
Como usar o bate-papo da Nvidia com o RTX AI Chatbot em seu computador
 Navegar:440
Navegar:440
A Nvidia lançou o Chat with RXT, um chatbot de IA que opera no seu PC e oferece recursos semelhantes ao ChatGPT e muito mais! Tudo que você precisa é de uma GPU Nvidia RTX e está tudo pronto para começar a usar o novo chatbot AI da Nvidia.
O que é Nvidia Chat com RTX?
Nvidia Chat com RTX é um software de IA que permite executar um modelo de linguagem grande (LLM) localmente em seu computador. Portanto, em vez de ficar online para usar um chatbot de IA como o ChatGPT, você pode usar o Chat com RTX offline sempre que quiser.
O Chat with RTX usa TensorRT-LLM, aceleração RTX e um Mistral 7-B LLM quantizado para fornecer desempenho rápido e respostas de qualidade equivalentes a outros chatbots de IA online. Ele também fornece geração aumentada de recuperação (RAG), permitindo que o chatbot leia seus arquivos e habilite respostas personalizadas com base nos dados que você fornece. Isso permite que você personalize o chatbot para fornecer uma experiência mais pessoal.
Se você quiser experimentar o Nvidia Chat com RTX, veja como fazer o download, instalar e configurá-lo em seu computador.
Como baixar e instalar o bate-papo com RTX

A Nvidia tornou muito mais fácil executar um LLM localmente em seu computador. Para executar o Chat with RTX, você só precisa baixar e instalar o aplicativo, como faria com qualquer outro software. No entanto, o Chat with RTX possui alguns requisitos mínimos de especificação para instalação e uso adequado.
GPU RTX série 30 ou série 40 16 GB de RAM 100 GB de espaço de memória livre Windows 11Se o seu PC atender aos requisitos mínimos de sistema, você pode prosseguir e instalar o aplicativo.
Etapa 1: Baixe o arquivo ZIP do Chat com RTX.Download: Bate-papo com RTX (grátis - download de 35 GB)Etapa 2: Extraia o arquivo ZIP clicando com o botão direito e selecionando uma ferramenta de arquivamento de arquivo como 7Zip ou clicando duas vezes no arquivo e selecionando Extrair tudo. Etapa 3: Abra a pasta extraída e clique duas vezes em setup.exe. Siga as instruções na tela e marque todas as caixas durante o processo de instalação personalizada. Depois de clicar em Avançar, o instalador baixará e instalará o LLM e todas as dependências.
A instalação do Chat com RTX levará algum tempo para terminar, pois baixa e instala uma grande quantidade de dados. Após o processo de instalação, clique em Fechar e pronto. Agora é hora de você experimentar o aplicativo.
Como usar o Nvidia Chat com RTX
Embora você possa usar o Chat com RTX como um chatbot de IA online normal, sugiro fortemente que você verifique sua funcionalidade RAG, que permite personalizar sua saída com base nos arquivos aos quais você dá acesso.
Etapa 1: Criar pasta RAG
Para começar a usar RAG no Chat com RTX, crie uma nova pasta para armazenar os arquivos que você deseja que a IA analise.
Após a criação, coloque seus arquivos de dados na pasta. Os dados armazenados podem abranger muitos tópicos e tipos de arquivos, como documentos, PDFs, texto e vídeos. No entanto, você pode limitar o número de arquivos colocados nesta pasta para não afetar o desempenho. Mais dados para pesquisar significa que o Chat com RTX levará mais tempo para retornar respostas para consultas específicas (mas isso também depende do hardware).
Agora que seu banco de dados está pronto, você pode configurar o Chat com RTX e começar a usá-lo para responder suas dúvidas e dúvidas.
Etapa 2: configurar o ambiente
Abra o bate-papo com RTX. Deve ser semelhante à imagem abaixo.
