
Crie recomendações \"Para você\" usando IA no Fastly!
 Navegar:278
Navegar:278
Esqueça o hype; onde a IA está agregando valor real? Vamos usar a computação de ponta para aproveitar o poder da IA e criar experiências de usuário mais inteligentes, que também sejam rápidas, seguras e confiáveis.
As recomendações estão por toda parte e todos sabem que tornar as experiências na web mais personalizadas as torna mais envolventes e bem-sucedidas. Minha página inicial da Amazon sabe que gosto de móveis para casa, utensílios de cozinha e, no momento, roupas de verão:
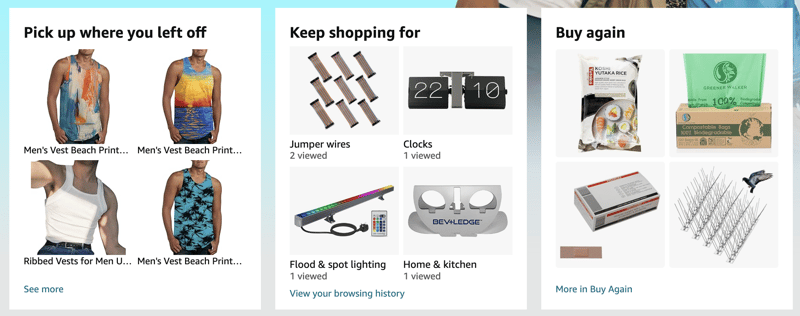
Hoje, a maioria das plataformas faz você escolher entre ser rápido ou personalizado. Na Fastly, achamos que você – e seus usuários – merecem ter ambos. Se toda vez que seu servidor web gera uma página, ela é adequada apenas para um usuário final, você não pode se beneficiar do armazenamento em cache, que é o que redes de ponta como Fastly fazem bem.
Então, como você pode se beneficiar do cache de borda e ainda assim tornar o conteúdo personalizado? Já escrevemos muito sobre como dividir solicitações complexas de clientes em várias solicitações de back-end menores e armazenáveis em cache, e você encontrará tutoriais, exemplos de código e demonstrações no tópico de personalização em nosso hub do desenvolvedor.
Mas e se você quiser ir além e gerar os dados de personalização na borda? A “borda” – os servidores Fastly que gerenciam o tráfego do seu site, são o ponto mais próximo do usuário final que ainda está sob seu controle. Um ótimo lugar para produzir conteúdo específico para um usuário.
O caso de uso "Para você"
As recomendações de produtos são inerentemente transitórias, específicas para um usuário individual e podem mudar com frequência. Mas eles também não precisam persistir – normalmente não precisamos saber o que recomendamos a cada pessoa, apenas se um algoritmo específico consegue uma conversão melhor do que outro. Alguns algoritmos de recomendação precisam de acesso a uma grande quantidade de dados de estado, como quais usuários são mais semelhantes a você e seu histórico de compras ou classificações, mas muitas vezes esses dados são fáceis de pré-gerar em massa.
Basicamente, a geração de recomendações geralmente não cria uma transação, não precisa de nenhum bloqueio em seu armazenamento de dados e faz uso de dados de entrada que estão imediatamente disponíveis na sessão do usuário atual ou criados em um processo de construção offline.
Parece que podemos gerar recomendações no limite!
