
Conecte IA/ML com sua solução Adaptive Analytics
 Navegar:712
Navegar:712
No cenário de dados atual, as empresas enfrentam vários desafios diferentes. Uma delas é fazer análises sobre uma camada de dados unificada e harmonizada disponível para todos os consumidores. Uma camada que pode fornecer as mesmas respostas às mesmas perguntas, independentemente do dialeto ou ferramenta usada.
A InterSystems IRIS Data Platform responde a isso com um complemento de Adaptive Analytics que pode fornecer essa camada semântica unificada. Existem muitos artigos no DevCommunity sobre como usá-lo por meio de ferramentas de BI. Este artigo cobrirá a parte de como consumi-lo com IA e também como recuperar alguns insights.
Vamos passo a passo...
O que é análise adaptativa?
Você pode facilmente encontrar alguma definição no site da comunidade de desenvolvedores
Em poucas palavras, pode fornecer dados de forma estruturada e harmonizada a diversas ferramentas de sua escolha para posterior consumo e análise. Ele fornece as mesmas estruturas de dados para várias ferramentas de BI. Mas... ele também pode fornecer as mesmas estruturas de dados para suas ferramentas de IA/ML!
Adaptive Analytics tem um componente adicional chamado AI-Link que constrói essa ponte entre IA e BI.
O que exatamente é AI-Link?
É um componente Python projetado para permitir a interação programática com a camada semântica com o objetivo de simplificar os principais estágios do fluxo de trabalho de aprendizado de máquina (ML) (por exemplo, engenharia de recursos).
Com AI-Link você pode:
- acessar programaticamente recursos do seu modelo de dados analíticos;
- fazer consultas, explorar dimensões e medidas;
- alimentar pipelines de ML; ... e entregar os resultados de volta à sua camada semântica para serem consumidos novamente por outros (por exemplo, por meio do Tableau ou Excel).
Como esta é uma biblioteca Python, ela pode ser usada em qualquer ambiente Python. Incluindo cadernos.
E neste artigo darei um exemplo simples de como alcançar a solução Adaptive Analytics do Jupyter Notebook com a ajuda do AI-Link.
Aqui está o repositório git que terá o Notebook completo como exemplo: https://github.com/v23ent/aa-hands-on
Pré-requisitos
As próximas etapas pressupõem que você tenha os seguintes pré-requisitos atendidos:
- Solução Adaptive Analytics instalada e funcionando (com IRIS Data Platform como Data Warehouse)
- Jupyter Notebook instalado e funcionando
- A conexão entre 1. e 2. pode ser estabelecida
Etapa 1: configuração
Primeiro, vamos instalar os componentes necessários em nosso ambiente. Isso fará o download de alguns pacotes necessários para que outras etapas funcionem.
'atscale' - este é o nosso pacote principal para conectar
'profeta' - pacote que precisaremos para fazer previsões
pip install atscale prophet
Em seguida, precisaremos importar classes-chave que representam alguns conceitos-chave de nossa camada semântica.
Cliente - classe que usaremos para estabelecer uma conexão com o Adaptive Analytics;
Project – classe para representar projetos dentro do Adaptive Analytics;
DataModel - classe que representará nosso cubo virtual;
from atscale.client import Client from atscale.data_model import DataModel from atscale.project import Project from prophet import Prophet import pandas as pd
Etapa 2: Conexão
Agora devemos estar prontos para estabelecer uma conexão com nossa fonte de dados.
client = Client(server='http://adaptive.analytics.server', username='sample') client.connect()
Vá em frente e especifique os detalhes da conexão da sua instância do Adaptive Analytics. Assim que a organização for solicitada, responda na caixa de diálogo e digite sua senha da instância AtScale.
