 Primeira página > Programação > K Regressão dos Vizinhos Mais Próximos, Regressão: Aprendizado de Máquina Supervisionado
Primeira página > Programação > K Regressão dos Vizinhos Mais Próximos, Regressão: Aprendizado de Máquina Supervisionado
K Regressão dos Vizinhos Mais Próximos, Regressão: Aprendizado de Máquina Supervisionado
 Navegar:376
Navegar:376
k-Regressão dos vizinhos mais próximos
A regressãok-Nearest Neighbours (k-NN) é um método não paramétrico que prevê o valor de saída com base na média (ou média ponderada) dos k-pontos de dados de treinamento mais próximos no espaço de recursos. Essa abordagem pode modelar efetivamente relacionamentos complexos em dados sem assumir uma forma funcional específica.
O método de regressão k-NN pode ser resumido da seguinte forma:
- Métrica de distância: O algoritmo usa uma métrica de distância (geralmente distância euclidiana) para determinar a "proximidade" dos pontos de dados.
- k Vizinhos: O parâmetro k especifica quantos vizinhos mais próximos devem ser considerados ao fazer previsões.
- Predição: O valor previsto para um novo ponto de dados é a média dos valores de seus k vizinhos mais próximos.
Conceitos-chave
Não paramétrico: Ao contrário dos modelos paramétricos, k-NN não assume uma forma específica para o relacionamento subjacente entre os recursos de entrada e a variável de destino. Isso o torna flexível na captura de padrões complexos.
Cálculo de distância: A escolha da métrica de distância pode afetar significativamente o desempenho do modelo. As métricas comuns incluem distâncias euclidianas, de Manhattan e de Minkowski.
Escolha de k: O número de vizinhos (k) pode ser escolhido com base na validação cruzada. Um k pequeno pode levar a um ajuste excessivo, enquanto um k grande pode suavizar demais a previsão, potencialmente um ajuste insuficiente.
Exemplo de regressão de k-vizinhos mais próximos
Este exemplo demonstra como usar a regressão k-NN com recursos polinomiais para modelar relacionamentos complexos enquanto aproveita a natureza não paramétrica de k-NN.
Exemplo de código Python
1. Importar bibliotecas
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import PolynomialFeatures from sklearn.neighbors import KNeighborsRegressor from sklearn.metrics import mean_squared_error, r2_score
Este bloco importa as bibliotecas necessárias para manipulação de dados, plotagem e aprendizado de máquina.
2. Gerar dados de amostra
np.random.seed(42) # For reproducibility X = np.linspace(0, 10, 100).reshape(-1, 1) y = 3 * X.ravel() np.sin(2 * X.ravel()) * 5 np.random.normal(0, 1, 100)
Este bloco gera dados de amostra representando uma relação com algum ruído, simulando variações de dados do mundo real.
3. Divida o conjunto de dados
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Este bloco divide o conjunto de dados em conjuntos de treinamento e teste para avaliação do modelo.
4. Criar recursos polinomiais
degree = 3 # Change this value for different polynomial degrees poly = PolynomialFeatures(degree=degree) X_poly_train = poly.fit_transform(X_train) X_poly_test = poly.transform(X_test)
Este bloco gera recursos polinomiais a partir dos conjuntos de dados de treinamento e teste, permitindo que o modelo capture relacionamentos não lineares.
5. Crie e treine o modelo de regressão k-NN
k = 5 # Number of neighbors knn_model = KNeighborsRegressor(n_neighbors=k) knn_model.fit(X_poly_train, y_train)
Este bloco inicializa o modelo de regressão k-NN e o treina usando os recursos polinomiais derivados do conjunto de dados de treinamento.
6. Faça previsões
y_pred = knn_model.predict(X_poly_test)
Este bloco usa o modelo treinado para fazer previsões no conjunto de teste.
