
웹 스크래핑 최적화: JSDOM을 사용하여 인증 데이터 스크래핑
 검색:580
검색:580
스크래핑 개발자로서 작업을 수행하기 위해 임시 키와 같은 인증 데이터를 추출해야 하는 경우가 있습니다. 그러나 그렇게 간단하지는 않습니다. 일반적으로 HTML 또는 XHR 네트워크 요청에 있지만 인증 데이터가 계산되는 경우도 있습니다. 이 경우 계산을 리버스 엔지니어링하여 스크립트를 난독 해제하는 데 많은 시간이 걸리거나 이를 계산하는 JavaScript를 실행할 수 있습니다. 일반적으로 우리는 브라우저를 사용하지만 비용이 많이 듭니다. Crawlee는 브라우저 스크레이퍼와 Cheerio Scraper를 병렬로 실행하는 지원을 제공하지만 이는 컴퓨팅 리소스 사용 측면에서 매우 복잡하고 비용이 많이 듭니다. JSDOM은 브라우저보다 적은 리소스와 Cheerio보다 약간 높은 리소스로 페이지 JavaScript를 실행하는 데 도움이 됩니다.
이 기사에서는 실제로 브라우저를 실행하지 않고 JSDOM을 사용하여 브라우저 웹 애플리케이션에서 생성된 TikTok 광고 크리에이티브 센터에서 인증 데이터를 얻기 위해 Actor 중 한 명에서 사용하는 새로운 접근 방식에 대해 논의합니다.
웹사이트 분석 중
다음 URL을 방문하는 경우:
https://ads.tiktok.com/business/creativecenter/inspirion/popular/hashtag/pc/en
실시간 순위, 게시물 수, 트렌드 차트, 작성자 및 분석이 포함된 해시태그 목록이 표시됩니다. 또한 업계를 필터링하고, 기간을 설정하고, 체크박스를 사용하여 해당 트렌드가 상위 100위 안에 새로운 것인지 여부를 필터링할 수 있다는 것을 알 수 있습니다.
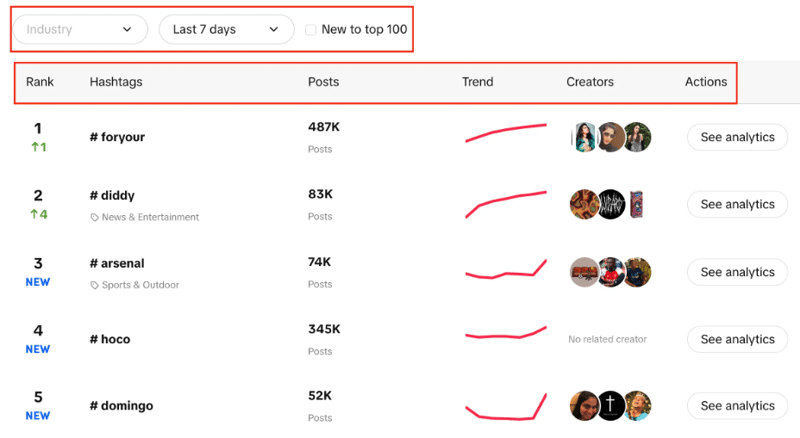
여기서 우리의 목표는 주어진 필터를 사용하여 목록에서 상위 100개의 해시태그를 추출하는 것입니다.
두 가지 가능한 접근 방식은 CheerioCrawler를 사용하는 것이고 두 번째는 브라우저 기반 스크래핑입니다. Cheerio는 결과를 더 빠르게 제공하지만 JavaScript로 렌더링된 웹사이트에서는 작동하지 않습니다.
Cheerio는 Creative Center가 웹 애플리케이션이고 데이터 소스가 API이므로 여기서는 최선의 옵션이 아닙니다. 따라서 처음에 HTML 구조에 있는 해시태그만 가져올 수 있고 필요한 100개 각각을 가져올 수는 없습니다.
두 번째 접근 방식은 Puppeteer, Playwright 등과 같은 라이브러리를 사용하여 브라우저 기반 스크래핑을 수행하고 자동화를 사용하여 모든 해시태그를 스크래핑하는 것입니다. 그러나 이전 경험으로는 이러한 작은 작업에 많은 시간이 걸립니다.
이제 이 프로세스를 브라우저 기반보다 훨씬 더 우수하고 CheerioCrawler 기반 크롤링에 매우 가깝게 만들기 위해 개발한 새로운 접근 방식이 제공됩니다.
JSDOM 접근 방식
이 접근 방식에 대해 자세히 알아보기 전에 이 접근 방식을 개발한 Apify의 웹 자동화 엔지니어인 Alexey Udovydchenko에게 감사를 표하고 싶습니다. 그에게 찬사를 보냅니다!
