
Avaliando um modelo de classificação de aprendizado de máquina
 Navegar:556
Navegar:556
Contorno
- Qual é o objetivo da avaliação do modelo?
- Qual é o propósito da avaliação do modelo e quais são alguns procedimentos de avaliação comuns?
- Qual é o uso da precisão da classificação e quais são seus limitações?
- Como uma matriz de confusão descreve o desempenho de um classificador?
- Quais métricas podem ser calculadas a partir de uma matriz de confusão?
To objetivo da avaliação do modelo é responder à pergunta;
como faço para escolher entre diferentes modelos?
O processo de avaliação de um aprendizado de máquina ajuda a determinar quão confiável e eficaz o modelo é para sua aplicação. Isso envolve a avaliação de diversos fatores, como desempenho, métricas e precisão para previsões ou tomada de decisão.
Não importa qual modelo você escolha usar, você precisa escolher entre modelos: diferentes tipos de modelos, parâmetros de ajuste e recursos. Além disso, você precisa de um procedimento de avaliação de modelo para estimar quão bem um modelo será generalizado para dados invisíveis. Por último, você precisa de um procedimento de avaliação para emparelhar com o seu procedimento para quantificar o desempenho do seu modelo.
Antes de prosseguirmos, vamos revisar alguns dos diferentes procedimentos de avaliação de modelos e como eles funcionam.Procedimentos de avaliação de modelos e como eles funcionam.
- Treinamento e testes nos mesmos dados
- Recompensa modelos excessivamente complexos que "ajustam demais" os dados de treinamento e não necessariamente generalizam
- Divisão de treinamento/teste
- Divida o conjunto de dados em duas partes, para que o modelo possa ser treinado e testado em dados diferentes
- Melhor estimativa do desempenho fora da amostra, mas ainda uma estimativa de "alta variação"
- Útil devido à sua velocidade, simplicidade e flexibilidade
- Validação cruzada K-fold
- Crie sistematicamente divisões de treinamento/teste "K" e calcule a média dos resultados juntos
- Estimativa ainda melhor do desempenho fora da amostra
- Executa "K" vezes mais devagar do que a divisão de treinamento/teste.
- Treinar e testar nos mesmos dados é uma causa clássica de overfitting, no qual você constrói um modelo excessivamente complexo que não pode ser generalizado para novos dados e que não é realmente útil.
- Train_Test_Split fornece uma estimativa muito melhor do desempenho fora da amostra.
- A validação cruzada K-fold tem melhor desempenho ao treinar sistematicamente K divisões de teste e calcular a média dos resultados juntos.
Métricas de avaliação do modelo:
Você sempre precisará de uma métrica de avaliação para acompanhar o procedimento escolhido, e a escolha da métrica depende do problema que você está abordando. Para problemas de classificação, você pode usar a precisão da classificação. Mas vamos nos concentrar em outras métricas importantes de avaliação de classificação neste guia.
Antes de aprendermos qualquer nova métrica de avaliação' Vamos revisar a
precisão da classificação e falar sobre seus pontos fortes e fracos.
Precisão de classificaçãoEscolhemos o conjunto de dados Pima Indians Diabetes para este tutorial, que inclui dados de saúde e status de diabetes de 768 pacientes.
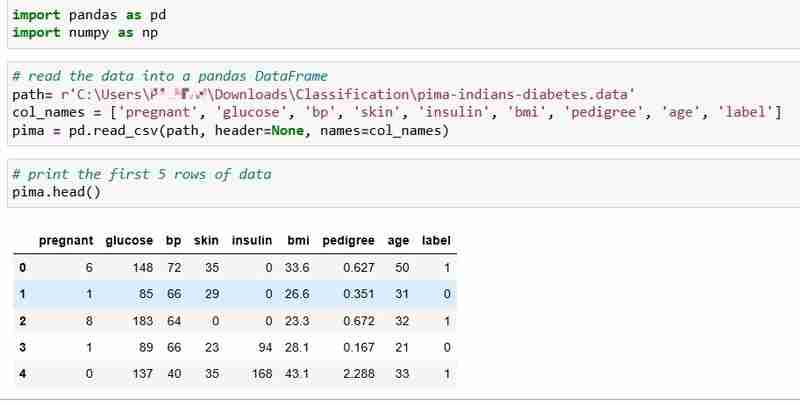
Pergunta: Podemos prever o status de diabetes de um paciente com base em suas medidas de saúde?
