converter arquivos na AWS: Polar ou Pandas?
 Navegar:399
Navegar:399
Ambos oferecem uma ampla gama de ferramentas e vantagens que podem nos fazer duvidar de qual dos dois escolher em algum momento. Não se trata de mudar todos os processos da empresa para que passem a usar Polars ou uma “morte” aos Pandas (isto não vai acontecer num futuro imediato). Trata-se de conhecer outras ferramentas que podem nos ajudar a reduzir custos e tempo nos processos, obtendo resultados iguais ou melhores.
Quando usamos serviços em nuvem, priorizamos certos fatores, incluindo seu custo. Os serviços que utilizo para este processo são AWS Lambda com o tempo de execução Python 3.10 e S3 para armazenar o arquivo bruto e o arquivo convertido em parquet.
A intenção é obter um arquivo CSV como dados brutos e processá-lo com pandas e polar com o intuito de verificar qual dessas duas bibliotecas nos oferece melhor otimização de recursos como memória e peso do arquivo resultante.
]Pandas
É uma biblioteca Python especializada em manipulação e análise de dados, é escrita em C e seu lançamento inicial foi em 2008.
*Polares *
É uma biblioteca Python e Rust especializada em manipulação e análise de dados que permite processos paralelos e é escrita principalmente em Rust e foi lançada em 2022.
A arquitetura do processo:
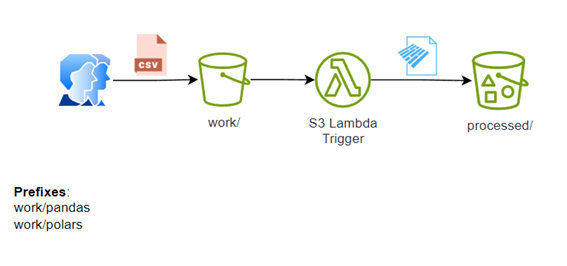
O projeto é um tanto simples como mostrado na arquitetura: O usuário deposita um arquivo CSV em work/pandas ou work/porlas e inicia automaticamente o gatilho s3 para processar o arquivo para convertê-lo em parquet e depositá-lo em processado.
Neste pequeno projeto use dois lambdas com a seguinte configuração:
Memória: 2GB
Memória efêmera: 2 GB
Tempo de vida: 600 segundos
Requisitos
Lambda com pandas: Pandas, Numpy e Pyarrow
Lambda com polares: Polares
O conjunto de dados usado para a comparação está disponível no kaggle com o nome “Rotten Tomatoes Movie Reviews – 1,44M rows” ou pode ser baixado aqui.
O repositório completo está disponível no GitHub e pode ser clonado aqui.
Tamanho ou Peso
O lambda que o Pandas usa requer mais dois plugins para criar um arquivo parquet, neste caso é o PyArrow e uma versão específica do numpy para a versão do Pandas que eu estava usando. Como resultado, obtivemos um lambda com peso ou tamanho de 74,4 MB, algo muito próximo do limite que a AWS nos permite para o peso do lambda.
O lambda com Polars não requer outro plugin como o PyArrow, o que torna a vida mais simples e reduz o tamanho do lambda para menos da metade. Como resultado, nosso lambda tem um peso ou tamanho de 30,6 MB em relação ao primeiro, nos dando espaço para instalar outras dependências que possamos precisar para nosso processo de transformação.
Desempenho
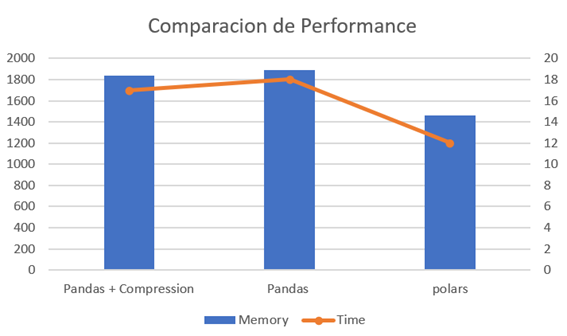
O lambda com Pandas foi otimizado para usar compressão após a primeira versão, porém seu comportamento também foi analisado.
Pandas
Demorou 18 segundos para processar o conjunto de dados e utilizou 1894 MB de memória para processar o arquivo CSV e gerar um arquivo Parquet em comparação com as outras versões, foi a que mais consumiu tempo e recursos.
Compressão Pandas
Adicionar uma linha de código permitiu melhorar um pouco em relação à versão anterior (Pandas), demorou 17 segundos para processar o conjunto de dados e utilizou 1837 MB, o que não representa uma melhoria significativa no tempo de processamento e computacional, mas sim no tamanho. do arquivo resultante.
Polares
Demorou 12 segundos para processar o mesmo conjunto de dados e usei apenas 1462 MB, comparado aos dois anteriores representa uma economia de tempo de 44,44% e menor consumo de memória.
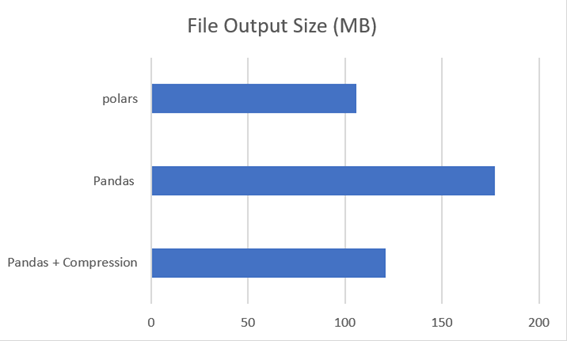
Tamanho do arquivo de saída
Pandas
O lambda em que não foi estabelecido um processo de compressão gerou um arquivo parquet de 177,4 MB.