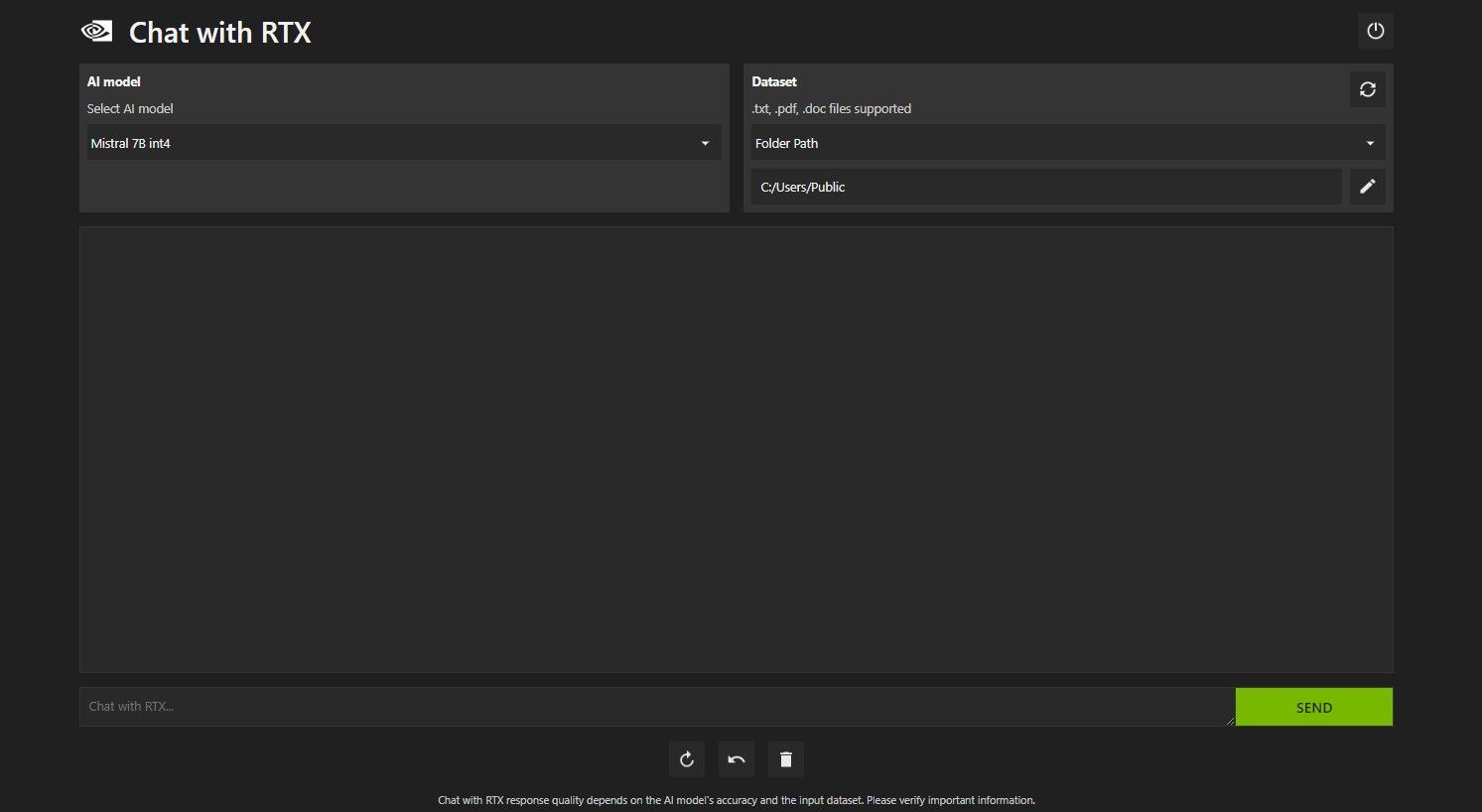
Em Conjunto de dados, certifique-se de que a opção Caminho da pasta esteja selecionada. Agora clique no ícone de edição abaixo (o ícone da caneta) e selecione a pasta que contém todos os arquivos que você deseja que o Chat with RTX leia. Você também pode alterar o modelo de IA se outras opções estiverem disponíveis (no momento em que este artigo foi escrito, apenas o Mistral 7B estava disponível).
Agora você está pronto para usar o Chat com RTX.
Etapa 3: Faça suas perguntas no bate-papo com RTX!
Existem várias maneiras de consultar o Chat com RTX. A primeira é usá-lo como um chatbot de IA normal. Perguntei ao Chat with RTX sobre os benefícios de usar um LLM local e fiquei satisfeito com a resposta. Não foi muito profundo, mas preciso o suficiente.
