
사례 연구: 단어의 발생
 검색:418
검색:418
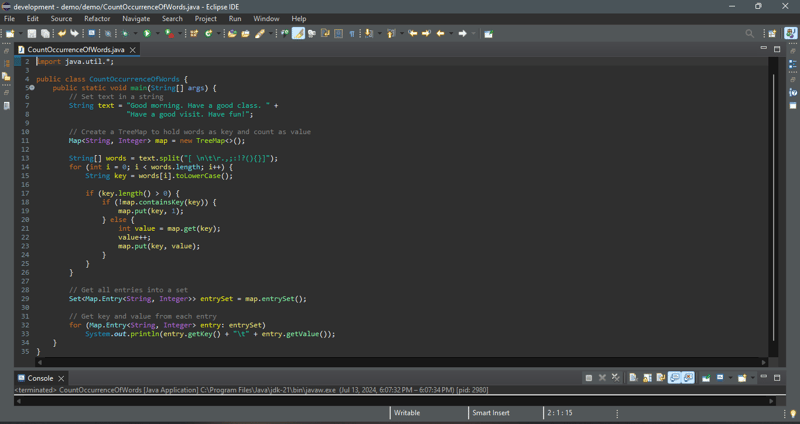
이 사례 연구는 텍스트에서 단어의 발생 횟수를 세고 단어와 그 발생 횟수를 단어의 알파벳 순서로 표시하는 프로그램을 작성합니다. 프로그램은 TreeMap을 사용하여 단어와 그 개수로 구성된 항목을 저장합니다. 각 단어에 대해 이미 맵에 키가 있는지 확인하세요. 그렇지 않은 경우 단어를 키로 하고 값 1을 사용하여 맵에 항목을 추가합니다. 그렇지 않으면 맵에서 단어(키)의 값을 1만큼 늘립니다. 단어는 대소문자를 구분하지 않는다고 가정합니다. 예를 들어, 좋음은 좋음.
과 동일하게 취급됩니다.아래 코드는 문제에 대한 해결책을 제공합니다.
2
1급
재미 1
좋아요 3
3개
아침 1
1번 방문
프로그램은 단어 쌍과 그 발생 횟수를 저장하기 위해 TreeMap(라인 11)을 생성합니다. 단어가 열쇠 역할을 합니다. 맵의 모든 값은 객체로 저장되어야 하므로 개수는 정수 객체
로 래핑됩니다.프로그램은 String 클래스의 split 메소드(13행)를 사용하여 텍스트에서 단어를 추출합니다. 추출된 각 단어에 대해 프로그램은 해당 단어가 이미 맵에 키로 저장되어 있는지 확인합니다(18행). 그렇지 않은 경우 단어와 초기 개수(1)로 구성된 새 쌍이 맵에 저장됩니다(19행). 그렇지 않으면 단어 개수가 1만큼 증가합니다(21-23행).
프로그램은 세트의 지도 항목을 획득하고(29행) 세트를 순회하여 각 항목의 개수와 키를 표시합니다(32-33행).
지도는 트리맵이므로 항목이 단어의 오름차순으로 표시됩니다. 발생 횟수의 오름차순으로 표시할 수도 있습니다.
이제 편안히 앉아 지도를 사용하지 않고 이 프로그램을 어떻게 작성하는지 생각해 보세요. 새 프로그램은 더 길고 복잡해질 것입니다. 맵은 이와 같은 문제를 해결하는 데 매우 효율적이고 강력한 데이터 구조라는 것을 알게 될 것입니다.
-
 FormData ()로 여러 파일 업로드를 처리하려면 어떻게해야합니까?); 그러나이 코드는 첫 번째 선택된 파일 만 처리합니다. 파일 : var files = document.getElementById ( 'filetOUpload'). 파일; for (var x = 0; x프로그램 작성 2025-04-20에 게시되었습니다
FormData ()로 여러 파일 업로드를 처리하려면 어떻게해야합니까?); 그러나이 코드는 첫 번째 선택된 파일 만 처리합니다. 파일 : var files = document.getElementById ( 'filetOUpload'). 파일; for (var x = 0; x프로그램 작성 2025-04-20에 게시되었습니다 -
열의 열이 다른 데이터베이스 테이블을 어떻게 통합하려면 어떻게해야합니까?다른 열이있는 결합 테이블 ] 는 데이터베이스 테이블을 다른 열로 병합하려고 할 때 도전에 직면 할 수 있습니다. 간단한 방법은 열이 적은 테이블의 누락 된 열에 null 값을 추가하는 것입니다. 예를 들어, 표 B보다 더 많은 열이있는 두 개의 테이블,...프로그램 작성 2025-04-20에 게시되었습니다
-
익명의 JavaScript 이벤트 처리기를 깨끗하게 제거하는 방법은 무엇입니까?익명 이벤트 리스너를 제거하는 데 익명의 이벤트 리스너 추가 요소를 추가하면 유연성과 단순성을 제공하지만 유연성과 단순성을 제공하지만, 그것들을 제거 할 시간이되면, 요소 자체를 교체하지 않고 도전 할 수 있습니다. 요소? element.addevent...프로그램 작성 2025-04-20에 게시되었습니다
-
모든 브라우저에서 좌회전 텍스트의 슬래시 메소드 구현] ] 경사 선의 텍스트 정렬 배경 기울어 진 줄에서 왼쪽 정렬 된 텍스트를 달성하면 비밀리에 특히 도전이 될 수 있습니다. 호환성 (IE9로 돌아 가기). 솔루션 Lletion lless 를 사용하여 일련의 정사각형 요소를 소개하고 크기를 계산하여 효과적...프로그램 작성 2025-04-20에 게시되었습니다
-
MySQL 오류 #1089 : 잘못된 접두사 키를 얻는 이유는 무엇입니까?오류 설명 [#1089- 잘못된 접두사 키 "는 테이블에서 열에 프리픽스 키를 만들려고 시도 할 때 나타날 수 있습니다. 접두사 키는 특정 접두사 길이의 문자열 열 길이를 색인화하도록 설계되었으며, 접두사를 더 빠르게 검색 할 수 있습니...프로그램 작성 2025-04-20에 게시되었습니다
-
유효한 코드에도 불구하고 PHP의 입력을 캡처하는 사후 요청이없는 이유는 무엇입니까?post request 오작동 주소 php action='' action = "프로그램 작성 2025-04-20에 게시되었습니다
