
Snowflake(SiS)에서 Streamlit을 사용하여 토큰 개수 확인 앱을 만들었습니다.
 검색:153
검색:153
소개
안녕하세요. 저는 Snowflake의 영업 엔지니어입니다. 다양한 포스팅을 통해 저의 경험과 실험을 여러분과 공유하고 싶습니다. 이 기사에서는 토큰 수를 확인하고 Cortex LLM의 비용을 추정하기 위해 Snowflake에서 Streamlit을 사용하여 앱을 만드는 방법을 보여 드리겠습니다.
참고: 이 게시물은 Snowflake의 의견이 아닌 개인적인 견해를 나타냅니다.
Snowflake(SiS)의 Streamlit이란 무엇입니까?
Streamlit은 HTML/CSS/JavaScript가 필요 없이 간단한 Python 코드로 웹 UI를 만들 수 있는 Python 라이브러리입니다. 앱 갤러리에서 예시를 보실 수 있습니다.
Snowflake의 Streamlit을 사용하면 Snowflake에서 직접 Streamlit 웹 앱을 개발하고 실행할 수 있습니다. Snowflake 계정만 있으면 사용하기 쉽고 Snowflake 테이블 데이터를 웹 앱에 통합하는 데 적합합니다.
Snowflake의 Streamlit 정보(공식 Snowflake 문서)
눈송이 피질이란 무엇입니까?
Snowflake Cortex는 Snowflake의 생성 AI 기능 모음입니다. Cortex LLM을 사용하면 SQL 또는 Python의 간단한 함수를 사용하여 Snowflake에서 실행되는 대규모 언어 모델을 호출할 수 있습니다.
LLM(대형 언어 모델) 기능(Snowflake Cortex)(공식 Snowflake 문서)
기능 개요
영상
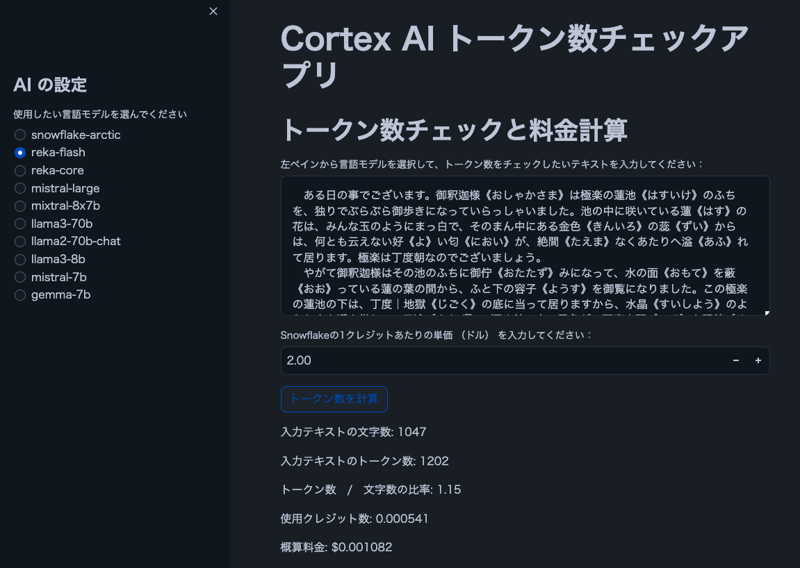
참고: 이미지의 텍스트는 아쿠타가와 류노스케의 "거미줄"에서 가져온 것입니다.
특징
- 사용자는 Cortex LLM 모델을 선택할 수 있습니다.
