
GPT local com Ollama e Next.js
 Navegar:589
Navegar:589
Introdução
Com os avanços atuais de IA, é fácil configurar um modelo generativo de IA em seu computador para criar um chatbot.
Neste artigo veremos como você pode configurar um chatbot em seu sistema usando Ollama e Next.js
Configurar Ollama
Vamos começar configurando o Ollama em nosso sistema. Visite ollama.com e baixe-o para o seu sistema operacional. Isso nos permitirá usar o comando ollama no terminal/prompt de comando.
Verifique a versão do Ollama usando o comando ollama -v
Confira a lista de modelos na página da biblioteca Ollama.
Baixe e execute um modelo
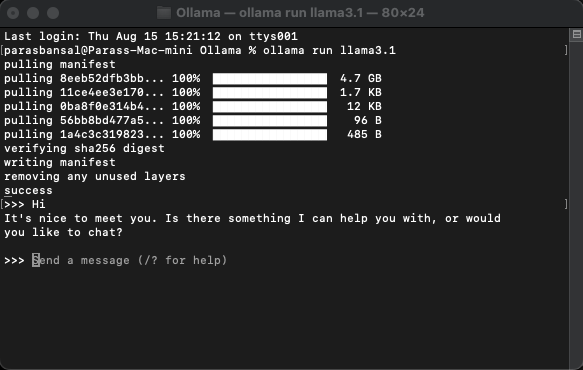
Para baixar e executar um modelo, execute o comando ollama run
Exemplo: ollama run llama3.1 ou ollama run gemma2
Você poderá conversar com a modelo diretamente no terminal.
Configurar aplicativo da web
Configuração básica para Next.js
- Baixe e instale a versão mais recente do Node.js
- Navegue até a pasta desejada e execute npx create-next-app@latest para gerar o projeto Next.js.
- Ele fará algumas perguntas para gerar código padrão. Para este tutorial, manteremos tudo padrão.
- Abra o projeto recém-criado no editor de código de sua preferência. Vamos usar o VS Code.
Instalando dependências
Existem alguns pacotes npm que precisam ser instalados para usar o ollama.
- ai de vercel.
- ollama A biblioteca JavaScript Ollama fornece a maneira mais fácil de integrar seu projeto JavaScript com Ollama.
- ollama-ai-provider ajuda a conectar ai e ollama.
- Os resultados do chat react-markdown serão formatados no estilo markdown. Para analisar o markdown, usaremos o pacote react-markdown.
Para instalar essas dependências, execute npm i ai ollama ollama-ai-provider.
Criar página de bate-papo
Em app/src há um arquivo chamado page.tsx.
Vamos remover tudo nele e começar com o componente funcional básico:
src/app/page.tsx
export default function Home() {
return (
{/* Code here... */}
);
}
Vamos começar importando o gancho useChat de ai/react e react-markdown
"use client";
import { useChat } from "ai/react";
import Markdown from "react-markdown";
Como estamos usando um gancho, precisamos converter esta página em um componente cliente.
Dica: você pode criar um componente separado para bate-papo e chamá-lo no page.tsx para limitar o uso do componente do cliente.
No componente, obtenha mensagens, entrada, handleInputChange e handleSubmit do gancho useChat.
const { messages, input, handleInputChange, handleSubmit } = useChat();
Em JSX, crie um formulário de entrada para obter a entrada do usuário para iniciar a conversa.
A boa ideia é que não precisamos corrigir o manipulador ou manter um estado para o valor de entrada, o gancho useChat nos fornece isso.
Podemos exibir as mensagens percorrendo o array de mensagens.
messages.map((m, i) => ({m})
A versão estilizada com base na função do remetente é semelhante a esta:
{messages.length ? ( messages.map((m, i) => { return m.role === "user" ? (You) : ({m.content} AI); }) ) : ({m.content} )}Local AI Chat
Vamos dar uma olhada no arquivo completo
src/app/page.tsx
"use client";
import { useChat } from "ai/react";
import Markdown from "react-markdown";
export default function Home() {
const { messages, input, handleInputChange, handleSubmit } = useChat();
return (
);
}
Com isso, a parte do frontend está completa. Agora vamos lidar com a API.