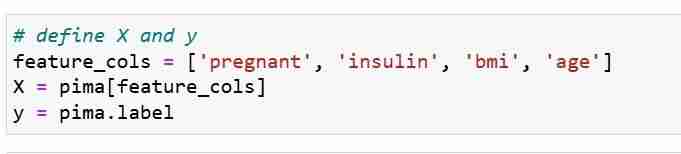
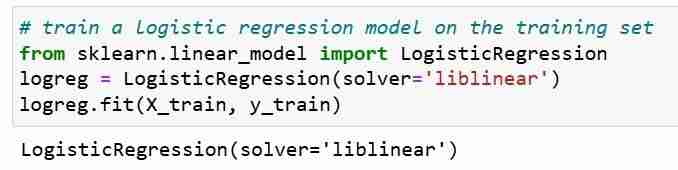
Definimos nossas métricas de recursos X e vetor de resposta Y. Usamos train_test_split para dividir X e Y em conjuntos de treinamento e teste.

Precisão nula, que é a precisão que pode ser alcançada prevendo sempre a classe mais frequente.

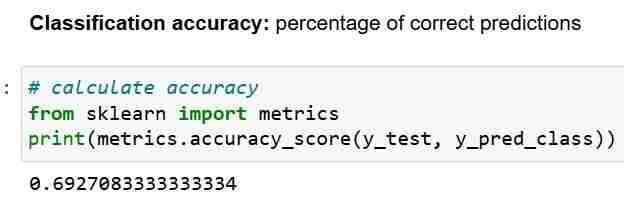
Precisão nula responde à pergunta; se meu modelo previsse a classe predominante 100% das vezes, com que frequência ele estaria correto? No cenário acima, 32% do y_test são 1 (unidades). Em outras palavras, um modelo burro que prevê que os pacientes têm diabetes estaria certo 68% das vezes (que são os zeros).Isso fornece uma linha de base contra a qual podemos querer medir nossa regressão logística modelo.
Quando comparamos a precisão nula de68% e a precisão do modelo de 69%, nosso modelo não parece muito bom. Isso demonstra uma fraqueza da precisão da classificação como métrica de avaliação do modelo. A precisão da classificação não nos diz nada sobre a distribuição subjacente do teste de teste.
Resumindo:
- A precisão da classificação é a
- métrica de classificação mais fácil de entender Mas, não informa a
- distribuição subjacente dos valores de resposta E não informa quais
- "tipos" de erros seu classificador está cometendo.
Matriz de confusão
A matriz de confusão é uma tabela que descreve o desempenho de um modelo de classificação.
É útil para ajudar você a entender o desempenho do seu classificador, mas não é uma métrica de avaliação do modelo; então você não pode dizer ao scikit para aprender a escolher o modelo com a melhor matriz de confusão. No entanto, existem muitas métricas que podem ser calculadas a partir da matriz de confusão e podem ser usadas diretamente para escolher entre modelos.
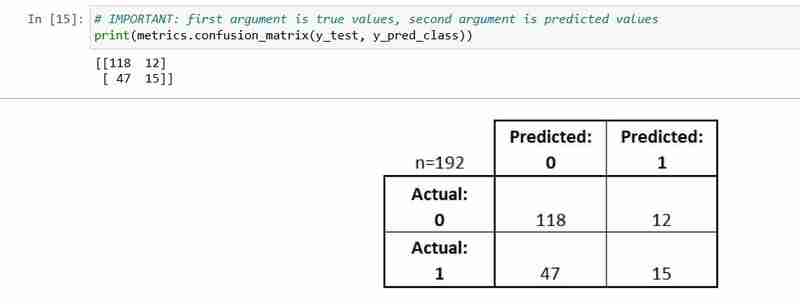
- Cada observação no conjunto de testes é representada em
- exatamente uma caixa É uma matriz 2x2 porque existem
- 2 classes de resposta O formato mostrado aqui
- não universal
- Verdadeiros Positivos (TP): nós previmos corretamente que eles têm diabetes
- Verdadeiros Negativos (TN): nós previmos corretamente que eles não têm diabetes
- Falsos Positivos (FP): nós incorretamente previmos que eles têm diabetes (um "erro Tipo I")
- Falsos negativos (FN): nós previmos incorretamente que eles não têm diabetes (um "erro tipo II")
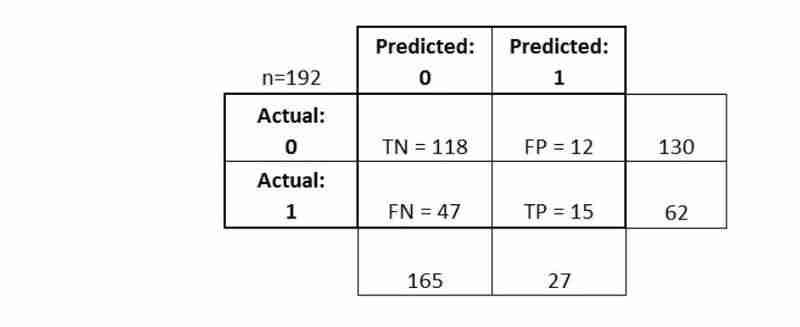


Para concluir:
- A matriz de confusão oferece uma
- imagem mais completa do desempenho do seu classificador Também permite calcular várias
- métricas de classificação, e essas métricas podem orientar sua seleção de modelo
-
 Como posso lidar com os nomes de arquivos UTF-8 nas funções do sistema de arquivos do PHP?lidando com utf-8 nomes de arquivos nas funções do sistema de arquivos do PHP Ao criar pastas que contêm caracteres utf-8 usando a função mkdi...Programação Postado em 2025-04-05
Como posso lidar com os nomes de arquivos UTF-8 nas funções do sistema de arquivos do PHP?lidando com utf-8 nomes de arquivos nas funções do sistema de arquivos do PHP Ao criar pastas que contêm caracteres utf-8 usando a função mkdi...Programação Postado em 2025-04-05 -
Como você pode definir variáveis nos modelos de lâmina de Laravel elegantemente?definindo variáveis nos modelos de lâmina de Laravel com elegance entender como atribuir variáveis nos modelos de blade é crucial para arm...Programação Postado em 2025-04-05
-