Compressão Pandas
Ao configurar a compactação no lambda, não gero um arquivo parquet de 121,1 MB. Uma pequena linha ou opção nos ajudou a reduzir o tamanho do arquivo em 31,74%. Considerando que não é uma alteração significativa de código, é uma opção muito boa.
Polares
A Polars gerou um arquivo de 105,8 MB que, adquirido com a primeira versão do Pandas, representa uma economia de 40,36% e 12,63% em relação à versão Pandas com compressão.
Conclusão
Não é necessário alterar todos os processos internos que utilizam Pandas para que agora utilizem Polars, porém, é importante considerar que se estamos falando de milhares ou milhões de execuções de lambda, utilizar Polars nos ajudará não só na implantação tempo, mas também nos ajudará a ter um custo menor devido à cobrança baseada no tempo que a AWS faz para serviços sem servidor, como Lambda.
Da mesma forma, quando traduzimos esses 40,36% em milhões de arquivos estamos falando de GBs ou TBs, algo que teria um impacto significativo dentro de uma casa Datalake ou Dataware ou mesmo em um armazenamento frio de arquivos.
A redução com Polars não se limitaria apenas a esses dois fatores, pois afetaria muito a saída de dados e/ou objetos da AWS por ser um serviço que tem um custo.
-
 Como resolver o erro \ "Uso inválido da função do grupo \" no MySQL ao encontrar a contagem máxima?como recuperar a contagem máxima usando o mysql em mysql, você pode encontrar um problema enquanto tenta encontrar a contagem máxima de valore...Programação Postado em 2025-04-04
Como resolver o erro \ "Uso inválido da função do grupo \" no MySQL ao encontrar a contagem máxima?como recuperar a contagem máxima usando o mysql em mysql, você pode encontrar um problema enquanto tenta encontrar a contagem máxima de valore...Programação Postado em 2025-04-04 -
Como exibir corretamente a data e a hora atuais em formato "dd/mm/yyyy hh: mm: ss.ss" em java?como exibir a data e a hora atuais em "dd/mm/yyyy hh: mm: ss.ss" formato no código java fornecido, o problema com a exibição da data...Programação Postado em 2025-04-04
-
Como corrigir “Erro geral: o servidor MySQL 2006 desapareceu” ao inserir dados?Como resolver "Erro geral: o servidor MySQL de 2006 desapareceu" ao inserir registrosIntrodução:A inserção de dados em um banco de dados MyS...Programação Postado em 2025-04-04
-
Como posso concatenar com segurança o texto e os valores ao construir consultas SQL em Go?concatenando texto e valores em go sql Queries Ao construir uma consulta SQL texth e, em codificação, e a signa e a consulta de syntax e a sín...Programação Postado em 2025-04-04
-
Qual método é mais eficiente para a detecção de ponto em polígono: rastreamento de raio ou path.contains_points?detecção de ponto-em-polígono eficiente em python determinar se um ponto está dentro de um polígono é uma tarefa frequente na geometria computac...Programação Postado em 2025-04-04
-
Eval () vs. AST.LITERAL_EVAL (): Qual função Python é mais segura para a entrada do usuário?pesando avaliação () e ast.literal_eval () na python Security Ao lidar com a entrada do usuário, é imperativo priorizar a segurança. Eval (), ...Programação Postado em 2025-04-04
-
Como posso substituir com eficiência várias substringas em uma string java?substituindo várias substâncias em uma string com eficiência em java quando confrontado com a necessidade de substituir várias substringas den...Programação Postado em 2025-04-04
-
Como criar uma animação CSS esquerda-direita suave para uma div em seu contêiner?Animação CSS genérica para o movimento esquerdo-direita Neste artigo, exploraremos a criação de uma animação CSS genérica para mover uma divis...Programação Postado em 2025-04-04
-
VariedadeOs métodos são FNs que podem ser chamados em objetos Matrizes são objetos, portanto, eles também têm métodos no JS. Flice (Begin): Extra...Programação Postado em 2025-04-04
-
Tags de formatação HTMLElementos de formatação HTML **HTML Formatting is a process of formatting text for better look and feel. HTML provides us ability to form...Programação Postado em 2025-04-04
-
Como posso executar várias instruções SQL em uma única consulta usando node-mysql?suporte de consulta multi-statements em node-mysql em node.js, a pergunta surge ao executar múltiplas declarações SQL em uma única dúvida usan...Programação Postado em 2025-04-04
-
Como posso ler com eficiência um arquivo grande em ordem inversa usando o Python?lendo um arquivo em ordem inversa em python se você estiver trabalhando com um arquivo grande e precisar ler seus conteúdos da última linha pa...Programação Postado em 2025-04-04
-
Como posso recuperar com eficiência valores de atributo de arquivos XML usando PHP?recuperando valores do atributo dos arquivos xml em php todo desenvolvedor encontra a necessidade de analisar arquivos xml e extrair valores e...Programação Postado em 2025-04-04
-
Como posso manter a renderização de células JTable personalizada após a edição de células?MANAZENDO JTABLE CELUMENTE renderização após a célula edit em uma jtable, implementar capacidades de renderização e edição de células personal...Programação Postado em 2025-04-04
-
Como posso selecionar programaticamente todo o texto dentro de uma div em mouse clique?selecionando programaticamente o texto div no mouse click question dado um elemento Div com conteúdo de texto, como o usuário pode selecionar ...Programação Postado em 2025-04-04















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