Com a conexão estabelecida você precisará selecionar seu projeto na lista de projetos publicados no servidor. Você obterá a lista de projetos como um prompt interativo e a resposta deverá ser o ID inteiro do projeto. E então o modelo de dados é selecionado automaticamente se for o único.
project = client.select_project() data_model = project.select_data_model()
Etapa 3: explore seu conjunto de dados
Existem vários métodos preparados pelo AtScale na biblioteca de componentes AI-Link. Eles permitem explorar o catálogo de dados que você possui, consultar dados e até mesmo ingerir alguns dados de volta. A documentação do AtScale possui uma extensa referência de API que descreve tudo o que está disponível.
Vamos primeiro ver qual é o nosso conjunto de dados chamando alguns métodos de data_model:
data_model.get_features() data_model.get_all_categorical_feature_names() data_model.get_all_numeric_feature_names()
A saída deve ser semelhante a esta
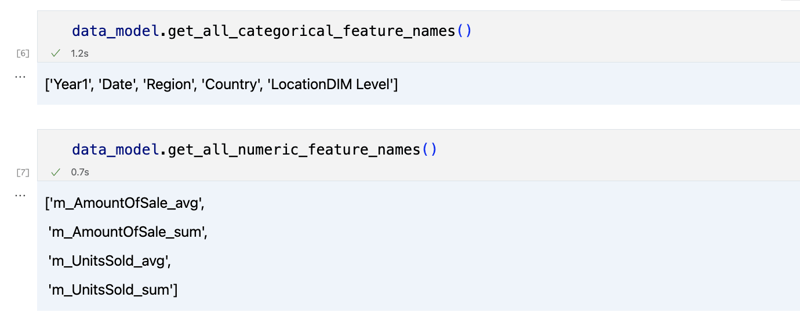
Depois de dar uma olhada um pouco, podemos consultar os dados reais nos quais estamos interessados usando o método 'get_data'. Ele retornará um DataFrame do pandas contendo os resultados da consulta.
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum']) df = df.sort_values(by='m_AmountOfSale_sum') df.head()
Que mostrará seu datadrame:
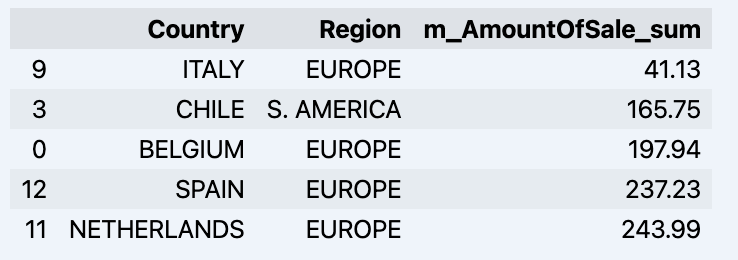
Vamos preparar um conjunto de dados e mostrá-lo rapidamente no gráfico
import matplotlib.pyplot as plt
# We're taking sales for each date
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Create a line chart
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Add labels and a title
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Display the chart
plt.show()
Saída:
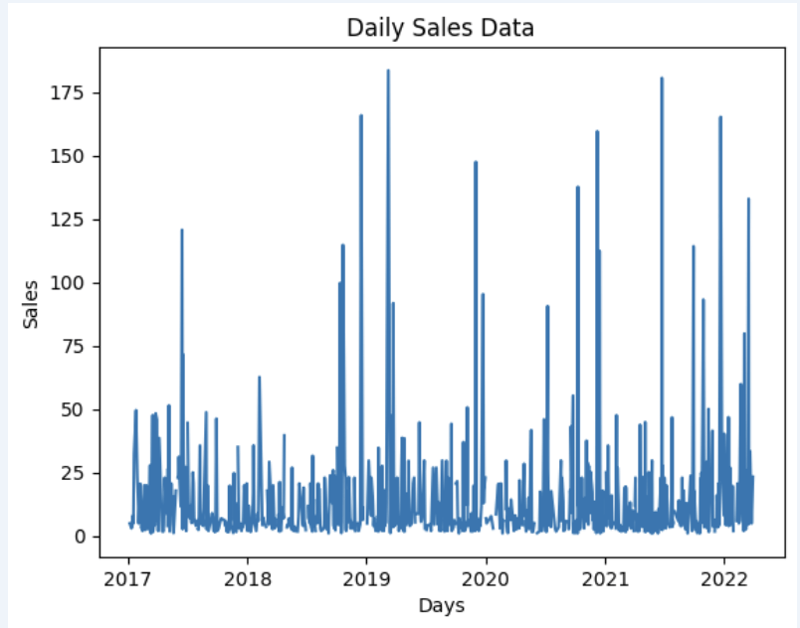
Etapa 4: previsão
O próximo passo seria realmente obter algum valor da ponte AI-Link - vamos fazer algumas previsões simples!