- 사용자 입력 텍스트의 문자 및 토큰 수 표시
- 문자 대비 토큰 비율 표시
- Snowflake 크레딧 가격을 기준으로 예상 비용 계산
참고: Cortex LLM 가격표(PDF)
전제 조건
- Cortex LLM 액세스 권한이 있는 Snowflake 계정
- snowflake-ml-python 1.1.2 이상
참고: Cortex LLM 지역 가용성(공식 Snowflake 문서)
소스 코드
import streamlit as st
from snowflake.snowpark.context import get_active_session
import snowflake.snowpark.functions as F
# Get current session
session = get_active_session()
# Application title
st.title("Cortex AI Token Count Checker")
# AI settings
st.sidebar.title("AI Settings")
lang_model = st.sidebar.radio("Select the language model you want to use",
("snowflake-arctic", "reka-core", "reka-flash",
"mistral-large2", "mistral-large", "mixtral-8x7b", "mistral-7b",
"llama3.1-405b", "llama3.1-70b", "llama3.1-8b",
"llama3-70b", "llama3-8b", "llama2-70b-chat",
"jamba-instruct", "gemma-7b")
)
# Function to count tokens (using Cortex's token counting function)
def count_tokens(model, text):
result = session.sql(f"SELECT SNOWFLAKE.CORTEX.COUNT_TOKENS('{model}', '{text}') as token_count").collect()
return result[0]['TOKEN_COUNT']
# Token count check and cost calculation
st.header("Token Count Check and Cost Calculation")
input_text = st.text_area("Select a language model from the left pane and enter the text you want to check for token count:", height=200)
# Let user input the price per credit
credit_price = st.number_input("Enter the price per Snowflake credit (in dollars):", min_value=0.0, value=2.0, step=0.01)
# Credits per 1M tokens for each model (as of 2024/8/30, mistral-large2 is not supported)
model_credits = {
"snowflake-arctic": 0.84,
"reka-core": 5.5,
"reka-flash": 0.45,
"mistral-large2": 1.95,
"mistral-large": 5.1,
"mixtral-8x7b": 0.22,
"mistral-7b": 0.12,
"llama3.1-405b": 3,
"llama3.1-70b": 1.21,
"llama3.1-8b": 0.19,
"llama3-70b": 1.21,
"llama3-8b": 0.19,
"llama2-70b-chat": 0.45,
"jamba-instruct": 0.83,
"gemma-7b": 0.12
}
if st.button("Calculate Token Count"):
if input_text:
# Calculate character count
char_count = len(input_text)
st.write(f"Character count of input text: {char_count}")
if lang_model in model_credits:
# Calculate token count
token_count = count_tokens(lang_model, input_text)
st.write(f"Token count of input text: {token_count}")
# Ratio of tokens to characters
ratio = token_count / char_count if char_count > 0 else 0
st.write(f"Token count / Character count ratio: {ratio:.2f}")
# Cost calculation
credits_used = (token_count / 1000000) * model_credits[lang_model]
cost = credits_used * credit_price
st.write(f"Credits used: {credits_used:.6f}")
st.write(f"Estimated cost: ${cost:.6f}")
else:
st.warning("The selected model is not supported by Snowflake's token counting feature.")
else:
st.warning("Please enter some text.")
결론
이 앱을 사용하면 특히 문자 수와 토큰 수 사이에 차이가 있는 일본어와 같은 언어를 처리할 때 LLM 워크로드 비용을 더 쉽게 추정할 수 있습니다. 도움이 되셨기를 바랍니다!
공지사항
X의 Snowflake 새로운 기능 업데이트
X에 대한 Snowflake의 새로운 기능 업데이트를 공유하고 있습니다. 관심이 있으시면 언제든지 팔로우해주세요!