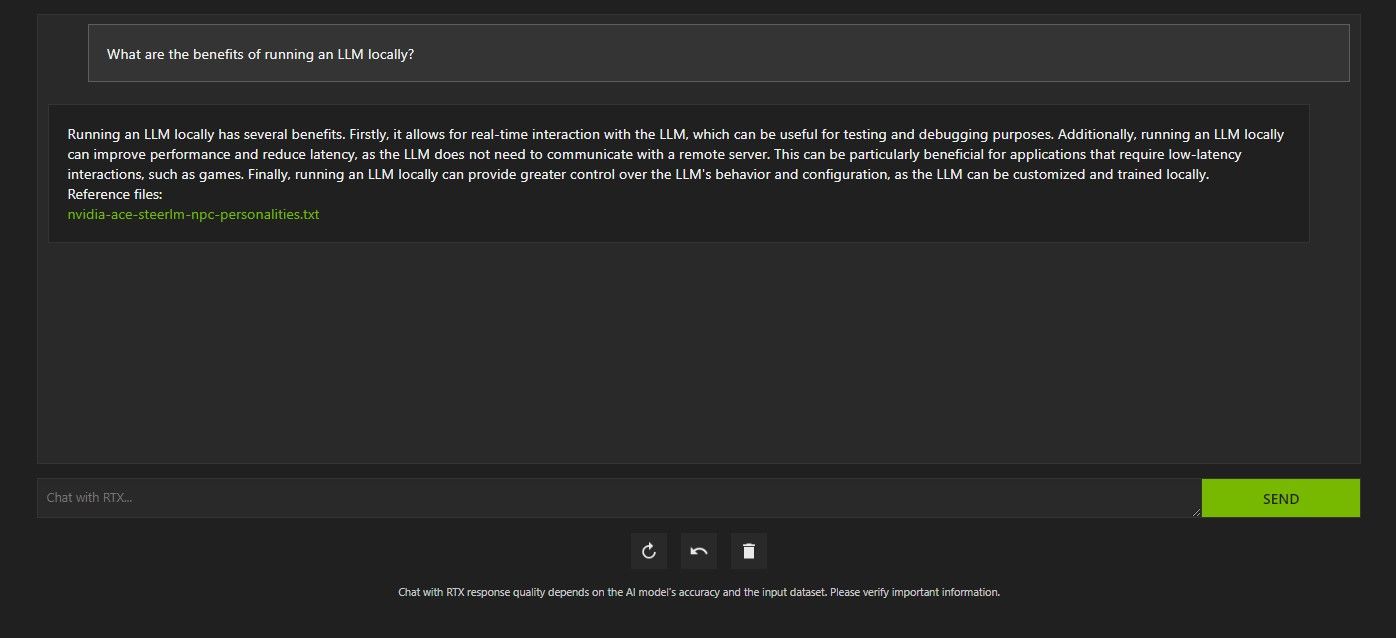
Mas como o Chat with RTX é compatível com RAG, você também pode usá-lo como um assistente pessoal de IA.
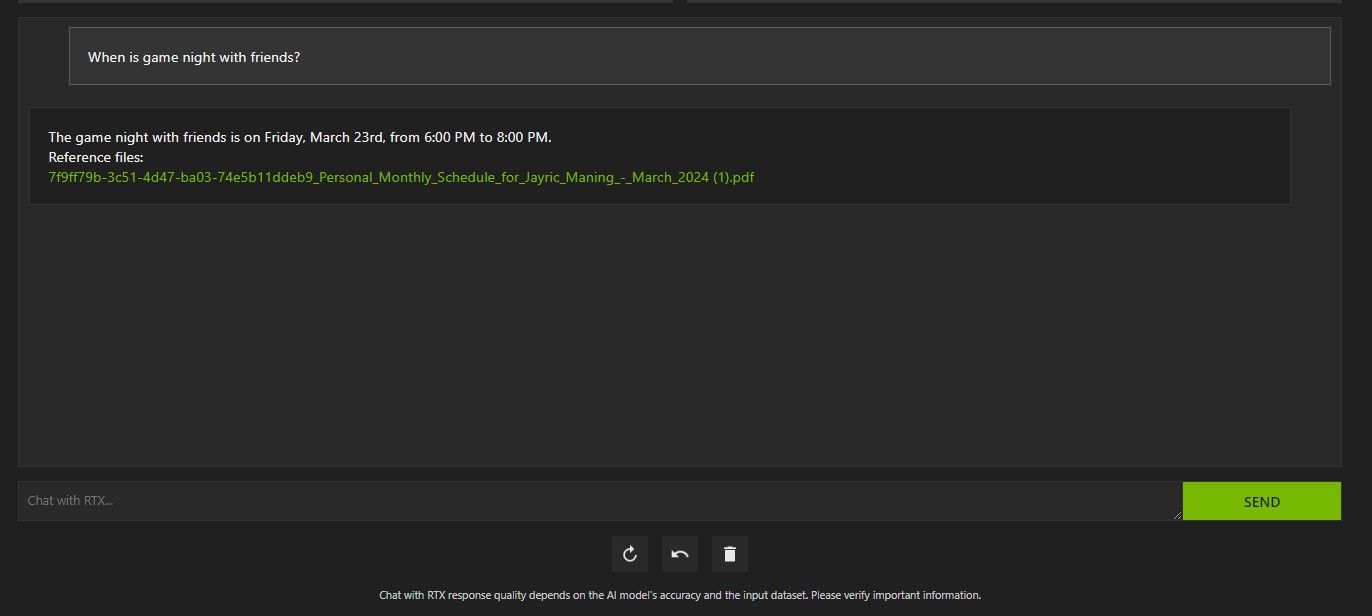
Acima, usei o Chat com RTX para perguntar sobre minha agenda. Os dados vieram de um arquivo PDF contendo minha agenda, calendário, eventos, trabalho e assim por diante. Nesse caso, o Chat with RTX extraiu os dados corretos do calendário dos dados; você terá que manter seus arquivos de dados e datas do calendário atualizados para que recursos como esse funcionem corretamente até que haja integrações com outros aplicativos.