7. Trace os resultados
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color='blue', alpha=0.5, label='Data Points')
X_grid = np.linspace(0, 10, 1000).reshape(-1, 1)
X_poly_grid = poly.transform(X_grid)
y_grid = knn_model.predict(X_poly_grid)
plt.plot(X_grid, y_grid, color='red', linewidth=2, label=f'k-NN Regression (k={k}, Degree {degree})')
plt.title(f'k-NN Regression (Polynomial Degree {degree})')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
Este bloco cria um gráfico de dispersão dos pontos de dados reais versus os valores previstos do modelo de regressão k-NN, visualizando a curva ajustada.
Saída com k = 1:
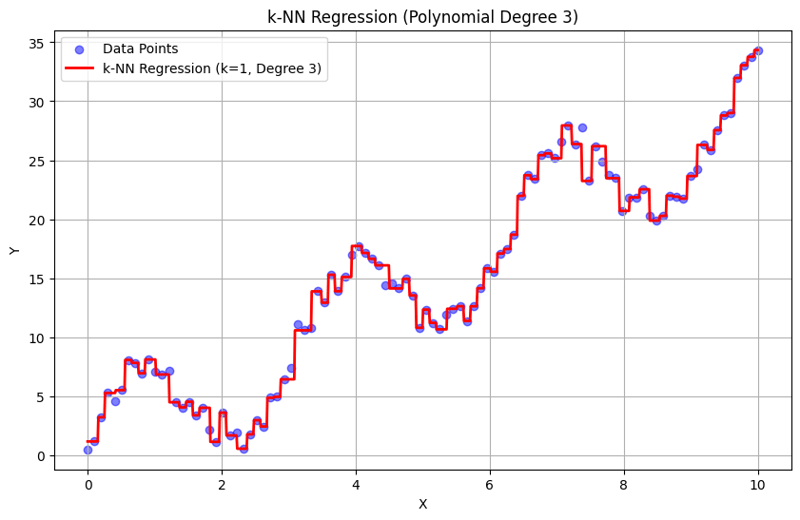
Saída com k = 10:
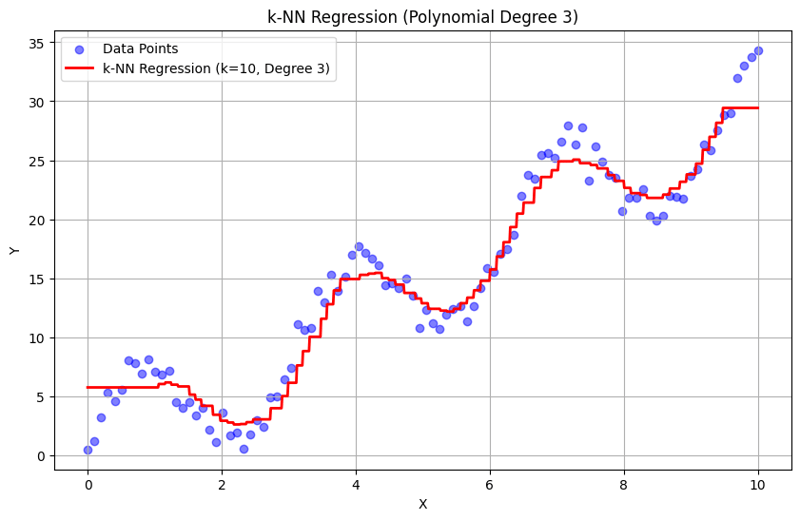
Esta abordagem estruturada demonstra como implementar e avaliar a regressão de k-vizinhos mais próximos com recursos polinomiais. Ao capturar padrões locais por meio da média das respostas de vizinhos próximos, a regressão k-NN modela efetivamente relacionamentos complexos em dados, ao mesmo tempo que fornece uma implementação direta. A escolha do k e do grau polinomial influencia significativamente o desempenho e a flexibilidade do modelo na captura de tendências subjacentes.