Como remover os manipuladores anônimos de eventos JavaScript de maneira limpa?removendo os ouvintes anônimos do evento adicionando ouvintes de eventos anônimos a elementos fornece flexibilidade e simplicidade, mas quando é...Programação Postado em 2025-04-05
-
Como o Android envia dados de postagem para o servidor PHP?enviando dados de postagem em Android introdução este artigo aborda a necessidade de enviar dados post para um script php e exibir o resul...Programação Postado em 2025-04-05
-
Como posso configurar o PyTesSeract para reconhecimento de um dígito com a saída apenas para número?pyTesseract OCR com reconhecimento de um dígito e restrições somente para números no contexto do pyTesSeract, a configuração do TESSERACT para...Programação Postado em 2025-04-05
-
Como posso iterar de maneira síncrona e imprimir valores de duas matrizes de tamanho igual no PHP?iterando e imprimindo valores de duas matrizes do mesmo tamanho ao criar uma caixa selecionada usando duas matrizes de tamanho igual, um contend...Programação Postado em 2025-04-05
-
Como posso executar várias instruções SQL em uma única consulta usando node-mysql?suporte de consulta multi-statements em node-mysql em node.js, a pergunta surge ao executar múltiplas declarações SQL em uma única dúvida usan...Programação Postado em 2025-04-05
-
Como enviar uma solicitação de postagem bruta com o CURL no PHP?como enviar uma solicitação de postagem bruta usando o CURL em php em php, o CURL é uma biblioteca popular para enviar http requests. Este art...Programação Postado em 2025-04-05
-
Como limitar o intervalo de rolagem de um elemento dentro de um elemento pai de tamanho dinâmico?implementando limites de altura CSS para elementos de rolagem vertical em uma interface interativa, o controle do comportamento de rolagem dos...Programação Postado em 2025-04-05
-
Por que o Firefox exibe imagens usando a propriedade CSS `Content`?exibindo imagens com URL de conteúdo em Firefox Um problema foi encontrado onde certos navegadores, especificamente Firefox, falham em exibir ...Programação Postado em 2025-04-05
-
Como redirecionar vários tipos de usuários (alunos, professores e administradores) para suas respectivas atividades em um aplicativo Firebase?RED: Como redirecionar vários tipos de usuário para as respectivas atividades compreender o problema e um aplicativo de votamento de que é...Programação Postado em 2025-04-05
-
Como resolver \ "Recusou -se a carregar erros de script ..." devido à política de segurança de conteúdo do Android?revelando o mistério: Erros de diretiva da política de segurança do conteúdo encontrando o erro enigmático "recusou -se a carregar o scri...Programação Postado em 2025-04-05
-
Como você extrai um elemento aleatório de uma matriz no PHP?seleção aleatória de uma matriz em php, a obtenção de um item aleatório de uma matriz pode ser realizado com ease. Considere a seguinte matriz: ...Programação Postado em 2025-04-05
-
Objetos-ajuste: a capa falha no IE e na borda, como consertar?object-fit: a capa falha no ie e borda, como corrigir? utilizando objeto-fit: cover; No CSS, para manter a altura consistente da imagem funcio...Programação Postado em 2025-04-05
-
Por que há listras no meu fundo linear de gradiente e como posso consertá -las?banindo as faixas de fundo do gradiente linear Ao empregar a propriedade linear de gradiente para um plano de fundo, você pode encontrar listr...Programação Postado em 2025-04-05















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