Há muitas maneiras de usar o Chat com o RAG da RTX a seu favor. Por exemplo, você pode usá-lo para ler documentos jurídicos e fornecer um resumo, gerar código relevante para o programa que está desenvolvendo, obter destaques com marcadores sobre um vídeo que você está ocupado demais para assistir e muito mais!
Etapa 4: recurso bônus
Além de sua pasta de dados local, você pode usar o Chat com RTX para analisar vídeos do YouTube. Para fazer isso, em Conjunto de dados, altere o Caminho da pasta para URL do YouTube.
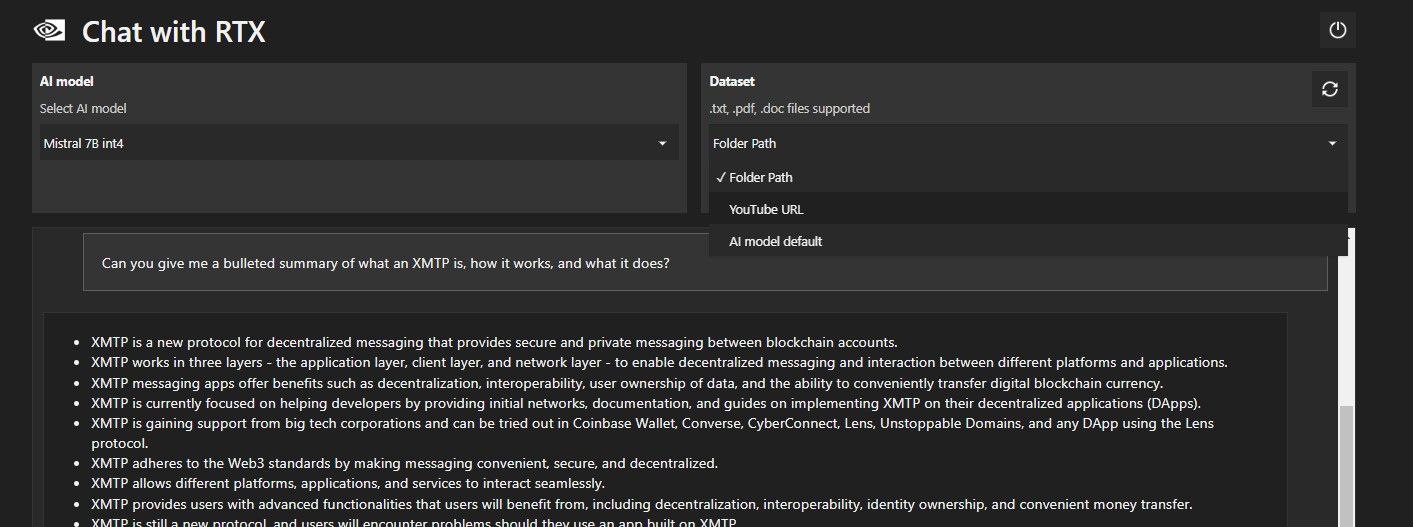
Copie o URL do YouTube que deseja analisar e cole-o abaixo do menu suspenso. Então pergunte!
