 Primeira página > Programação > Como a otimização de comparação torna a classificação do Python mais rápida
Primeira página > Programação > Como a otimização de comparação torna a classificação do Python mais rápida
Como a otimização de comparação torna a classificação do Python mais rápida
 Navegar:402
Navegar:402
Neste texto os termos Python e CPython, que é a implementação de referência da linguagem, são usados indistintamente. Este artigo aborda especificamente o CPython e não se refere a nenhuma outra implementação do Python.
Python é uma bela linguagem que permite ao programador expressar suas ideias em termos simples, deixando a complexidade da implementação real nos bastidores.
Uma das coisas que ele abstrai é a classificação.
Você pode encontrar facilmente a resposta para a pergunta "como a classificação é implementada em Python?" que quase sempre responde a outra pergunta: "Qual algoritmo de classificação o Python usa?".
No entanto, isso muitas vezes deixa para trás alguns detalhes interessantes de implementação.
Há um detalhe de implementação que acho que não foi discutido o suficiente, embora tenha sido introduzido há mais de sete anos no python 3.7:
sorted() e list.sort() foram otimizados para casos comuns para serem até 40-75% mais rápidos. (Contribuição de Elliot Gorokhovsky em bpo-28685.)
Mas antes de começarmos...
Breve reintrodução à classificação em Python
Quando você precisa classificar uma lista em python, você tem duas opções:
- Um método de lista: list.sort(*, key=None, reverse=False), que classifica a lista fornecida no local
- Uma função integrada: classificada(iterável, /, *, key=None, reverse= False), que retorna uma lista ordenada sem modificar seu argumento
Se você precisar classificar qualquer outro iterável integrado, você só poderá usar classificado independentemente do tipo de iterável ou gerador passado como parâmetro.
sorted sempre retorna uma lista porque usa list.sort internamente.
Aqui está um equivalente aproximado da implementação C classificada do CPython reescrita em python puro:
def sorted(iterable: Iterable[Any], key=None, reverse=False):
new_list = list(iterable)
new_list.sort(key=key, reverse=reverse)
return new_list
Sim, é simples assim.
Como o Python torna a classificação mais rápida
Como diz a documentação interna do Python para classificação:
Às vezes é possível substituir comparações específicas de tipo mais rápidas pelo PyObject_RichCompareBool genérico e mais lento
E resumindo esta otimização pode ser descrita da seguinte forma:
Quando uma lista é homogênea, Python usa função de comparação específica do tipo
O que é uma lista homogênea?
Uma lista homogênea é uma lista que contém elementos apenas de um tipo.
Por exemplo:
homogeneous = [1, 2, 3, 4]
Por outro lado, esta não é uma lista homogênea:
heterogeneous = [1, "2", (3, ), {'4': 4}]
Curiosamente, o tutorial oficial do Python afirma:
Listas são mutáveis e seus elementos são geralmente homogêneos e são acessados iterando sobre a lista
Uma observação lateral sobre tuplas
Esse mesmo tutorial afirma:
Tuplas são imutáveis e geralmente contêm uma sequência heterogênea de elementos
Então, se você já se perguntou quando usar uma tupla ou uma lista, aqui está uma regra prática:
se os elementos forem do mesmo tipo, use uma lista, caso contrário, use uma tupla
Espere, e quanto aos arrays?
Python implementa um objeto contêiner de array homogêneo para valores numéricos.
No entanto, a partir do python 3.12, os arrays não implementam seu próprio método de classificação.
A única maneira de classificá-los é usando sorted, que cria internamente uma lista a partir do array, apagando qualquer informação relacionada ao tipo no processo.
Por que usar a função de comparação específica do tipo ajuda?
Comparações em python são caras, porque Python realiza várias verificações antes de fazer qualquer comparação real.