Um exemplo do mundo real
Vamos dar uma olhada no site do Museu Metropolitano de Arte de Nova York:
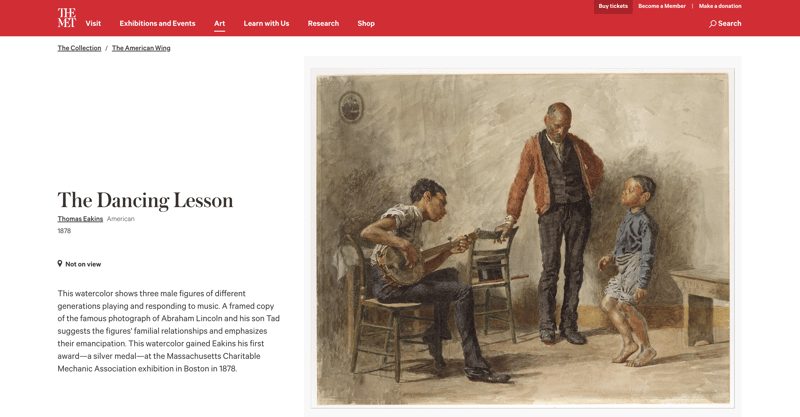
Cada um dos cerca de 500 mil objetos da coleção do Met tem uma página com uma foto e informações sobre ele. Ele também possui esta lista de objetos relacionados:
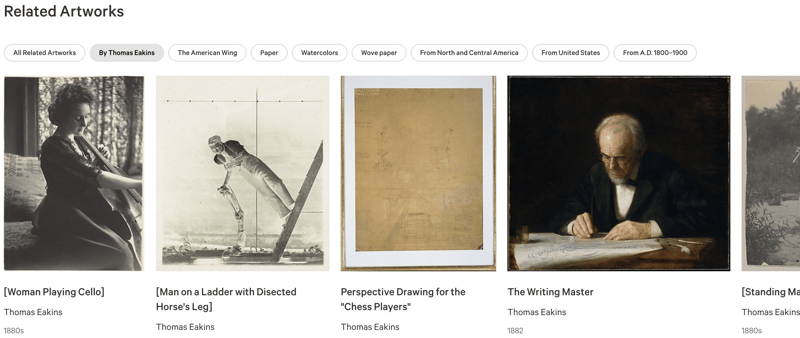
Isso parece usar um sistema bastante simples de lapidação para gerar essas relações, mostrando-me outras obras do mesmo artista, ou outros objetos na mesma ala do museu, ou que também são feitos de papel ou originários do mesmo período de tempo.
O bom deste sistema (do ponto de vista do desenvolvedor!) é que, como ele é baseado apenas em um objeto de entrada, ele pode ser pré-gerado na página.
E se quisermos aumentar isso com uma seleção de recomendações baseadas no histórico de navegação pessoal do usuário final enquanto ele navega pelo site do Met, e não apenas com base neste objeto?
Adicionando recomendações personalizadas
Há muitas maneiras de fazer isso, mas eu queria tentar usar um modelo de linguagem, já que a IA está acontecendo agora, e é realmente diferente da maneira como o mecanismo de obras de arte relacionadas existente do Met parece funcionar. trabalhar. Aqui está o plano:
- Baixe o conjunto de dados de coleta de acesso aberto do Met.
- Execute-o por meio de um modelo de linguagem para criar embeddings vetoriais – listas de números adequados para tarefas de aprendizado de máquina.
- Construa um mecanismo de busca de similaridade de alto desempenho para o meio milhão de vetores resultantes (representando as obras de arte do Met) e carregue-o na loja KV para que possamos usá-lo no Fastly Compute.
Depois de fazermos tudo isso, poderemos, enquanto você navega no site do Met:
- Rastreie as obras de arte que você visita em um cookie.
- Procure os vetores correspondentes a essas obras.
- Calcule um vetor médio que representa seus interesses de navegação.
- Conecte-o ao nosso mecanismo de busca de similaridades para encontrar as obras de arte mais semelhantes.
- Carregue detalhes sobre essas obras de arte da API Met's Object e aumente a página com recomendações personalizadas.
Et voilà, recomendações personalizadas:

OK, então vamos detalhar isso.
Criando o conjunto de dados
O conjunto de dados brutos do Met é um CSV com muitas colunas e se parece com isto:
Object Number,Is Highlight,Is Timeline Work,Is Public Domain,Object ID,Gallery Number,Department,AccessionYear,Object Name,Title,Culture,Period,Dynasty,Reign,Portfolio,Constituent ID,Artist Role,Artist Prefix,Artist Display Name,Artist Display Bio,Artist Suffix,Artist Alpha Sort,Artist Nationality,Artist Begin Date,Artist End Date,Artist Gender,Artist ULAN URL,Artist Wikidata URL,Object Date,Object Begin Date,Object End Date,Medium,Dimensions,Credit Line,Geography Type,City,State,County,Country,Region,Subregion,Locale,Locus,Excavation,River,Classification,Rights and Reproduction,Link Resource,Object Wikidata URL,Metadata Date,Repository,Tags,Tags AAT URL,Tags Wikidata URL 1979.486.1,False,False,False,1,,The American Wing,1979,Coin,One-dollar Liberty Head Coin,,,,,,16429,Maker," ",James Barton Longacre,"American, Delaware County, Pennsylvania 