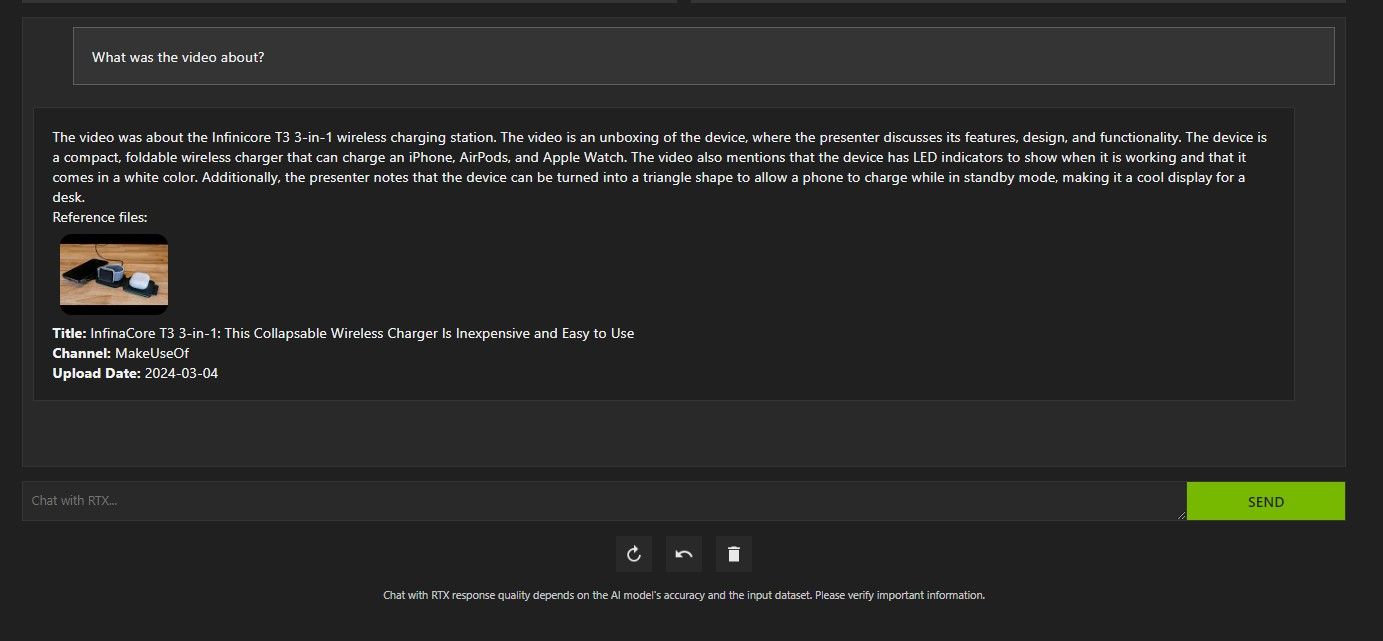
A análise de vídeo do Chat with RTX no YouTube foi muito boa e forneceu informações precisas, por isso pode ser útil para pesquisas, análises rápidas e muito mais.
O bate-papo da Nvidia com RTX é bom?
ChatGPT fornece funcionalidade RAG. Alguns chatbots locais de IA têm requisitos de sistema significativamente mais baixos. Então, vale a pena usar o Nvidia Chat com RTX?
A resposta é sim! Vale a pena usar o bate-papo com RTX, apesar da concorrência.
Um dos maiores pontos de venda do uso do Nvidia Chat com RTX é a capacidade de usar RAG sem enviar seus arquivos para um servidor de terceiros. A personalização de GPTs por meio de serviços online pode expor seus dados. Mas como o Chat with RTX é executado localmente e sem conexão com a Internet, usar o RAG no Chat with RTX garante que seus dados confidenciais estejam seguros e acessíveis apenas no seu PC.
Quanto a outros chatbots de IA executados localmente executando Mistral 7B, o Chat com RTX tem desempenho melhor e mais rápido. Embora grande parte do aumento de desempenho venha do uso de GPUs de última geração, o uso da Nvidia TensorRT-LLM e aceleração RTX tornou a execução do Mistral 7B mais rápida no Chat com RTX em comparação com outras formas de executar um LLM otimizado para chat.
É importante notar que a versão Chat with RTX que estamos usando atualmente é uma demonstração. Versões posteriores do Chat com RTX provavelmente se tornarão mais otimizadas e proporcionarão aumentos de desempenho.
E se eu não tiver uma GPU RTX série 30 ou 40?