Manipulando API
Vamos começar criando route.ts dentro de app/api/chat.
Com base na convenção de nomenclatura Next.js, isso nos permitirá lidar com as solicitações no endpoint localhost:3000/api/chat.
src/app/api/chat/route.ts
import { createOllama } from "ollama-ai-provider";
import { streamText } from "ai";
const ollama = createOllama();
export async function POST(req: Request) {
const { messages } = await req.json();
const result = await streamText({
model: ollama("llama3.1"),
messages,
});
return result.toDataStreamResponse();
}
O código acima usa basicamente ollama e vercel ai para transmitir os dados de volta como resposta.
- createOllama cria uma instância do ollama que irá se comunicar com o modelo instalado no sistema.
- A função POST é o manipulador de rota no endpoint /api/chat com o método post.
- O corpo da solicitação contém a lista de todas as mensagens anteriores. Portanto, é uma boa ideia limitá-lo ou o desempenho diminuirá com o tempo. Neste exemplo, a função ollama toma "llama3.1" como modelo para gerar a resposta com base no array de mensagens.
IA generativa em seu sistema
Execute npm run dev para iniciar o servidor no modo de desenvolvimento.
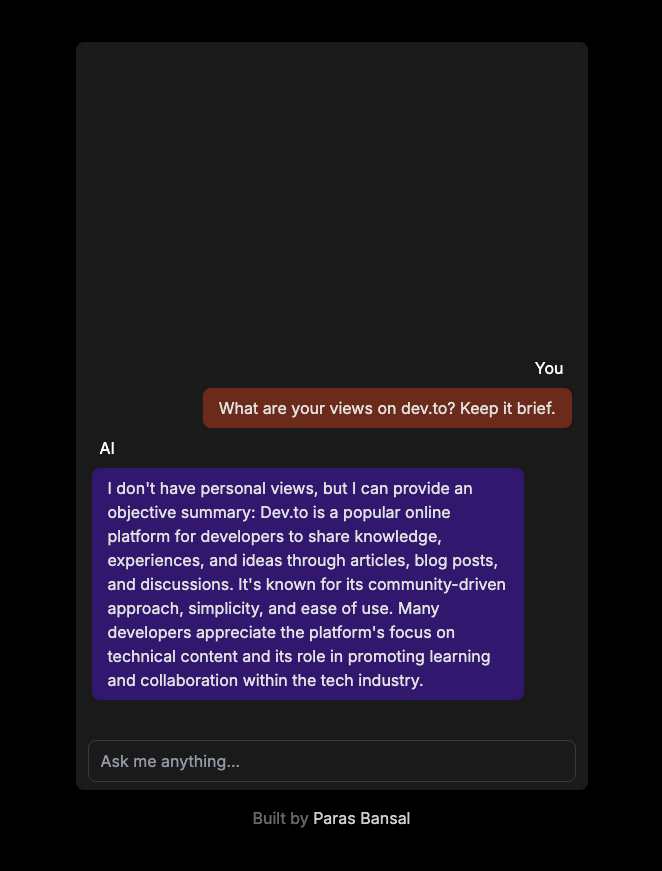
Abra o navegador e vá para localhost:3000 para ver os resultados.
Se tudo estiver configurado corretamente, você poderá conversar com seu próprio chatbot.
Você pode encontrar o código-fonte aqui: https://github.com/parasbansal/ai-chat
Deixe-me saber se você tiver alguma dúvida nos comentários, tentarei respondê-la.