이 접근 방식에서는 필수 데이터를 얻기 위해 https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list에 대한 API 호출을 수행할 것입니다.
이 API를 호출하기 전에 몇 가지 필수 헤더(인증 데이터)가 필요하므로 먼저 https://ads.tiktok.com/business/creativecenter/inspirion/popular/hashtag/pad를 호출하겠습니다. /ko.
API 호출에 대한 URL을 생성하고, 호출하고, 데이터를 가져오는 함수를 생성하는 것으로 이 접근 방식을 시작하겠습니다.
export const createStartUrls = (input) => {
const {
days = '7',
country = '',
resultsLimit = 100,
industry = '',
isNewToTop100,
} = input;
const filterBy = isNewToTop100 ? 'new_on_board' : '';
return [
{
url: `https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list?page=1&limit=50&period=${days}&country_code=${country}&filter_by=${filterBy}&sort_by=popular&industry_id=${industry}`,
headers: {
// required headers
},
userData: { resultsLimit },
},
];
};
위 함수에서는 앞서 이야기한 것처럼 다양한 매개변수를 포함하는 API 호출에 대한 시작 URL을 생성합니다. 매개변수에 따라 URL을 생성한 후 creative_radar_api를 호출하고 모든 결과를 가져옵니다.
하지만 헤더를 얻을 때까지는 작동하지 않습니다. 그럼 먼저 sessionPool과 ProxyConfiguration을 사용하여 세션을 생성하는 함수를 만들어 보겠습니다.
export const createSessionFunction = async (
sessionPool,
proxyConfiguration,
) => {
const proxyUrl = await proxyConfiguration.newUrl(Math.random().toString());
const url =
'https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en';
// need url with data to generate token
const response = await gotScraping({ url, proxyUrl });
const headers = await getApiUrlWithVerificationToken(
response.body.toString(),
url,
);
if (!headers) {
throw new Error(`Token generation blocked`);
}
log.info(`Generated API verification headers`, Object.values(headers));
return new Session({
userData: {
headers,
},
sessionPool,
});
};
이 함수의 주요 목표는 https://ads.tiktok.com/business/creativecenter/inspirion/popular/hashtag/pad/en을 호출하여 응답으로 헤더를 얻는 것입니다. 헤더를 얻으려면 getApiUrlWithVerificationToken 함수를 사용하고 있습니다.
진행하기 전에 Crawlee가 기본적으로 JSDOM Crawler를 사용하여 JSDOM을 지원한다는 점을 언급하고 싶습니다. 이는 일반 HTTP 요청과 jsdom DOM 구현을 사용하여 웹 페이지의 병렬 크롤링을 위한 프레임워크를 제공합니다. 원시 HTTP 요청을 사용하여 웹페이지를 다운로드하며 데이터 대역폭이 매우 빠르고 효율적입니다.
getApiUrlWithVerificationToken 함수를 어떻게 생성하는지 살펴보겠습니다.
const getApiUrlWithVerificationToken = async (body, url) => {
log.info(`Getting API session`);
const virtualConsole = new VirtualConsole();
const { window } = new JSDOM(body, {
url,
contentType: 'text/html',
runScripts: 'dangerously',
resources: 'usable' || new CustomResourceLoader(),
// ^ 'usable' faster than custom and works without canvas
pretendToBeVisual: false,
virtualConsole,
});
virtualConsole.on('error', () => {
// ignore errors cause by fake XMLHttpRequest
});
const apiHeaderKeys = ['anonymous-user-id', 'timestamp', 'user-sign'];
const apiValues = {};
let retries = 10;
// api calls made outside of fetch, hack below is to get URL without actual call
window.XMLHttpRequest.prototype.setRequestHeader = (name, value) => {
if (apiHeaderKeys.includes(name)) {
apiValues[name] = value;
}
if (Object.values(apiValues).length === apiHeaderKeys.length) {
retries = 0;
}
};
window.XMLHttpRequest.prototype.open = (method, urlToOpen) => {
if (
['static', 'scontent'].find((x) =>
urlToOpen.startsWith(`https://${x}`),
)
)
log.debug('urlToOpen', urlToOpen);
};
do {
await sleep(4000);
retries--;
} while (retries > 0);
await window.close();
return apiValues;
};
이 함수에서는 CustomResourceLoader를 사용하여 백그라운드 프로세스를 실행하고 브라우저를 JSDOM으로 바꾸는 가상 콘솔을 생성합니다.
이 특정 예에서는 API 호출을 위해 세 가지 필수 헤더가 필요하며 이는 익명 사용자 ID, 타임스탬프 및 사용자 서명입니다.