1794–1869 Philadelphia, Pennsylvania"," ","Longacre, James Barton",American,1794 ,1869 ,,http://vocab.getty.edu/page/ulan/500011409,https://www.wikidata.org/wiki/Q3806459,1853,1853,1853,Gold,Dimensions unavailable,"Gift of Heinz L. Stoppelmann, 1979",,,,,,,,,,,,,,http://www.metmuseum.org/art/collection/search/1,,,"Metropolitan Museum of Art, New York, NY",,, 1980.264.5,False,False,False,2,,The American Wing,1980,Coin,Ten-dollar Liberty Head Coin,,,,,,107,Maker," ",Christian Gobrecht,1785–1844," ","Gobrecht, Christian",American,1785 ,1844 ,,http://vocab.getty.edu/page/ulan/500077295,https://www.wikidata.org/wiki/Q5109648,1901,1901,1901,Gold,Dimensions unavailable,"Gift of Heinz L. Stoppelmann, 1980",,,,,,,,,,,,,,http://www.metmuseum.org/art/collection/search/2,,,"Metropolitan Museum of Art, New York, NY",,,
Simples o suficiente para transformar isso em duas colunas, um ID e uma string:
id,description 1,"One-dollar Liberty Head Coin; Type: Coin; Artist: James Barton Longacre; Medium: Gold; Date: 1853; Credit: Gift of Heinz L. Stoppelmann, 1979" 2,"Ten-dollar Liberty Head Coin; Type: Coin; Artist: Christian Gobrecht; Medium: Gold; Date: 1901; Credit: Gift of Heinz L. Stoppelmann, 1980" 3,"Two-and-a-Half Dollar Coin; Type: Coin; Medium: Gold; Date: 1927; Credit: Gift of C. Ruxton Love Jr., 1967"
Agora podemos usar o pacote transformers do conjunto de ferramentas Hugging Face AI e gerar embeddings de cada uma dessas descrições. Usamos o modelo de transformadores de sentença/all-MiniLM-L12-v2 e usamos a análise de componentes principais (PCA) para reduzir os vetores resultantes a 5 dimensões. Isso lhe dá algo como:
[
{
"id": 1,
"vector": [ -0.005544120445847511, -0.030924081802368164, 0.008597176522016525, 0.20186401903629303, 0.0578165128827095 ]
},
{
"id": 2,
"vector": [ -0.005544120445847511, -0.030924081802368164, 0.008597176522016525, 0.20186401903629303, 0.0578165128827095 ]
},
…
]
Temos meio milhão deles, então não é possível armazenar todo esse conjunto de dados na memória do aplicativo Edge. E queremos fazer um tipo personalizado de pesquisa de similaridade sobre esses dados, algo que um armazenamento de valores-chave tradicional não oferece. Como estamos construindo uma experiência em tempo real, também queremos evitar ter que pesquisar meio milhão de vetores por vez.
Então, vamos particionar os dados. Podemos usar o agrupamento KMeans para agrupar vetores semelhantes entre si. Dividimos os dados em 500 clusters de tamanhos variados e calculamos um ponto central denominado “vetor centróide” para cada um desses clusters. Se você plotou este espaço vetorial em duas dimensões e ampliou, ele pode ficar mais ou menos assim:
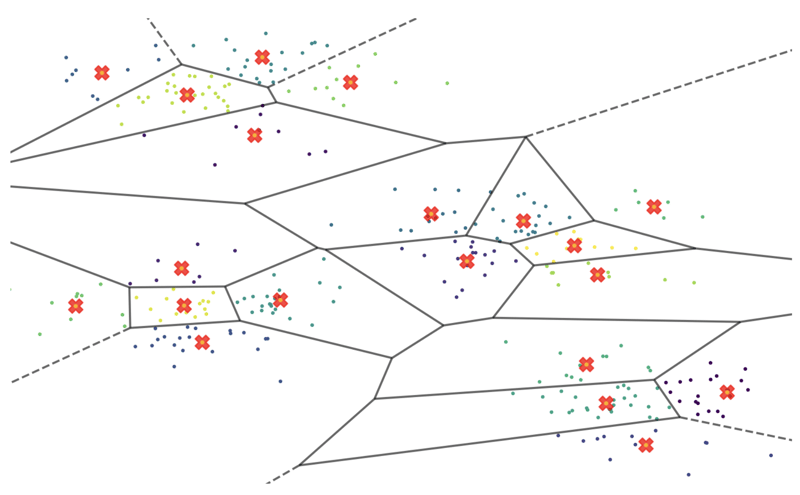
As cruzes vermelhas são os pontos centrais matemáticos de cada agrupamento de vetores, chamados centróides. Eles podem funcionar como localizadores de caminho para nosso espaço de meio milhão de vetores. Por exemplo, se quisermos encontrar os 10 vetores mais semelhantes a um determinado vetor A, podemos primeiro procurar o centróide mais próximo (de 500) e, em seguida, realizar a nossa pesquisa apenas dentro do seu cluster correspondente – uma área muito mais administrável!
