
Programa Java para remover duplicatas de uma determinada pilha
 Navegar:235
Navegar:235
Neste artigo, exploraremos dois métodos para remover elementos duplicados de uma pilha em Java. Compararemos uma abordagem direta com loops aninhados e um método mais eficiente usando um HashSet. O objetivo é demonstrar como otimizar a remoção de duplicatas e avaliar o desempenho de cada abordagem.
Declaração do problema
Escreva um programa Java para remover o elemento duplicado da pilha.
Entrada
Stackdata = initData(10L);
Saída
Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Naive Approach: 18200 nanoseconds Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Optimized Approach: 34800 nanoseconds
Para remover duplicatas de uma determinada pilha, temos 2 abordagens -
- Abordagem ingênua: crie dois loops aninhados para ver quais elementos já estão presentes e evitar adicioná-los ao retorno da pilha de resultados.
- Abordagem HashSet: Use um Set para armazenar elementos únicos e aproveite sua O(1) complexidade para verificar se um elemento está presente ou não.
Gerando e clonando pilhas aleatórias
Abaixo está o programa Java que primeiro constrói uma pilha aleatória e, em seguida, cria uma duplicata dela para uso posterior -
private static Stack initData(Long size) {
Stack stack = new Stack ();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i manualCloneStack(Stack stack) {
Stack newStack = new Stack ();
for (Integer item: stack) {
newStack.push(item);
}
return newStack;
}
initData ajuda a criar uma pilha com um tamanho especificado e elementos aleatórios variando de 1 a 100.
manualCloneStack ajuda a gerar dados copiando dados de outra pilha, usando-os para comparação de desempenho entre as duas ideias.
Remover duplicatas de uma determinada pilha usando a abordagem Naïve
A seguir estão as etapas para remover duplicatas de uma determinada pilha usando a abordagem Naïve -
- Inicie o cronômetro.
- Crie uma pilha vazia para armazenar elementos exclusivos.
- Itere usando o loop while e continue até que a pilha original esteja vazia, pop o elemento superior.
- Verifique se há duplicatas usando resultStack.contains(element) para ver se o elemento já está na pilha de resultados.
- Se o elemento não estiver na pilha de resultados, adicione-o ao resultStack.
- Registre o horário de término e calcule o tempo total gasto.
- Retornar resultado
Exemplo
Abaixo está o programa Java para remover duplicatas de uma determinada pilha usando a abordagem Naïve -
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack ();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.println("Time spent for idea1 is %d nanosecond".formatted(System.nanoTime() - start));
return resultStack;
}
Para abordagem ingênua, usamos
while (!stack.isEmpty())
resultStack.contains(element)
para verificar se o elemento já está presente.Remova duplicatas de uma determinada pilha usando abordagem otimizada (HashSet)
A seguir estão as etapas para remover duplicatas de uma determinada pilha usando uma abordagem otimizada -
- Iniciar o cronômetro
- Crie um conjunto para rastrear elementos vistos (para verificações de complexidade O(1)).
- Crie uma pilha temporária para armazenar elementos exclusivos.
- Itere usando o while loop continue até que a pilha esteja vazia.
- Remova o elemento superior da pilha.
- Para verificar as duplicatas usaremos seen.contains(element) para verificar se o elemento já está no conjunto.
- Se o elemento não estiver no conjunto, adicione-o à pilha vista e à pilha temporária.
- Registre o horário de término e calcule o tempo total gasto.
- Retorna o resultado
Exemplo
Abaixo está o programa Java para remover duplicatas de uma determinada pilha usando HashSet −
public static Stackidea2(Stack stack) { long start = System.nanoTime(); Set seen = new HashSet(); Stack tempStack = new Stack(); while (!stack.isEmpty()) { int element = stack.pop(); if (!seen.contains(element)) { seen.add(element); tempStack.push(element); } } System.out.println("Time spent for idea2 is %d nanosecond".formatted(System.nanoTime() - start)); return tempStack; }
Para uma abordagem otimizada, usamos
Set seen Usando as duas abordagens juntas
Abaixo estão as etapas para remover duplicatas de uma determinada pilha usando as duas abordagens mencionadas acima -
- Para inicializar os dados, estamos usando o método initData(Long size) para criar uma pilha preenchida com números inteiros aleatórios.
- Clonar a pilha estamos usando o método cloneStack(Stack stack) para criar uma cópia exata da pilha original.
- Gere a pilha inicial com initData.
- Clone esta pilha usando cloneStack.
- Aplique a abordagem ingênua para remover duplicatas da pilha original.
- Aplique a abordagem otimizada para remover duplicatas da pilha clonada.