Aqui está uma explicação simplificada do que acontece nos bastidores quando você compara dois valores em python:
- Python verifica se os valores passados para a função de comparação não são NULL
- Se os valores são de tipos diferentes, mas o operando direito é um subtipo do operando esquerdo, o Python usa a função de comparação do operando direito, mas invertida (por exemplo, ele usará )
- Se os valores forem do mesmo tipo ou de tipos diferentes, mas nenhum deles for subtipo do outro:
- Python tentará primeiro a função de comparação do operando esquerdo
- Se isso falhar, ele tentará a função de comparação do operando correto, mas invertida.
- Se isso também falhar, e a comparação for para igualdade ou desigualdade, ela retornará comparação de identidade (True para valores que se referem ao mesmo objeto na memória)
- Caso contrário, gera TypeError
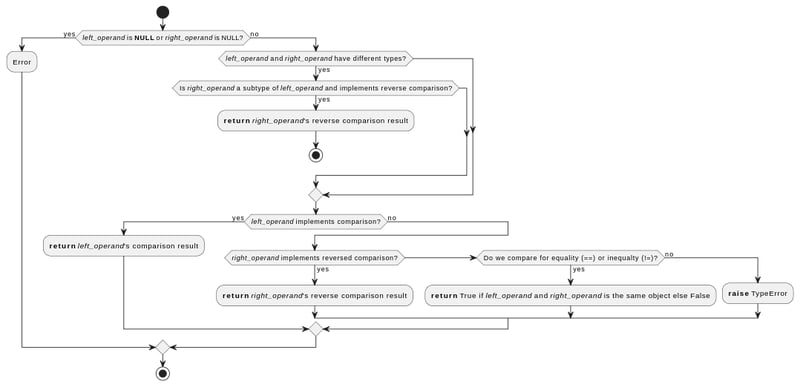
Além disso, as próprias funções de comparação de cada tipo implementam verificações adicionais.
Por exemplo, ao comparar strings, Python verificará se os caracteres da string ocupam mais de um byte de memória, e a comparação de float comparará um par de float's e um float e um int de forma diferente.
Uma explicação e um diagrama mais detalhados podem ser encontrados aqui: Adicionando otimizações de classificação com reconhecimento de dados ao CPython
Antes dessa otimização ser introduzida, o Python tinha que executar todas essas verificações específicas de tipo e não específicas de tipo toda vez que dois valores eram comparados durante a classificação.
Verificando antecipadamente os tipos de elementos da lista
Não há nenhuma maneira mágica de saber se todos os elementos de uma lista são do mesmo tipo, a não ser iterar sobre a lista e verificar cada elemento.
Python faz quase exatamente isso - verificando os tipos de chaves de classificação geradas pela função key passada para list.sort ou classificada como um parâmetro
Construindo uma lista de chaves
Se uma função chave for fornecida, o Python a usará para construir uma lista de chaves, caso contrário, ele usará os próprios valores da lista como chaves de classificação.
De uma maneira simplificada, a construção de chaves pode ser expressa como o seguinte código python.
if key is None:
keys = list_items
else:
keys = [key(list_item) for list_item in list_item]
Observe que as chaves usadas internamente no CPython são uma matriz C de referências de objetos CPython, e não uma lista Python
Depois que as chaves são construídas, o Python verifica seus tipos.
Verificando o tipo de chave
Ao verificar os tipos de chaves, o algoritmo de classificação do Python tenta determinar se todos os elementos no array de chaves são str, int, float ou tuple, ou simplesmente do mesmo tipo, com algumas restrições para tipos base.
É importante notar que verificar os tipos de chaves adiciona algum trabalho extra antecipadamente. Python faz isso porque geralmente compensa, tornando a classificação real mais rápida, especialmente para listas mais longas.
restrições internas
int deveria não ser um bignum
Praticamente isso significa que para que esta otimização funcione, o número inteiro deve ser menor que 2^30 - 1 (isso pode variar dependendo da plataforma)
Como observação, aqui está um ótimo artigo que explica como Python lida com números inteiros grandes: # Como o python implementa números inteiros superlongos?
