
ETL: Extraindo o nome de uma pessoa do texto
 Navegar:716
Navegar:716
Digamos que queremos raspar chicagomusiccompass.com.
Como você pode ver, possui vários cartões, cada um representando um evento. Agora vamos conferir o próximo:
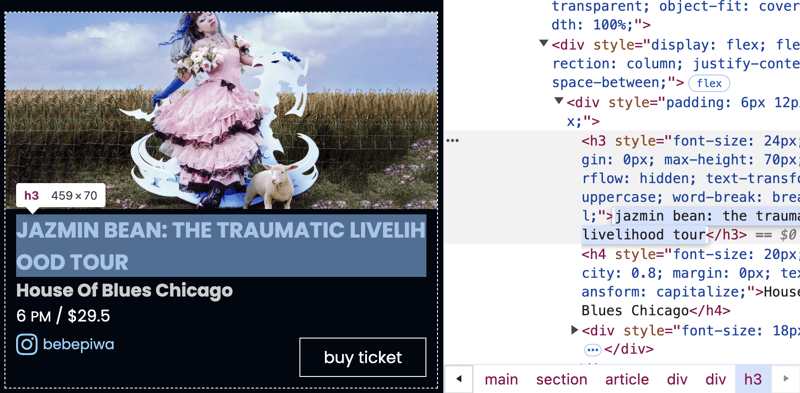
Observe que o nome do evento é:
jazmin bean: the traumatic livelihood tour
Então agora a questão é: Como extraímos o nome do artista do texto?
Como humano, posso dizer "facilmente" que Jazmin Bean é o artista - basta verificar a página wiki deles. Mas escrever código para extrair esse nome pode ser complicado.
Poderíamos pensar: “Ei, qualquer coisa antes de : deveria ser o nome do artista”, o que parece inteligente, certo? Funciona para este caso, mas e este:
happy hour on the patio: kathryn & chris
Aqui, a ordem é invertida. Poderíamos continuar adicionando lógica para lidar com diferentes casos, mas logo acabaremos com uma tonelada de regras que são frágeis e provavelmente não cobrirão tudo.
É aí que os modelos de Named Entity Recognition (NER) são úteis. Eles são de código aberto e podem nos ajudar a extrair nomes do texto. Não vai capturar todos os casos, mas na maioria das vezes, eles nos darão as informações que precisamos.
Com essa abordagem, a extração fica muito mais fácil. Vou com Python porque a comunidade em torno de Machine Learning em Python é simplesmente imbatível.
from gliner import GLiNER
model = GLiNER.from_pretrained("urchade/gliner_base")
text = "jazmin bean: the traumatic livelihood tour"
labels = ["person", "bands", "projects"]
entities = model.predict_entities(text, labels)
for entity in entities:
print(entity["text"], "=>", entity["label"])
O que gera a saída:
jazmin bean => person
Agora, vamos dar uma olhada nesse outro caso:
happy hour on the patio: kathryn & chris
Saída:
kathryn => person chris => person
fonte-GLiNER
Incrível, certo? Chega de lógica tediosa para extrair nomes, basta usar um modelo. Claro, não cobrirá todos os casos possíveis, mas para o meu projeto, esse nível de flexibilidade funciona muito bem. Se precisar de mais precisão, você sempre pode:
- Experimente um modelo diferente
- Contribuir para o modelo existente
- Bifurque o projeto e ajuste-o para atender às suas necessidades
Conclusão
Como desenvolvedor de software, é altamente recomendável manter-se atualizado com as ferramentas do espaço de aprendizado de máquina. Nem tudo pode ser resolvido apenas com programação e lógica simples – alguns desafios são melhor enfrentados usando modelos e estatísticas.
