 Primeira página > Programação > Extraindo dados de PDFs complicados com o Google Gemini em linhas de Python
Primeira página > Programação > Extraindo dados de PDFs complicados com o Google Gemini em linhas de Python
Extraindo dados de PDFs complicados com o Google Gemini em linhas de Python
 Navegar:618
Navegar:618
Neste guia, mostrarei como extrair dados estruturados de PDFs usando modelos de linguagem de visão (VLMs) como Gemini Flash ou GPT-4o.
Gemini, a mais recente série de modelos de linguagem de visão do Google, mostrou desempenho de última geração na compreensão de texto e imagem. Essa capacidade multimodal aprimorada e a longa janela de contexto o tornam particularmente útil para processar dados PDF visualmente complexos com os quais os modelos de extração tradicionais têm dificuldade, como figuras, gráficos, tabelas e diagramas.
Ao fazer isso, você pode criar facilmente sua própria ferramenta de extração de dados para extração visual de arquivos e web. Veja como:
A longa janela de contexto e a capacidade multimodal do Gemini o tornam particularmente útil para processar dados PDF visualmente complexos onde os modelos de extração tradicionais têm dificuldades.
Configurando seu ambiente
Antes de mergulharmos na extração, vamos configurar nosso ambiente de desenvolvimento. Este guia pressupõe que você tenha o Python instalado em seu sistema. Caso contrário, baixe e instale-o em https://www.python.org/downloads/
⚠️ Observe que, se não quiser usar Python, você pode usar a plataforma em nuvem em thepi.pe para fazer upload de seus arquivos e baixar seu resultado como um CSV sem escrever nenhum código.
Instale as bibliotecas necessárias
Abra seu terminal ou prompt de comando e execute os seguintes comandos:
pip install git https://github.com/emcf/thepipe pip install pandas
Para aqueles que são novos em Python, pip é o instalador de pacotes para Python, e esses comandos irão baixar e instalar as bibliotecas necessárias.
Configure sua chave de API
Para usar opipe, você precisa de uma chave de API.
Isenção de responsabilidade: embora thepi.pe seja uma ferramenta gratuita e de código aberto, a API tem um custo de aproximadamente US$ 0,00002 por token. Se você quiser evitar esses custos, verifique as instruções de configuração local no GitHub. Observe que você ainda terá que pagar ao provedor de LLM de sua escolha.
Veja como obter e configurar:
- Visite https://thepi.pe/platform/
- Crie uma conta ou faça login
- Encontre sua chave de API na página de configurações

Agora, você precisa definir isso como uma variável de ambiente. O processo varia dependendo do seu sistema operacional:
- Copie a chave API do menu de configurações na plataformapi.pe
Para Windows:
- Pesquise por "Variáveis de Ambiente" no menu Iniciar
- Clique em "Editar as variáveis de ambiente do sistema"
- Clique no botão "Variáveis de ambiente"
- Em "Variáveis de usuário", clique em "Novo"
- Defina o nome da variável como THEPIPE_API_KEY e o valor como sua chave de API
- Clique em "OK" para salvar
Para macOS e Linux:
Abra seu terminal e adicione esta linha ao seu arquivo de configuração do shell (por exemplo, ~/.bashrc ou ~/.zshrc):
export THEPIPE_API_KEY=your_api_key_here