영어 버전
Snowflake What's New Bot(영어 버전)
https://x.com/snow_new_en
일본어 버전
Snowflake What's New Bot(일본어 버전)
https://x.com/snow_new_jp
변경 내역
(20240914) 초기 게시물
일본어 원본 기사
https://zenn.dev/tsubasa_tech/articles/4dd80c91508ec4
-
 Laravel Eloquent의 firstOrNew() 메소드를 사용하여 CRUD 작업을 효과적으로 최적화하는 방법은 무엇입니까?Laravel Eloquent로 CRUD 작업 최적화Laravel에서 데이터베이스 작업을 할 때 레코드를 삽입하거나 업데이트하는 것이 일반적입니다. 이를 달성하기 위해 개발자는 삽입 또는 업데이트 수행을 결정하기 전에 레코드가 존재하는지 확인하는 조건문에 의존하는 경우...프로그램 작성 2024-11-06에 게시됨
Laravel Eloquent의 firstOrNew() 메소드를 사용하여 CRUD 작업을 효과적으로 최적화하는 방법은 무엇입니까?Laravel Eloquent로 CRUD 작업 최적화Laravel에서 데이터베이스 작업을 할 때 레코드를 삽입하거나 업데이트하는 것이 일반적입니다. 이를 달성하기 위해 개발자는 삽입 또는 업데이트 수행을 결정하기 전에 레코드가 존재하는지 확인하는 조건문에 의존하는 경우...프로그램 작성 2024-11-06에 게시됨 -
PHP에서 메서드 매개변수를 재정의하는 것이 엄격한 표준을 위반하는 이유는 무엇입니까?PHP의 메서드 매개변수 재정의: 엄격한 표준 위반객체 지향 프로그래밍에서 Liskov 대체 원칙(LSP)은 다음을 나타냅니다. 하위 유형의 개체는 프로그램의 동작을 변경하지 않고 상위 개체를 대체할 수 있습니다. 그러나 PHP에서는 다른 매개변수 서명으로 메서드를 재...프로그램 작성 2024-11-06에 게시됨
-
XAMPP 재배치 후 \"테이블이 엔진에 존재하지 않습니다\" #1932 오류가 발생하는 이유는 무엇입니까?프로그램 작성 2024-11-06에 게시됨
-
우수한 SQL 주입 방지 기능(PDO 또는 mysql_real_escape_string)을 제공하는 PHP 라이브러리는 무엇입니까?PDO와 mysql_real_escape_string: 종합 가이드쿼리 이스케이프는 SQL 주입을 방지하는 데 중요합니다. mysql_real_escape_string은 쿼리 이스케이프를 위한 기본적인 방법을 제공하지만 PDO는 수많은 이점을 지닌 우수한 솔루션으로 등...프로그램 작성 2024-11-06에 게시됨
-
React 시작하기: 초보자 로드맵안녕하세요 여러분! ? 저는 이제 막 React.js를 배우기 시작했습니다. 그것은 흥미롭고 때로는 도전적인 모험이었습니다. 여러분도 React에 뛰어들고 있다면 시작하는 데 도움이 된 단계를 공유하고 싶었습니다. 제가 접근하는 방법은 다음과 같습니다. 1. JavaS...프로그램 작성 2024-11-06에 게시됨
-
JavaScript 개체 내에서 내부 값을 참조하려면 어떻게 해야 합니까?JavaScript 객체 내에서 내부 값을 참조하는 방법JavaScript에서 동일한 객체 내의 다른 값을 참조하는 객체 내 값에 액세스 때로는 어려울 수 있습니다. 다음 코드 조각을 고려하십시오.var obj = { key1: "it ", k...프로그램 작성 2024-11-06에 게시됨
-
예제가 포함된 Python 목록 메서드에 대한 빠른 가이드소개 Python 목록은 다목적이며 데이터를 효율적으로 조작하고 처리하는 데 도움이 되는 다양한 내장 메서드가 함께 제공됩니다. 다음은 간단한 예와 함께 모든 주요 목록 메서드에 대한 빠른 참조입니다. 1. 추가(항목) 목록 끝에 항목을 ...프로그램 작성 2024-11-06에 게시됨