restrições de string
Todos os caracteres de uma string devem ocupar menos de 1 byte de memória, o que significa que devem ser representados por valores inteiros no intervalo de 0-255
Na prática, isso significa que as strings devem consistir apenas em caracteres latinos, espaços e alguns caracteres especiais encontrados na tabela ASCII.
restrições flutuantes
Não há restrições para floats para que esta otimização funcione.
restrições de tupla
- Apenas o tipo do primeiro elemento é verificado
- Este elemento em si não deve ser uma tupla
- Se todas as tuplas compartilham o mesmo tipo para seu primeiro elemento, a otimização de comparação é aplicada a elas
- Todos os outros elementos são comparados normalmente
Como posso aplicar esse conhecimento?
Em primeiro lugar, não é fascinante saber?
Em segundo lugar, mencionar esse conhecimento pode ser um toque legal em uma entrevista com um desenvolvedor Python.
Quanto ao desenvolvimento real do código, compreender essa otimização pode ajudá-lo a melhorar o desempenho da classificação.
Otimize selecionando o tipo de valores com sabedoria
De acordo com o benchmark no PR que introduziu essa otimização, classificar uma lista que consiste apenas em pontos flutuantes em vez de uma lista de pontos flutuantes com até mesmo um único número inteiro no final é quase duas vezes mais rápido.
Então, quando chegar a hora de otimizar, transforme a lista como esta
floats_and_int = [1.0, -1.0, -0.5, 3]
Em uma lista parecida com esta
just_floats = [1.0, -1.0, -0.5, 3.0] # note that 3.0 is a float now
pode melhorar o desempenho.
Otimize usando chaves para listas de objetos
Embora a otimização de classificação do Python funcione bem com tipos integrados, é importante entender como ela interage com classes personalizadas.
Ao classificar objetos de classes personalizadas, Python depende dos métodos de comparação que você define, como __lt__ (menor que) ou __gt__ (maior que).
No entanto, a otimização específica do tipo não se aplica a classes personalizadas.
Python sempre usará o método de comparação geral para esses objetos.
Aqui está um exemplo:
class MyClass:
def __init__(self, value):
self.value = value
def __lt__(self, other):
return self.value
Nesse caso, Python usará o método __lt__ para comparações, mas não se beneficiará da otimização específica do tipo. A classificação ainda funcionará corretamente, mas pode não ser tão rápida quanto a classificação de tipos integrados.
Se o desempenho for crítico ao classificar objetos personalizados, considere usar uma função chave que retorne um tipo integrado:
sorted_list = sorted(my_list, key=lambda x: x.value)
Posfácio
Otimização prematura, especialmente em Python, é má.
Você não deve projetar toda a sua aplicação em torno de otimizações específicas no CPython, mas é bom estar atento a essas otimizações: conhecer bem suas ferramentas é uma forma de se tornar um desenvolvedor mais qualificado.
Estar atento a otimizações como essas permite que você tire vantagem delas quando a situação exigir, especialmente quando o desempenho se torna crítico:
Considere um cenário onde sua classificação é baseada em carimbos de data/hora: usar uma lista homogênea de números inteiros (carimbos de data/hora Unix) em vez de objetos de data e hora pode aproveitar essa otimização de forma eficaz.
No entanto, é crucial lembrar que a legibilidade e a manutenção do código devem ter precedência sobre tais otimizações.
Embora seja importante saber sobre esses detalhes de baixo nível, é igualmente importante apreciar as abstrações de alto nível do Python que o tornam uma linguagem tão produtiva.
Python é uma linguagem incrível, e explorar suas profundezas pode ajudá-lo a entendê-la melhor e a se tornar um programador Python melhor.