XMLHttpRequest.prototype.setRequestHeader를 사용하여 언급된 헤더가 응답에 있는지 확인하고, 그렇다면 해당 헤더의 값을 가져와서 모든 헤더를 얻을 때까지 재시도를 반복합니다.
그런 다음 가장 중요한 부분은 실제로 브라우저를 사용하거나 봇 활동을 노출하지 않고 XMLHttpRequest.prototype.open을 사용하여 인증 데이터를 추출하고 호출하는 것입니다.
createSessionFunction이 끝나면 필수 헤더가 포함된 세션을 반환합니다.
이제 기본 코드로 이동하여 CheerioCrawler를 사용하고 prenavigationHooks를 사용하여 이전 함수에서 얻은 헤더를 requestHandler에 삽입합니다.
const crawler = new CheerioCrawler({
sessionPoolOptions: {
maxPoolSize: 1,
createSessionFunction: async (sessionPool) =>
createSessionFunction(sessionPool, proxyConfiguration),
},
preNavigationHooks: [
(crawlingContext) => {
const { request, session } = crawlingContext;
request.headers = {
...request.headers,
...session.userData?.headers,
};
},
],
proxyConfiguration,
});
마지막으로 요청 핸들러에서 헤더를 사용하여 호출을 수행하고 모든 데이터 처리 페이지 매김을 가져오는 데 필요한 호출 수를 확인합니다.
async requestHandler(context) {
const { log, request, json } = context;
const { userData } = request;
const { itemsCounter = 0, resultsLimit = 0 } = userData;
if (!json.data) {
throw new Error('BLOCKED');
}
const { data } = json;
const items = data.list;
const counter = itemsCounter items.length;
const dataItems = items.slice(
0,
resultsLimit && counter > resultsLimit
? resultsLimit - itemsCounter
: undefined,
);
await context.pushData(dataItems);
const {
pagination: { page, total },
} = data;
log.info(
`Scraped ${dataItems.length} results out of ${total} from search page ${page}`,
);
const isResultsLimitNotReached =
counter
여기서 주목해야 할 한 가지 중요한 점은 이 코드를 원하는 만큼 API 호출을 할 수 있는 방식으로 만들고 있다는 것입니다.
이 특정 예에서는 하나의 요청과 단일 세션을 만들었지만 필요한 경우 더 만들 수 있습니다. 첫 번째 API 호출이 완료되면 두 번째 API 호출이 생성됩니다. 다시 한 번 말씀드리지만, 필요하다면 더 많은 전화를 걸 수 있지만 우리는 2시에 멈췄습니다.
더 명확하게 설명하기 위해 코드 흐름은 다음과 같습니다.
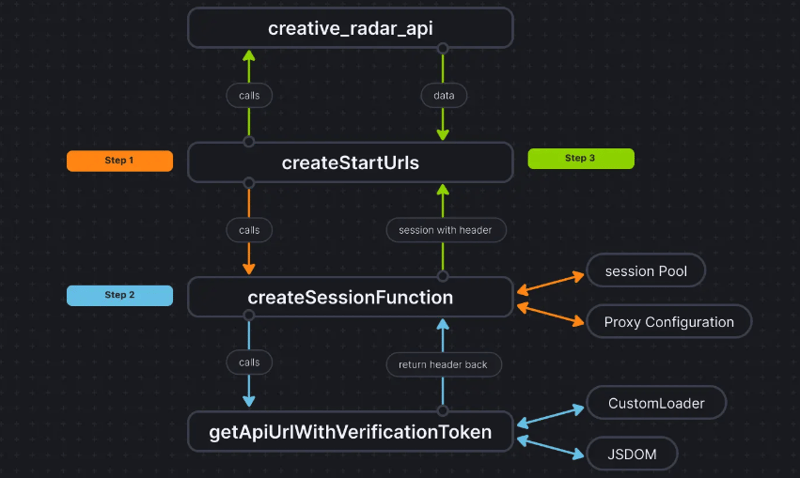
결론
이 접근 방식은 실제로 브라우저를 사용하지 않고 인증 데이터를 추출하고 데이터를 CheerioCrawler에 전달하는 세 번째 방법을 얻는 데 도움이 됩니다. 이로 인해 성능이 크게 향상되고 RAM 요구 사항이 50% 감소합니다. 브라우저 기반 스크래핑 성능은 순수 Cheerio보다 10배 느리지만 JSDOM은 3~4배만 느려 브라우저보다 2~3배 빠릅니다. 기반 스크래핑.
프로젝트의 코드베이스가 이미 여기에 업로드되었습니다. 코드는 Apify Actor로 작성되었습니다. 자세한 내용은 여기에서 확인할 수 있지만 Apify SDK를 사용하지 않고도 실행할 수도 있습니다.