- Exiba o tempo necessário para cada método e os elementos exclusivos produzidos por ambas as abordagens
Exemplo
Abaixo está o programa Java que remove elementos duplicados de uma pilha usando as duas abordagens mencionadas acima -
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.Stack;
public class DuplicateStackElements {
private static Stack initData(Long size) {
Stack stack = new Stack();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i cloneStack(Stack stack) {
Stack newStack = new Stack();
newStack.addAll(stack);
return newStack;
}
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.printf("Time spent for idea1 is %d nanoseconds%n", System.nanoTime() - start);
return resultStack;
}
public static Stack idea2(Stack stack) {
long start = System.nanoTime();
Set seen = new HashSet();
Stack tempStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.printf("Time spent for idea2 is %d nanoseconds%n", System.nanoTime() - start);
return tempStack;
}
public static void main(String[] args) {
Stack data1 = initData(10L);
Stack data2 = cloneStack(data1);
System.out.println("Unique elements using idea1: " idea1(data1));
System.out.println("Unique elements using idea2: " idea2(data2));
}
}
Saída
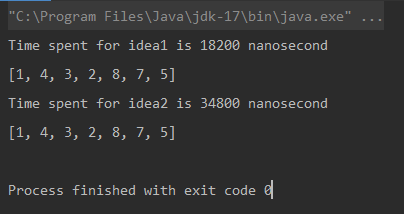
Comparação
* A unidade de medida é nanossegundo.
public static void main(String[] args) {
Stack data1 = initData();
Stack data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}
| Método | 100 elementos | 1000 elementos | 10.000 elementos |
100.000 elementos |
1000000 elementos |
| Ideia 1 | 693100 |
4051600 |
19026900 |
114201800 |
1157256000 |
| Ideia 2 | 135800 |
681400 |
2717800 |
11489400 |
36456100 |
Conforme observado, o tempo de execução da Ideia 2 é menor do que o da Ideia 1 porque a complexidade da Ideia 1 é O(n²), enquanto a complexidade da Ideia 2 é O(n). Assim, quando o número de pilhas aumenta, o tempo gasto em cálculos também aumenta com base nisso.
-
 jQuery recebe o valor do grupo de botões de rádioEste artigo fornece trechos e respostas concisos de código jQuery e perguntas frequentes (perguntas frequentes) sobre manipular grupos de botões d...Programação Postado em 2025-04-18
jQuery recebe o valor do grupo de botões de rádioEste artigo fornece trechos e respostas concisos de código jQuery e perguntas frequentes (perguntas frequentes) sobre manipular grupos de botões d...Programação Postado em 2025-04-18 -
Como posso substituir com eficiência várias substringas em uma string java?substituindo várias substâncias em uma string com eficiência em java quando confrontado com a necessidade de substituir várias substringas den...Programação Postado em 2025-04-18
-
Por que o DateTime :: Modify do PHP ('+1 mês') produz resultados inesperados?Modificando meses com php dateTime: descobrindo o comportamento pretendido Ao trabalhar com a classe DateTime do PHP, adicionar ou subtrair me...Programação Postado em 2025-04-18
-
Como verificar se um objeto tem um atributo específico no Python?Método para determinar o atributo de objeto Existence Esta consulta busca um método para verificar a presença de um atributo específico em um ...Programação Postado em 2025-04-18
-
Como exibir corretamente a data e a hora atuais em formato "dd/mm/yyyy hh: mm: ss.ss" em java?como exibir a data e a hora atuais em "dd/mm/yyyy hh: mm: ss.ss" formato no código java fornecido, o problema com a exibição da data...Programação Postado em 2025-04-18
-
Como posso personalizar otimizações de compilação no compilador Go?personalizando otimizações de compilação no Go Compiler O processo de compilação padrão em Go segue uma estratégia de otimização específica. N...Programação Postado em 2025-04-18
-
Por que o Microsoft Visual C ++ falha ao implementar corretamente a instanciação do modelo bifásico?O mistério do modelo de duas fases "quebrado" bifásia instanciação no Microsoft Visual C Declaração de Problema: STRAGLES Expressa...Programação Postado em 2025-04-18
-
Guia de criação de páginas de 404 de 404 da FASTAPIPágina 404 personalizada não encontrada com fastapi para criar uma página 404 personalizada não encontrada, o FASTAPI oferece várias abordagen...Programação Postado em 2025-04-18
-
Como resolver o erro \ "Uso inválido da função do grupo \" no MySQL ao encontrar a contagem máxima?como recuperar a contagem máxima usando o mysql em mysql, você pode encontrar um problema enquanto tenta encontrar a contagem máxima de valore...Programação Postado em 2025-04-18
-
Use MySqli para obter um método unidimensional da coluna únicaComo obtenho valores de coluna única como uma matriz unidimensional usando o mysqli? Em vez da matriz unidimensional desejada, você recebe uma ma...Programação Postado em 2025-04-18
-
VariedadeOs métodos são FNs que podem ser chamados em objetos Matrizes são objetos, portanto, eles também têm métodos no JS. Flice (Begin): Extra...Programação Postado em 2025-04-18
-
Como remover emojis das cordas em Python: um guia para iniciantes para corrigir erros comuns?removendo emojis de strings em python o código Python fornecido para remover emojis falha porque contém syntaxe erros. As cadeias de unicode d...Programação Postado em 2025-04-18
-
Quais são os padrões de design para a promessa assíncrona repetir?Designando padrões para PROMEDAS EXECTRESS Na programação assíncrona, geralmente é útil para repetir as promessas fracassadas até que resolvam...Programação Postado em 2025-04-18
-
Como posso ler com eficiência um arquivo grande em ordem inversa usando o Python?lendo um arquivo em ordem inversa em python se você estiver trabalhando com um arquivo grande e precisar ler seu conteúdo da última linha para...Programação Postado em 2025-04-18
-
Como analisar números na notação exponencial usando decimal.parse ()?analisando um número da notação exponencial ao tentar analisar uma string expressa em anotação exponencial usando Decimal.parse ("1.2345e...Programação Postado em 2025-04-18















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