-
 Como faço para selecionar com eficiência colunas nos quadros de dados do pandas?Selecionando colunas em pandas DataFrames Ao lidar com tarefas de manipulação de dados, a seleção de colunas específicas se torna necessária. ...Programação Postado em 2025-07-16
Como faço para selecionar com eficiência colunas nos quadros de dados do pandas?Selecionando colunas em pandas DataFrames Ao lidar com tarefas de manipulação de dados, a seleção de colunas específicas se torna necessária. ...Programação Postado em 2025-07-16 -
Como evitar envios duplicados após a atualização do formulário?impedindo envios duplicados com atualização de manipulação no desenvolvimento da web, é comum encontrar a questão das submissões duplicadas qu...Programação Postado em 2025-07-16
-
Como descobrir dinamicamente os tipos de pacote de exportação no idioma Go?encontrando tipos de pacote exportados dinamicamente em contraste com os recursos de descoberta de tipo limitado no pacote refletir, este arti...Programação Postado em 2025-07-16
-
Como resolver o erro \ "Uso inválido da função do grupo \" no MySQL ao encontrar a contagem máxima?como recuperar a contagem máxima usando o mysql em mysql, você pode encontrar um problema enquanto tenta encontrar a contagem máxima de valore...Programação Postado em 2025-07-16
-
Posso migrar minha criptografia de McRypt para OpenSSL e descriptografar dados criptografados por McRypt usando o OpenSSL?Atualizando minha biblioteca de criptografia de McRypt para OpenSSL posso atualizar minha biblioteca de criptografia de McHRPT para openssl? N...Programação Postado em 2025-07-16
-
Dicas do quadro Spark para adicionar colunas constantescriando uma coluna constante em um Spark DataFrame adicionando uma coluna constante a um Spark Dataframe com um valor arbitrário que se aplica...Programação Postado em 2025-07-16
-
Como superar as restrições de redefinição da função do PHP?superando a função do PHP Redefinição limitações em php, definir uma função com o mesmo nome várias vezes é um não-no. Tentar fazê -lo, como v...Programação Postado em 2025-07-16
-
Método para converter corretamente os caracteres Latin1 em UTF8 na tabela UTF8 MySQLConverte os caracteres latin1 em uma tabela utf8 em utf8 você encontrou um problema em que os caracteres com diacritos (por exemplo, "jáu...Programação Postado em 2025-07-16
-
Por que as imagens ainda têm fronteiras no Chrome? `Border: Nenhum;` Solução inválidaremovendo a borda da imagem em Chrome Uma questão frequente encontrada ao trabalhar com imagens em Chrome e IE9 é a aparência de uma borda fin...Programação Postado em 2025-07-16
-
Causas e soluções para falha na detecção de rosto: erro -215manipulação de erros: resolvendo "error: (-215)! Vazio () na função detectmultisCale" em OpenCV ao tentar utilizar o metrô de detecç...Programação Postado em 2025-07-16
-
\ "while (1) vs. para (;;): a otimização do compilador elimina as diferenças de desempenho? \"while (1) vs. for (;;): existe uma diferença de velocidade? loops? Resposta: Na maioria dos compiladores modernos, não há diferença de dese...Programação Postado em 2025-07-16
-
Como posso lidar com os nomes de arquivos UTF-8 nas funções do sistema de arquivos do PHP?lidando com utf-8 nomes de arquivos nas funções do sistema de arquivos do PHP Ao criar pastas que contêm caracteres utf-8 usando a função mkdi...Programação Postado em 2025-07-16
-
Como remover emojis das cordas em Python: um guia para iniciantes para corrigir erros comuns?removendo emojis de strings em python o código Python fornecido para remover emojis falha porque contém syntaxe erros. As cadeias de unicode d...Programação Postado em 2025-07-16
-
Resolva a exceção \\ "String Value \\" quando o MySQL insere emojiResolvando a exceção do valor da string incorreta ao inserir emoji ao tentar inserir uma string contendo caracteres emoji em um banco de dados M...Programação Postado em 2025-07-16
-
Como analisar números na notação exponencial usando decimal.parse ()?analisando um número da notação exponencial ao tentar analisar uma string expressa em anotação exponencial usando Decimal.parse ("1.2345e...Programação Postado em 2025-07-16















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