-
 ## Como criar um perfil eficaz do uso de memória PHP: alternativas e práticas recomendadas do XdebugAnalisando o consumo de memória PHPVocê procura uma maneira de examinar minuciosamente o uso de memória de uma página PHP. Especificamente, seu objeti...Programação Publicado em 2024-11-07
## Como criar um perfil eficaz do uso de memória PHP: alternativas e práticas recomendadas do XdebugAnalisando o consumo de memória PHPVocê procura uma maneira de examinar minuciosamente o uso de memória de uma página PHP. Especificamente, seu objeti...Programação Publicado em 2024-11-07 -
Como os componentes são renderizados em um DOM virtual e como otimizar a nova renderizaçãoAo construir aplicativos web modernos, atualizar eficientemente a UI (interface do usuário) é essencial para manter os aplicativos rápidos e responsiv...Programação Publicado em 2024-11-07
-
Operações CRUD: o que são e como posso usá-las?Operações CRUD: o que são e como posso usá-las? As operações CRUD – Criar, Ler, Atualizar e Excluir – são fundamentais para qualquer aplicati...Programação Publicado em 2024-11-07
-
Apresentando o pacote gratuito de utilitários JavaUm kit de ferramentas de programação rápido e fácil de usar para o desenvolvedor back-end Java Em minha vida profissional como administrador e desenvo...Programação Publicado em 2024-11-07
-
Como recuperar chaves de array em um loop PHP Foreach para arrays aninhados?PHP: recuperando chaves de array no loop ForeachEm PHP, iterar sobre um array associativo usando o loop foreach fornece acesso a ambos os valores e ch...Programação Publicado em 2024-11-07
-
Como converter caracteres Latin1 para UTF-8 em uma tabela MySQL?Converter caracteres Latin1 em uma tabela UTF8 em UTF8Você identificou que seus scripts PHP não tinham a função mysql_set_charset necessária para gara...Programação Publicado em 2024-11-07
-
Como usar a API Zapcap (API para legendas)Integrar a API do ZapCap para processamento automatizado de vídeo em seus sistemas existentes é um processo simples projetado para minimizar a complex...Programação Publicado em 2024-11-07
-
Explore componentes de bootstrapBootstrap 5, uma das estruturas de front-end mais populares, traz uma variedade de componentes e utilitários úteis que ajudam os desenvolvedores a cri...Programação Publicado em 2024-11-07
-
Simplifique o gerenciamento de SVG: converta caminhos em um único arquivo JS de constantesAo construir aplicativos React.js, gerenciar ícones SVG de forma eficiente é crucial. Os SVGs fornecem a escalabilidade e a flexibilidade necessárias ...Programação Publicado em 2024-11-07
-
Como cuidar da estrutura do seu código JavaScriptBem! manter uma base de código JavaScript limpa e organizada é essencial para o sucesso do projeto a longo prazo. Uma base de código bem estruturada m...Programação Publicado em 2024-11-07
-
O Overflow pode ser configurado para fluir para a esquerda?O Overflow pode ser configurado para fluir para a esquerda?O overflow normalmente é tratado forçando o conteúdo a fluir para a direita, fazendo com qu...Programação Publicado em 2024-11-07
-
Qual é a diferença crucial entre e?Programação Publicado em 2024-11-07
-
Como combinar matrizes NumPy com diferentes tipos de dados enquanto preserva os tipos de dados?Combinação de arrays com vários tipos de dados em NumPyO desejo de concatenar arrays contendo diferentes tipos de dados em um único array com tipos de...Programação Publicado em 2024-11-07
-
Como alinhar blocos embutidos horizontalmente na mesma linha?Alinhando blocos embutidos horizontalmente na mesma linhaProblemaBlocos embutidos oferecem vantagens sobre elementos flutuantes, como alinhamento de l...Programação Publicado em 2024-11-07
-
Sentindo-se desmotivadoMe sentindo um noob e desisti algumas vezes.. a primeira vez que comecei a pensar em codificação foi quando era criança, mas optei por ser um...Programação Publicado em 2024-11-07















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