-
C++에서 사용자 정의 복사 생성자는 언제 필수입니까?사용자 정의 복사 생성자는 언제 필요합니까?복사 생성자는 C 객체 지향 프로그래밍에 필수적이며 기존 인스턴스를 기반으로 객체를 초기화하는 수단을 제공합니다. 컴파일러는 일반적으로 클래스에 대한 기본 복사 생성자를 생성하지만 사용자 정의가 필요한 시나리오가 있습니다.사용...프로그램 작성 2024-11-06에 게시됨
-
시도해 보세요...V/s를 잡아보세요 안전한 할당(?=): 현대 개발에 도움이 될까요 아니면 저주가 될까요?최근 JavaScript에 도입된 새로운 안전 할당 연산자(?.=)를 발견했는데 그 단순함에 정말 매료되었습니다. ? SAO(안전 할당 연산자)는 기존 try...catch 블록에 대한 약식 대안입니다. 이를 통해 각 작업에 대해 명시적인 오류 처리 코드를 작성하지 않...프로그램 작성 2024-11-06에 게시됨
-
Python에서 고정 너비 파일 구문 분석을 최적화하는 방법은 무엇입니까?고정 너비 파일 구문 분석 최적화고정 너비 파일을 효율적으로 구문 분석하려면 Python의 구조체 모듈을 활용하는 것이 좋습니다. 이 접근 방식은 다음 예에서 볼 수 있듯이 속도 향상을 위해 C를 활용합니다.import struct fieldwidths = (2, -1...프로그램 작성 2024-11-06에 게시됨
-
MySQL 숙달 능력을 발휘하세요: MySQL 실습 랩 과정포괄적인 MySQL Practice Labs 과정을 통해 MySQL 기술을 향상하고 데이터베이스 전문가가 되세요. 이 실습 학습 경험은 일련의 실제 연습을 안내하여 복잡한 SQL 문제를 해결하고 데이터베이스 성능을 최적화할 수 있도록 설계되었습니다. My...프로그램 작성 2024-11-06에 게시됨
-
Gmail을 통해 이메일을 보낼 때 \"SMTP Connect() 실패\" 오류를 수정하는 방법은 무엇입니까?SMTP 연결 실패: "SMTP Connect() 실패" 오류 해결Gmail을 사용하여 이메일을 보내려고 하면 오류가 발생할 수 있습니다. "SMTP -> 오류: 서버 연결 실패: 연결 시간 초과(110)\nSMTP Connect()가 실패했...프로그램 작성 2024-11-06에 게시됨
-
Pillow를 사용하여 Python에서 여러 이미지를 가로로 연결하는 방법은 무엇입니까?Python을 사용하여 이미지를 수평으로 연결여러 이미지를 수평으로 결합하는 것은 이미지 처리에서 일반적인 작업입니다. Python은 Pillow 라이브러리를 사용하여 이를 달성하기 위한 강력한 도구를 제공합니다.문제 설명148 x 95 크기의 정사각형 JPEG 이미지...프로그램 작성 2024-11-06에 게시됨















중국어 공부
- 1 "걷다"를 중국어로 어떻게 말하나요? 走路 중국어 발음, 走路 중국어 학습
- 2 "비행기를 타다"를 중국어로 어떻게 말하나요? 坐飞机 중국어 발음, 坐飞机 중국어 학습
- 3 "기차를 타다"를 중국어로 어떻게 말하나요? 坐火车 중국어 발음, 坐火车 중국어 학습
- 4 "버스를 타다"를 중국어로 어떻게 말하나요? 坐车 중국어 발음, 坐车 중국어 학습
- 5 운전을 중국어로 어떻게 말하나요? 开车 중국어 발음, 开车 중국어 학습
- 6 수영을 중국어로 뭐라고 하나요? 游泳 중국어 발음, 游泳 중국어 학습
- 7 자전거를 타다 중국어로 뭐라고 하나요? 骑自行车 중국어 발음, 骑自行车 중국어 학습
- 8 중국어로 안녕하세요를 어떻게 말해요? 你好중국어 발음, 你好중국어 학습
- 9 감사합니다를 중국어로 어떻게 말하나요? 谢谢중국어 발음, 谢谢중국어 학습
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