Em seguida, recarregue sua configuração:
source ~/.bashrc # or ~/.zshrc
Definindo seu esquema de extração
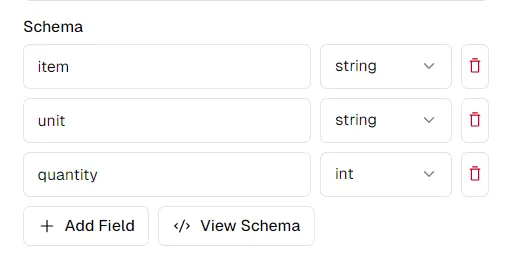
A chave para uma extração bem-sucedida é definir um esquema claro para os dados que você deseja extrair. Digamos que estamos extraindo dados de um documento de lista de quantidades:

Um exemplo de página do documento Lista de Quantidades. Os dados de cada página são independentes das demais páginas, por isso fazemos nossa extração “por página”. Existem vários dados para extrair por página, por isso definimos várias extrações como True
Olhando para os nomes das colunas, podemos querer extrair um esquema como este:
schema = {
"item": "string",
"unit": "string",
"quantity": "int",
}
Você pode modificar o esquema ao seu gosto na plataformapi.pe. Clicar em "Visualizar esquema" fornecerá um esquema que você pode copiar e colar para usar com a API Python
Extraindo dados de PDFs
Agora, vamos usar extract_from_file para extrair dados de um PDF:
from thepipe.extract import extract_from_file results = extract_from_file( file_path = "bill_of_quantity.pdf", schema = schema, ai_model = "google/gemini-flash-1.5b", chunking_method = "chunk_by_page" )
Aqui temos chunking_method="chunk_by_page" porque queremos enviar cada página para o modelo de IA individualmente (o PDF é muito grande para ser alimentado de uma só vez). Também definimos multiple_extractions=True porque cada página PDF contém várias linhas de dados. Esta é a aparência de uma página do PDF:
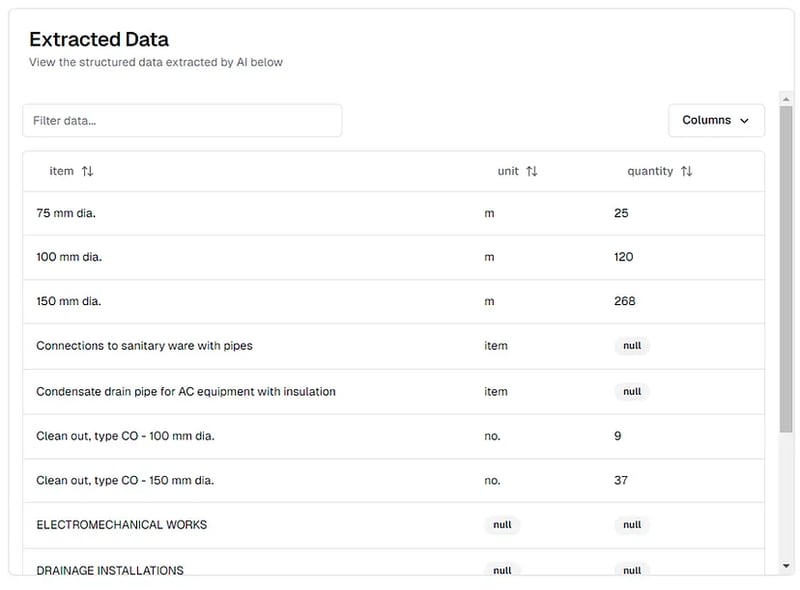
Os resultados da extração do PDF da lista de quantidades conforme visualizado na plataforma pi.pe
Processando os resultados
Os resultados da extração são retornados como uma lista de dicionários. Podemos processar esses resultados para criar um DataFrame do pandas:
import pandas as pd df = pd.DataFrame(results) # Display the first few rows of the DataFrame print(df.head())
Isso cria um DataFrame com todas as informações extraídas, incluindo conteúdo textual e descrições de elementos visuais como figuras e tabelas.
Exportando para diferentes formatos
Agora que temos nossos dados em um DataFrame, podemos exportá-los facilmente para vários formatos. Aqui estão algumas opções:
Exportando para Excel
df.to_excel("extracted_research_data.xlsx", index=False, sheet_name="Research Data")
Isso cria um arquivo Excel chamado "extracted_research_data.xlsx" com uma planilha chamada "Dados de pesquisa". O parâmetro index=False evita que o índice DataFrame seja incluído como uma coluna separada.
Exportando para CSV
Se preferir um formato mais simples, você pode exportar para CSV:
df.to_csv("extracted_research_data.csv", index=False)
Isso cria um arquivo CSV que pode ser aberto no Excel ou em qualquer editor de texto.
Notas finais
A chave para uma extração bem-sucedida está na definição de um esquema claro e na utilização dos recursos multimodais do modelo de IA. À medida que você se sentir mais confortável com essas técnicas, poderá explorar recursos mais avançados, como métodos de agrupamento personalizados, prompts de extração personalizados e integração do processo de extração em pipelines de dados maiores.