-
동시에 비동기 작업을 동시에 실행하고 JavaScript에서 오류를 올바르게 처리하는 방법은 무엇입니까?동시 동시 대기 업무 수행 실행 비동기 작업을 수행 할 때 문제가 발생합니다. getValue2async (); 이 구현은 다음 작업을 시작하기 전에 각 작업의 완료를 순차적으로 기다립니다. 동시 실행을 가능하게하려면 수정 된 접근 방식...프로그램 작성 2025-04-20에 게시되었습니다
-
-
PHP 새로 고침 후 세션 데이터가 손실되는 이유는 무엇입니까?이 특정 경우, 사용자는 페이지 새로 고침 후 세션 데이터가 유지되지 않는 특이한 상황에 직면했습니다. 조사는 PHP 스크립트에 대한 명백한 변경 사항이 밝혀지지 않았다. 근본 원인을 결정하기 위해 사용자는 PHP 버전 (4.4.7) 및 PHPINFO () 출력을...프로그램 작성 2025-04-20에 게시되었습니다
-
SQL Server에서 Nolock을 사용하여 성능을 향상시킬 수 있습니까?SQL Server의 Nolock : 성능 향상 및 위험 공존 SQL Server의 트랜잭션 격리 수준은 동시 트랜잭션에 대한 데이터 수정이 서로가 보이지 않도록합니다. 그러나이 보안 메커니즘은 경합 및 성능 병목 현상으로 이어질 수 있습니다. 이러한 문...프로그램 작성 2025-04-20에 게시되었습니다
-
파이썬에서 문자열에서 이모티콘을 제거하는 방법 : 일반적인 오류 수정에 대한 초보자 가이드?Codecs 가져 오기. 가져 오기 re text = codecs.decode ( '이 개 \ u0001f602'.encode ('utf-8 '),'utf-8 ') 인쇄 (텍스트) # 이모티콘으로 emoji_patter...프로그램 작성 2025-04-20에 게시되었습니다
-
Sprite Group의 클릭 객체 감지 및 "AttributeError : Group이 속성이 없습니다"오류를 해결합니다.솔루션 솔루션 이 문제를 해결하기 위해 마우스 그룹의 스프라이트를 통해 반복하고 각 스프라이트의 rect 속성에 대해 마우스 클릭을 확인할 수 있습니다 : pygame # 마우스 커서 위치를 얻습니다 mouse_pos = pygame.mouse.get_...프로그램 작성 2025-04-20에 게시되었습니다
-
파이썬 멀티 프로세스 풀에서 키보드 인터럽트를 처리하는 방법은 무엇입니까?문제 : 주어진 Python 코드에서 풀이 생성되고 시도 노출 블록을 사용하여 키보드 인터럽트를 처리하려고 시도합니다. 그러나 제외 블록 내의 해당 코드는 절대 실행되지 않아 프로그램이 매달려 있습니다. try : results = pool...프로그램 작성 2025-04-20에 게시되었습니다
-
인라인 블록 열을 수직으로 정렬하는 방법은 무엇입니까?. cont span { 디스플레이 : 인라인 블록; 수직 정상 : 상단; 높이 : 100%; 라인 높이 : 100%; 너비 : 33.33%; 개요 : 1px 점선 빨간색; / * 데모 만용 */ } 대체 접근 방식 ...프로그램 작성 2025-04-20에 게시되었습니다
-
자바 스크립트 객체의 키를 알파벳순으로 정렬하는 방법은 무엇입니까?object.keys (...) . .sort () . 정렬 된 속성을 보유 할 새 개체를 만듭니다. 정렬 된 키 어레이를 반복하고 리소셔 함수를 사용하여 원래 객체에서 새 객체에 해당 값과 함께 각 키를 추가합니다. 다음 코드는 프로세...프로그램 작성 2025-04-20에 게시되었습니다















중국어 공부
- 1 "걷다"를 중국어로 어떻게 말하나요? 走路 중국어 발음, 走路 중국어 학습
- 2 "비행기를 타다"를 중국어로 어떻게 말하나요? 坐飞机 중국어 발음, 坐飞机 중국어 학습
- 3 "기차를 타다"를 중국어로 어떻게 말하나요? 坐火车 중국어 발음, 坐火车 중국어 학습
- 4 "버스를 타다"를 중국어로 어떻게 말하나요? 坐车 중국어 발음, 坐车 중국어 학습
- 5 운전을 중국어로 어떻게 말하나요? 开车 중국어 발음, 开车 중국어 학습
- 6 수영을 중국어로 뭐라고 하나요? 游泳 중국어 발음, 游泳 중국어 학습
- 7 자전거를 타다 중국어로 뭐라고 하나요? 骑自行车 중국어 발음, 骑自行车 중국어 학습
- 8 중국어로 안녕하세요를 어떻게 말해요? 你好중국어 발음, 你好중국어 학습
- 9 감사합니다를 중국어로 어떻게 말하나요? 谢谢중국어 발음, 谢谢중국어 학습
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