Agora temos 500 pequenos conjuntos de dados e um índice que mapeia pontos centróides para o conjunto de dados relevante. Em seguida, para permitir o desempenho em tempo real, queremos pré-compilar gráficos de pesquisa para que não precisemos inicializá-los e construí-los em tempo de execução e possamos usar o mínimo de tempo de CPU possível. Um algoritmo de vizinho mais próximo realmente rápido é Hierarchical Navigable Small Worlds (HNSW), e tem uma implementação Rust pura, que estamos usando para escrever nosso aplicativo de borda. Portanto, escrevemos um pequeno aplicativo Rust autônomo para construir as estruturas gráficas HNSW para cada conjunto de dados e, em seguida, usamos bincode para exportar a memória da estrutura instanciada para um blob binário.
Agora, esses blobs binários podem ser carregados no armazenamento KV, digitados no índice do cluster, e o índice do cluster pode ser incluído em nosso aplicativo Edge.
Essa arquitetura nos permite carregar partes do índice de pesquisa na memória sob demanda. E como nunca teremos que pesquisar mais do que alguns milhares de vetores por vez, nossas pesquisas serão sempre baratas e rápidas.
Construindo o aplicativo de ponta
A aplicação que executamos na borda precisa lidar com vários tipos de solicitações:
- Páginas HTML: Nós as buscamos em metmuseum.org e transformamos a resposta para adicionar tags
- Os recursos de script e estilo do Fastly referenciados por essas tags extras, que podemos servir diretamente do binário do aplicativo Edge.
- O endpoint do recomendador, que gera e retorna as recomendações ** Todas as outras solicitações (não HTML): Imagens e os próprios scripts e folhas de estilo do Met, que fazemos proxy diretamente de seu domínio sem alteração.
Inicialmente construímos este aplicativo em JavaScript, mas acabamos portando a parte do recomendador para Rust porque gostamos da implementação HNSW à distância instantânea.
O JavaScript do lado do cliente faz algumas coisas interessantes:
- Usando IntersectionObserver, acionamos um evento quando o usuário rola a página para baixo até a seção de objetos relacionados. Esta é uma API supereficiente que é muito melhor do que usar métodos mais antigos como onscroll.
- Faça uma busca para nosso endpoint de API de recomendações especiais (que podemos então manipular na borda e retornar informações do objeto)
- Componha algum HTML usando um modelo integrado em uma função do lado do cliente
- Anexe esse HTML à página e mova o observador de interseção para o novo elemento para que, à medida que você rola pelas recomendações, continuemos carregando mais.
Dessa forma, podemos entregar a carga HTML principal sem invocar nosso algoritmo de recomendação, mas as recomendações são entregues rápido o suficiente para que possamos carregá-las conforme você rola e elas quase certamente estarão lá quando você chegar até elas.
Gosto de fazer as coisas dessa maneira porque fornecer ao usuário a primeira visualização acima da dobra o mais rápido possível é absolutamente fundamental. Qualquer coisa que você não possa ver, a menos que role, pode ser carregada mais tarde, especialmente se for um conteúdo complexo e personalizado - não faz sentido gerá-lo se o usuário não estiver planejando rolar.
Pensamentos finais
Portanto, agora você tem o melhor dos dois mundos: a capacidade de fornecer conteúdo altamente personalizado, quase nunca exigindo qualquer bloqueio de busca na origem, e uma carga HTML otimizada que é renderizada incrivelmente rápido, permitindo que seu aplicativo desfrute de escalabilidade efetivamente ilimitada e quase resiliência perfeita.
Não é uma solução perfeita. Seria ótimo se o Fastly oferecesse mais recursos de nível superior para expor dados de borda por meio de mecanismos de consulta diferentes de uma simples pesquisa de chave (informe-nos se isso ajudar você!) e esse mecanismo específico tiver falhas óbvias - se eu tiver interesses separados em duas ou mais coisas muito diferentes (digamos, pinturas a óleo do século 19 e ânforas romanas antigas), eu receberia recomendações que seriam o "ponto médio" semântico teórico entre elas, o que não é um resultado muito útil.