# Load the historical data to train the model
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
Obtemos dois conjuntos de dados diferentes aqui: para treinar nosso modelo e testá-lo.
# For the tool we've chosen to do the prediction 'Prophet', we'll need to specify 2 columns: 'ds' and 'y'
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Initialize and fit the Prophet model
model = Prophet()
model.fit(data_train)
E então criamos outro dataframe para acomodar nossa previsão e exibi-la no gráfico
# Create a future dataframe for forecasting future = pd.DataFrame() future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D') # Make predictions forecast = model.predict(future) fig = model.plot(forecast) fig.show()
Saída:
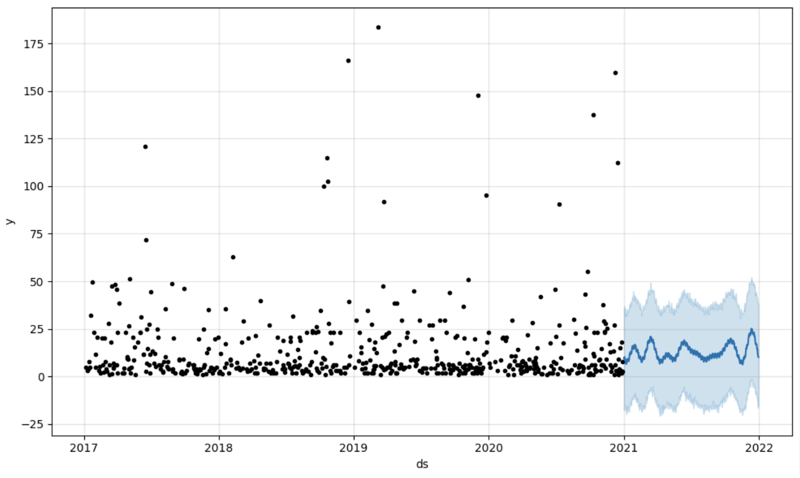
Etapa 5: Writeback
Depois de definirmos nossa previsão, podemos colocá-la de volta no data warehouse e adicionar um agregado ao nosso modelo semântico para refleti-lo para outros consumidores. A previsão estaria disponível através de qualquer outra ferramenta de BI para analistas de BI e usuários empresariais.
A própria previsão será colocada em nosso data warehouse e armazenada lá.
from atscale.db.connections import Iris
db = Iris(
username,
host,
namespace,
driver,
schema,
port=1972,
password=None,
warehouse_id=None
)data_model.writeback(dbconn=db,
table_name= 'SalesPrediction',
DataFrame = forecast)data_model.create_aggregate_feature(dataset_name='SalesPrediction',
column_name='SalesForecasted',
name='sum_sales_forecasted',
aggregation_type='SUM')
Final
É isso!
Boa sorte com suas previsões!