-
 Como lidar com a entrada do usuário no modo exclusivo de tela cheia da Java?manuseando a entrada do usuário no modo exclusivo da tela full em java introdução ao executar um aplicativo Java no modo exclusivo de tela c...Programação Postado em 2025-07-14
Como lidar com a entrada do usuário no modo exclusivo de tela cheia da Java?manuseando a entrada do usuário no modo exclusivo da tela full em java introdução ao executar um aplicativo Java no modo exclusivo de tela c...Programação Postado em 2025-07-14 -
Como lidar com a memória fatiada na coleção de lixo de idiomas Go?coleta de lixo em go slies: uma análise detalhada em go, uma fatia é uma matriz dinâmica que faz referência a uma matriz subjacente. Ao trabal...Programação Postado em 2025-07-14
-
Como posso personalizar otimizações de compilação no compilador Go?personalizando otimizações de compilação no Go Compiler O processo de compilação padrão em Go segue uma estratégia de otimização específica. N...Programação Postado em 2025-07-14
-
Quais foram as restrições ao usar o current_timestamp com colunas de registro de data e hora em MySQL antes da versão 5.6.5?restrições em colunas de timestamp com current_timestamp no padrão ou na atualização de cláusulas nas versões MySQL antes de 5.6.5 historicament...Programação Postado em 2025-07-14
-
Por que o Firefox exibe imagens usando a propriedade CSS `Content`?exibindo imagens com URL de conteúdo em Firefox Um problema foi encontrado onde certos navegadores, especificamente Firefox, falham em exibir ...Programação Postado em 2025-07-14
-
Como posso concatenar com segurança o texto e os valores ao construir consultas SQL em Go?concatenando texto e valores em go sql Queries Ao construir uma consulta SQL texth e, em codificação, e a signa e a consulta de syntax e a sín...Programação Postado em 2025-07-14
-
Como corrigir “Erro geral: o servidor MySQL 2006 desapareceu” ao inserir dados?Como resolver "Erro geral: o servidor MySQL de 2006 desapareceu" ao inserir registrosIntrodução:A inserção de dados em um banco de dados MyS...Programação Postado em 2025-07-14
-
Tarefa assíncroada vs. assíncrona em asp.net: Por que o método assíncrono void às vezes joga exceções?Entendendo a distinção entre a tarefa assíncrona e async em asp.net em ASP.NET APLICAÇÕES, ASYNCHRONOUS PROGRATIONS APRESENCIA UM REMAÇÃO CRUC...Programação Postado em 2025-07-14
-
Por que as imagens ainda têm fronteiras no Chrome? `Border: Nenhum;` Solução inválidaremovendo a borda da imagem em Chrome Uma questão frequente encontrada ao trabalhar com imagens em Chrome e IE9 é a aparência de uma borda fin...Programação Postado em 2025-07-14
-
Como fazer upload de arquivos com parâmetros adicionais usando java.net.urlConnection e codificação multipartida/formulário?carregando arquivos com http requests para fazer upload de arquivos para um servidor http e também enviando parâmetros adicionais, java.net.ur...Programação Postado em 2025-07-14
-
Guia para resolver problemas de CORS no Spring Security 4.1 e acimaSpring Security cors filter: solucionando problemas comuns Ao integrar a segurança da primavera em um projeto existente, você pode encontrar e...Programação Postado em 2025-07-14
-
VariedadeOs métodos são FNs que podem ser chamados em objetos Matrizes são objetos, portanto, eles também têm métodos no JS. Flice (Begin): Extra...Programação Postado em 2025-07-14
-
Como inserir com eficiência dados em várias tabelas MySQL em uma transação?mysql Inserir em múltiplas tabelas tentando inserir dados em várias tabelas com uma única consulta MySQL pode produzir resultados inesperados....Programação Postado em 2025-07-14
-
Objetos-ajuste: a capa falha no IE e na borda, como consertar?object-fit: a capa falha no ie e borda, como corrigir? utilizando objeto-fit: cover; No CSS, para manter a altura consistente da imagem funcio...Programação Postado em 2025-07-14
-
Preciso excluir explicitamente as alocações de heap em C ++ antes da saída do programa?exclusão explícita em c, apesar do programa exit ao trabalhar com a alocação de memória dinâmica em C, os desenvolvedores geralmente se pergun...Programação Postado em 2025-07-14















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