O bate-papo com RTX é uma maneira fácil, rápida e segura de executar um LLM localmente, sem a necessidade de uma conexão com a Internet. Se você também estiver interessado em executar um LLM ou local, mas não tiver uma GPU RTX Série 30 ou 40, poderá tentar outras maneiras de executar um LLM localmente. Dois dos mais populares seriam GPT4ALL e Text Gen WebUI. Experimente GPT4ALL se desejar uma experiência plug-and-play executando localmente um LLM. Mas se você tiver um pouco mais de inclinação técnica, executar LLMs por meio do Text Gen WebUI fornecerá melhor ajuste fino e flexibilidade.
-
 Algoritmos de inteligência de enxames: três implementações do PythonImagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...IA Postado em 2025-03-24
Algoritmos de inteligência de enxames: três implementações do PythonImagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...IA Postado em 2025-03-24 -
Como tornar seu LLM mais preciso com pano e ajuste finoImagine studying a module at university for a semester. At the end, after an intensive learning phase, you take an exam – and you can recall th...IA Postado em 2025-03-24
-
O que é o Google Gemini? Tudo o que você precisa saber sobre o rival ChatGPT do GoogleGoogle recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members ...IA Postado em 2025-03-23
-
Guia sobre solicitação com DSPYdspy: uma estrutura declarativa para a construção e melhoria de aplicativos LLM DSPY (programas de idiomas auto-improvantes declarativos) revolucio...IA Postado em 2025-03-22
-
Automatize o blog para o tópico do TwitterEste artigo detalha automatização da conversão de conteúdo de formato longo (como postagens de blog) em tópicos envolventes no Twitter usando o gemin...IA Postado em 2025-03-11
-
Sistema imunológico artificial (AIS): um guia com exemplos de pythonEste artigo explora sistemas imunológicos artificiais (AIS), modelos computacionais inspirados na notável capacidade do sistema imunológico humano de...IA Postado em 2025-03-04
-
Tente fazer ao ChatGPT estas perguntas divertidas sobre vocêJá se perguntou o que o ChatGPT sabe sobre você? Como ele processa as informações que você forneceu ao longo do tempo? Eu usei montes de ChatGPT em di...IA Publicado em 2024-11-22
-
Veja como você ainda pode experimentar o misterioso chatbot GPT-2Se você gosta de modelos de IA ou chatbots, talvez já tenha visto discussões sobre o misterioso chatbot GPT-2 e sua eficácia.Aqui, explicamos o que é ...IA Publicado em 2024-11-08
-
O modo Canvas do ChatGPT é ótimo: estas são 4 maneiras de usá-loO novo modo Canvas do ChatGPT adicionou uma dimensão extra à escrita e edição na ferramenta de IA generativa líder mundial. Tenho usado o ChatGPT Canv...IA Publicado em 2024-11-08
-
Como os GPTs personalizados do ChatGPT podem expor seus dados e como mantê-los segurosO recurso GPT personalizado do ChatGPT permite que qualquer pessoa crie uma ferramenta de IA personalizada para quase tudo que você possa imaginar; G...IA Publicado em 2024-11-08
-
10 maneiras pelas quais o ChatGPT pode ajudá-lo a conseguir um emprego no LinkedInCom 2.600 caracteres disponíveis, a seção Sobre do seu perfil do LinkedIn é um ótimo espaço para falar sobre sua experiência, habilidades, paixões e ...IA Publicado em 2024-11-08
-
Confira estes 6 aplicativos de IA menos conhecidos que oferecem experiências únicasNeste ponto, a maioria das pessoas já ouviu falar do ChatGPT e do Copilot, dois aplicativos pioneiros de IA generativa que lideraram o boom da IA.Mas ...IA Publicado em 2024-11-08
-
Estes 7 sinais mostram que já atingimos o pico da IAOnde quer que você olhe on-line, há sites, serviços e aplicativos que proclamam que o uso da IA a torna a melhor opção. Não sei sobre você, mas sua ...IA Publicado em 2024-11-08
-
4 ferramentas de detecção de ChatGPT de verificação de IA para professores, palestrantes e chefesÀ medida que o ChatGPT avança em poder, fica cada vez mais difícil dizer o que é escrito por um ser humano e o que é gerado por uma IA. Isso torna di...IA Publicado em 2024-11-08
-
O recurso avançado de voz do ChatGPT está sendo lançado para mais usuáriosSe você sempre quis ter uma conversa completa com o ChatGPT, agora você pode. Isto é, desde que você pague pelo privilégio de usar o ChatGPT. Mais usu...IA Publicado em 2024-11-08















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