-
 Implementação dinâmica reflexiva da interface GO para exploração de método RPCreflexão para a implementação da interface dinâmica em go A reflexão em Go é uma ferramenta poderosa que permite a inspeção e manipulação do c...Programação Postado em 2025-04-27
Implementação dinâmica reflexiva da interface GO para exploração de método RPCreflexão para a implementação da interface dinâmica em go A reflexão em Go é uma ferramenta poderosa que permite a inspeção e manipulação do c...Programação Postado em 2025-04-27 -
Como corrigir “Erro geral: o servidor MySQL 2006 desapareceu” ao inserir dados?Como resolver "Erro geral: o servidor MySQL de 2006 desapareceu" ao inserir registrosIntrodução:A inserção de dados em um banco de dados MyS...Programação Postado em 2025-04-27
-
Como lidar com a memória fatiada na coleção de lixo de idiomas Go?coleta de lixo em go slies: uma análise detalhada em go, uma fatia é uma matriz dinâmica que faz referência a uma matriz subjacente. Ao trabal...Programação Postado em 2025-04-27
-
Resolva a exceção \\ "String Value \\" quando o MySQL insere emojiResolvando a exceção do valor da string incorreta ao inserir emoji ao tentar inserir uma string contendo caracteres emoji em um banco de dados M...Programação Postado em 2025-04-27
-
Como recuperar com eficiência a última linha para cada identificador exclusivo no PostGresql?postGresql: Extraindo a última linha para cada identificador exclusivo em postgresql, você pode encontrar situações em que você precisa extrai...Programação Postado em 2025-04-27
-
Como superar as restrições de redefinição da função do PHP?superando a função do PHP Redefinição limitações em php, definir uma função com o mesmo nome várias vezes é um não-no. Tentar fazê -lo, como v...Programação Postado em 2025-04-27
-
Como resolver o erro "Não é possível adivinhar o tipo de arquivo, usar aplicativo/stream de octeto ..." no AppEngine?AppEngine Arquivo estático MIME TIPO SUBSENTIDE No AppEngine, os manipuladores de arquivos estáticos podem ocasionalmente substituir o tipo de...Programação Postado em 2025-04-27
-
Como simplificar a análise JSON no PHP para matrizes multidimensionais?analisando JSON com php tentando analisar os dados JSON no PHP pode ser um desafio, especialmente ao lidar com matrizes multidimensionais. Para ...Programação Postado em 2025-04-27
-
Como criar variáveis dinâmicas no Python?Criação variável dinâmica em python A capacidade de criar variáveis dinamicamente pode ser uma ferramenta poderosa, especialmente ao trabalh...Programação Postado em 2025-04-27
-
Tags de formatação HTMLElementos de formatação HTML **HTML Formatting is a process of formatting text for better look and feel. HTML provides us ability to form...Programação Postado em 2025-04-27
-
Como o Android envia dados de postagem para o servidor PHP?enviando dados de postagem em Android introdução este artigo aborda a necessidade de enviar dados post para um script php e exibir o resul...Programação Postado em 2025-04-27
-
Como posso unindo tabelas de banco de dados com diferentes números de colunas?tabelas combinadas com diferentes colunas ] pode encontrar desafios ao tentar mesclar tabelas de banco de dados com colunas diferentes. Uma man...Programação Postado em 2025-04-27
-
Como inserir corretamente Blobs (imagens) no MySQL usando PHP?Insira Blobs nos bancos de dados MySQL com PHP Ao tentar armazenar uma imagem no banco de dados A MySQL, você pode encontrar um problema. Est...Programação Postado em 2025-04-27
-
Qual é a diferença entre funções aninhadas e fechamentos em Pythonfunções aninhadas vs. fechamentos em python enquanto as funções aninhadas em python se assemelham superficialmente, e são fundamentalmente dis...Programação Postado em 2025-04-27
-
Eval () vs. AST.LITERAL_EVAL (): Qual função Python é mais segura para a entrada do usuário?pesando avaliação () e ast.literal_eval () na python Security Ao lidar com a entrada do usuário, é imperativo priorizar a segurança. Eval (), ...Programação Postado em 2025-04-27















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