-
 Como corrigir \ "mysql_config não encontrou um erro \" ao instalar o mysql-python no ubuntu/linux?MySQL-Python Erro de instalação: "mysql_config não encontrado" tentando um erro indicador que "sQl-python na caixa ubuntu/linux...Programação Postado em 2025-07-05
Como corrigir \ "mysql_config não encontrou um erro \" ao instalar o mysql-python no ubuntu/linux?MySQL-Python Erro de instalação: "mysql_config não encontrado" tentando um erro indicador que "sQl-python na caixa ubuntu/linux...Programação Postado em 2025-07-05 -
O método do banco de dados MySQL não é necessário para despejar a mesma instânciacopiando um banco de dados MySQL na mesma instância sem despejar copiar um banco de dados na mesma instância MySQL pode ser feita sem ter que ...Programação Postado em 2025-07-05
-
Por que a execução do JavaScript cessa ao usar o botão Back Firefox?Problema do histórico de navegação: JavaScript deixa de executar após o uso do botão de volta ao Firefox usuários do Firefox podem encontrar u...Programação Postado em 2025-07-05
-
Qual método é mais eficiente para a detecção de ponto em polígono: rastreamento de raio ou path.contains_points?detecção de ponto-em-polígono eficiente em python determinar se um ponto está dentro de um polígono é uma tarefa frequente na geometria computac...Programação Postado em 2025-07-05
-
Como mesclar colunas de ano e quarto em uma coluna periódica em pandas?colunas concatenas para uma nova coluna de período Declaração de problemas: considera um panda dataframe com colunas denominadas "ano...Programação Postado em 2025-07-05
-
O CSS pode localizar elementos HTML com base em qualquer valor de atributo?direcionando elementos html com qualquer valor de atributo no css em css, é possível alvo elementos baseados em atributos específicos, conform...Programação Postado em 2025-07-05
-
Como posso lidar com os nomes de arquivos UTF-8 nas funções do sistema de arquivos do PHP?lidando com utf-8 nomes de arquivos nas funções do sistema de arquivos do PHP Ao criar pastas que contêm caracteres utf-8 usando a função mkdi...Programação Postado em 2025-07-05
-
Como evitar envios duplicados após a atualização do formulário?impedindo envios duplicados com atualização de manipulação no desenvolvimento da web, é comum encontrar a questão das submissões duplicadas qu...Programação Postado em 2025-07-05
-
Como verificar se um objeto tem um atributo específico no Python?Método para determinar o atributo de objeto Existence Esta consulta busca um método para verificar a presença de um atributo específico em um ...Programação Postado em 2025-07-05
-
Tags de formatação HTMLElementos de formatação HTML **HTML Formatting is a process of formatting text for better look and feel. HTML provides us ability to form...Programação Postado em 2025-07-05
-
Quando usar "tente" em vez de "se" para detectar valores variáveis no python?usando "Try" vs. "se" para testar o valor da variável no python no python, há situações em que você pode precisar verificar ...Programação Postado em 2025-07-05
-
Como criar variáveis dinâmicas no Python?Criação variável dinâmica em python A capacidade de criar variáveis dinamicamente pode ser uma ferramenta poderosa, especialmente ao trabalh...Programação Postado em 2025-07-05
-
Por que não `corpo {margem: 0; } `Sempre remova a margem superior no CSS?abordando a remoção da margem corporal em css para desenvolvedores da web iniciantes, remover a margem do elemento corporal pode ser uma taref...Programação Postado em 2025-07-05
-
Python Metaclass Working Princípio e Criação e Personalização de ClasseO que são metaclasses em python? metaclasses são responsáveis por criar objetos de classe em python. Assim como as aulas criam instâncias, as ...Programação Postado em 2025-07-05
-
Por que Java não pode criar matrizes genéricas?ERRO DE CRIAÇÃO DE MATOR DE ARRAY GENERÍCOLA Pergunta: quando se atende a criar um array de uma matriz genérica usando uma expressão como:...Programação Postado em 2025-07-05















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