-
 Como remover os manipuladores anônimos de eventos JavaScript de maneira limpa?removendo os ouvintes anônimos do evento adicionando ouvintes de eventos anônimos a elementos fornece flexibilidade e simplicidade, mas quando é...Programação Postado em 2025-02-19
Como remover os manipuladores anônimos de eventos JavaScript de maneira limpa?removendo os ouvintes anônimos do evento adicionando ouvintes de eventos anônimos a elementos fornece flexibilidade e simplicidade, mas quando é...Programação Postado em 2025-02-19 -
Como implementar o manuseio de exceção personalizado com o módulo de log do Python?manuseio de erros personalizado com o módulo de registro de Python garantindo que as exceções não sejadas sejam manipuladas adequadamente e o ...Programação Postado em 2025-02-19
-
Por que a execução do JavaScript cessa ao usar o botão Back Firefox?Problema do histórico de navegação: javascript deixa de executar depois de usar o botão de volta ao Firefox usuários do Firefox podem encontra...Programação Postado em 2025-02-19
-
Posso migrar minha criptografia de McRypt para OpenSSL e descriptografar dados criptografados por McRypt usando o OpenSSL?Atualizando minha biblioteca de criptografia de McRypt para OpenSSL posso atualizar minha biblioteca de criptografia de McHRPT para openssl? N...Programação Postado em 2025-02-19
-
Objetos-ajuste: a capa falha no IE e na borda, como consertar?object-fit: a capa falha no ie e borda, como corrigir? utilizando objeto-fit: cover; No CSS, para manter a altura consistente da imagem funcio...Programação Postado em 2025-02-19
-
Como definir dinamicamente as teclas em objetos JavaScript?como criar uma chave dinâmica para uma variável de objeto JavaScript ao tentar criar uma chave dinâmica para um objeto JavaScript, usando esta s...Programação Postado em 2025-02-19
-
Por que as funções de seta causam erros de sintaxe no IE11 e como posso corrigi -los?por que as funções da seta causam erros de sintaxe no ie 11 no código d3.js fornecido, o erro surge do uso das funções de seta . O IE 11 não s...Programação Postado em 2025-02-19
-
Como inserir corretamente Blobs (imagens) no MySQL usando PHP?Insira Blobs nos bancos de dados MySQL com PHP Ao tentar armazenar uma imagem no banco de dados A MySQL, você pode encontrar e encontrar e em...Programação Postado em 2025-02-19
-
Como verificar se um objeto tem um atributo específico no Python?Método para determinar o atributo de objeto Existence Esta consulta busca um método para verificar a presença de um atributo específico em um ...Programação Postado em 2025-02-19
-
Por que o Microsoft Visual C ++ falha ao implementar corretamente a instanciação do modelo bifásico?O mistério do modelo de duas fases "quebrado" bifásia instanciação no Microsoft Visual C Declaração de Problema: usuários comument...Programação Postado em 2025-02-19
-
Como posso controlar as vibrações do dispositivo Android com frequências variadas?controlando as vibrações do dispositivo Android com variações de frequência deseja adicionar um elemento tátil ao seu aplicativo Android? Compre...Programação Postado em 2025-02-19
-
Como posso substituir com eficiência várias substringas em uma string java?] Recorra à abordagem de força bruta de aplicar repetidamente o método string.replace (). No entanto, isso pode ser ineficiente para seqüências grande...Programação Postado em 2025-02-19
-
Como limitar o intervalo de rolagem de um elemento dentro de um elemento pai de tamanho dinâmico?implementando limites de altura CSS para elementos de rolagem vertical em uma interface interativa, o controle do comportamento de rolagem dos...Programação Postado em 2025-02-19
-
Como você pode usar o Grupo By to Pivot Data in MySQL?girando resultados de consulta usando o grupo mysql por em um banco de dados relacional, girando dados se referindo ao rearranjo de linhas e c...Programação Postado em 2025-02-19
-
Como posso verificar com segurança a existência da coluna em uma tabela MySQL?] Outros sistemas de banco de dados. O método comumente tentado: se existe (selecione * de informação_schema.columns Onde tabela_name = ...Programação Postado em 2025-02-19















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