Ainda assim, esperamos que isso demonstre o princípio de que descobrir como trabalhar na borda geralmente resulta em benefícios enormes em termos de escalabilidade, desempenho e resiliência.Conte-nos o que você construiu em community.fastly.com!
-
 Como repetir com eficiência caracteres de string para recuo em C#?repetindo uma string para o indentação Ao recuperar uma string com base na profundidade de um item, é conveniente ter uma maneira eficiente de...Programação Postado em 2025-05-01
Como repetir com eficiência caracteres de string para recuo em C#?repetindo uma string para o indentação Ao recuperar uma string com base na profundidade de um item, é conveniente ter uma maneira eficiente de...Programação Postado em 2025-05-01 -
Posso migrar minha criptografia de McRypt para OpenSSL e descriptografar dados criptografados por McRypt usando o OpenSSL?Atualizando minha biblioteca de criptografia de McRypt para OpenSSL posso atualizar minha biblioteca de criptografia de McHRPT para openssl? N...Programação Postado em 2025-05-01
-
Como posso lidar com os nomes de arquivos UTF-8 nas funções do sistema de arquivos do PHP?lidando com utf-8 nomes de arquivos nas funções do sistema de arquivos do PHP Ao criar pastas que contêm caracteres utf-8 usando a função mkdi...Programação Postado em 2025-05-01
-
Como corrigir “Erro geral: o servidor MySQL 2006 desapareceu” ao inserir dados?Como resolver "Erro geral: o servidor MySQL de 2006 desapareceu" ao inserir registrosIntrodução:A inserção de dados em um banco de dados MyS...Programação Postado em 2025-05-01
-
O Java permite vários tipos de retorno: uma olhada mais próxima dos métodos genéricos?Tipos de retorno múltiplos em java: um equívoco revelado no reino da programação java, e um método peculiar pode surgir, deixando os desenvolv...Programação Postado em 2025-05-01
-
Os parâmetros de modelo podem na função C ++ 20 ConstEval depender dos parâmetros da função?funções constEval e parâmetros de modelos dependentes de argumentos de função em C 17, um parâmetro de modelo não pode depender de um argument...Programação Postado em 2025-05-01
-
Dicas para fotos flutuantes para o lado direito do fundo e envolver o textoflutuando uma imagem para o canto inferior direito com o texto envolvendo no web design, às vezes é desejável flutuar uma imagem no canto infe...Programação Postado em 2025-05-01
-
Qual é a diferença entre funções aninhadas e fechamentos em Pythonfunções aninhadas vs. fechamentos em python enquanto as funções aninhadas em python se assemelham superficialmente, e são fundamentalmente dis...Programação Postado em 2025-05-01
-
Futuro do PHP: adaptação e inovaçãoO futuro do PHP será alcançado adaptando -se a novas tendências de tecnologia e introduzindo recursos inovadores: 1) adaptação à computação em nuvem,...Programação Postado em 2025-05-01
-
Por que o back -end do FASTAPI não envia cookies para reagir front -end?fastapi não pode enviar cookies para reagir frontend visão geral fASTAPI é uma estrutura popular do Python para criar APIs. No entanto, algu...Programação Postado em 2025-05-01
-
Guia de criação de páginas de 404 de 404 da FASTAPIPágina 404 personalizada não encontrada com fastapi para criar uma página 404 personalizada não encontrada, o FASTAPI oferece várias abordagen...Programação Postado em 2025-05-01
-
Como o Android envia dados de postagem para o servidor PHP?enviando dados de postagem em Android introdução este artigo aborda a necessidade de enviar dados post para um script php e exibir o resul...Programação Postado em 2025-05-01
-
Como posso substituir com eficiência várias substringas em uma string java?substituindo várias substâncias em uma string com eficiência em java quando confrontado com a necessidade de substituir várias substringas den...Programação Postado em 2025-05-01
-
Como criar variáveis dinâmicas no Python?Criação variável dinâmica em python A capacidade de criar variáveis dinamicamente pode ser uma ferramenta poderosa, especialmente ao trabalh...Programação Postado em 2025-05-01
-
Como resolver o erro "Não é possível adivinhar o tipo de arquivo, usar aplicativo/stream de octeto ..." no AppEngine?AppEngine Arquivo estático MIME TIPO SUBSENTIDE No AppEngine, os manipuladores de arquivos estáticos podem ocasionalmente substituir o tipo de...Programação Postado em 2025-05-01















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