이 접근 방식에 대해 의문 사항이나 질문이 있는 경우 Discord 서버에 문의하세요.
-
 FormData ()로 여러 파일 업로드를 처리하려면 어떻게해야합니까?); 그러나이 코드는 첫 번째 선택된 파일 만 처리합니다. 파일 : var files = document.getElementById ( 'filetOUpload'). 파일; for (var x = 0; x프로그램 작성 2025-04-20에 게시되었습니다
FormData ()로 여러 파일 업로드를 처리하려면 어떻게해야합니까?); 그러나이 코드는 첫 번째 선택된 파일 만 처리합니다. 파일 : var files = document.getElementById ( 'filetOUpload'). 파일; for (var x = 0; x프로그램 작성 2025-04-20에 게시되었습니다 -
열의 열이 다른 데이터베이스 테이블을 어떻게 통합하려면 어떻게해야합니까?다른 열이있는 결합 테이블 ] 는 데이터베이스 테이블을 다른 열로 병합하려고 할 때 도전에 직면 할 수 있습니다. 간단한 방법은 열이 적은 테이블의 누락 된 열에 null 값을 추가하는 것입니다. 예를 들어, 표 B보다 더 많은 열이있는 두 개의 테이블,...프로그램 작성 2025-04-20에 게시되었습니다
-
익명의 JavaScript 이벤트 처리기를 깨끗하게 제거하는 방법은 무엇입니까?익명 이벤트 리스너를 제거하는 데 익명의 이벤트 리스너 추가 요소를 추가하면 유연성과 단순성을 제공하지만 유연성과 단순성을 제공하지만, 그것들을 제거 할 시간이되면, 요소 자체를 교체하지 않고 도전 할 수 있습니다. 요소? element.addevent...프로그램 작성 2025-04-20에 게시되었습니다
-
모든 브라우저에서 좌회전 텍스트의 슬래시 메소드 구현] ] 경사 선의 텍스트 정렬 배경 기울어 진 줄에서 왼쪽 정렬 된 텍스트를 달성하면 비밀리에 특히 도전이 될 수 있습니다. 호환성 (IE9로 돌아 가기). 솔루션 Lletion lless 를 사용하여 일련의 정사각형 요소를 소개하고 크기를 계산하여 효과적...프로그램 작성 2025-04-20에 게시되었습니다
-
MySQL 오류 #1089 : 잘못된 접두사 키를 얻는 이유는 무엇입니까?오류 설명 [#1089- 잘못된 접두사 키 "는 테이블에서 열에 프리픽스 키를 만들려고 시도 할 때 나타날 수 있습니다. 접두사 키는 특정 접두사 길이의 문자열 열 길이를 색인화하도록 설계되었으며, 접두사를 더 빠르게 검색 할 수 있습니...프로그램 작성 2025-04-20에 게시되었습니다
-
유효한 코드에도 불구하고 PHP의 입력을 캡처하는 사후 요청이없는 이유는 무엇입니까?post request 오작동 주소 php action='' action = "프로그램 작성 2025-04-20에 게시되었습니다
-
동시에 비동기 작업을 동시에 실행하고 JavaScript에서 오류를 올바르게 처리하는 방법은 무엇입니까?동시 동시 대기 업무 수행 실행 비동기 작업을 수행 할 때 문제가 발생합니다. getValue2async (); 이 구현은 다음 작업을 시작하기 전에 각 작업의 완료를 순차적으로 기다립니다. 동시 실행을 가능하게하려면 수정 된 접근 방식...프로그램 작성 2025-04-20에 게시되었습니다
-
-
PHP 새로 고침 후 세션 데이터가 손실되는 이유는 무엇입니까?이 특정 경우, 사용자는 페이지 새로 고침 후 세션 데이터가 유지되지 않는 특이한 상황에 직면했습니다. 조사는 PHP 스크립트에 대한 명백한 변경 사항이 밝혀지지 않았다. 근본 원인을 결정하기 위해 사용자는 PHP 버전 (4.4.7) 및 PHPINFO () 출력을...프로그램 작성 2025-04-20에 게시되었습니다
-
SQL Server에서 Nolock을 사용하여 성능을 향상시킬 수 있습니까?SQL Server의 Nolock : 성능 향상 및 위험 공존 SQL Server의 트랜잭션 격리 수준은 동시 트랜잭션에 대한 데이터 수정이 서로가 보이지 않도록합니다. 그러나이 보안 메커니즘은 경합 및 성능 병목 현상으로 이어질 수 있습니다. 이러한 문...프로그램 작성 2025-04-20에 게시되었습니다
-
파이썬에서 문자열에서 이모티콘을 제거하는 방법 : 일반적인 오류 수정에 대한 초보자 가이드?Codecs 가져 오기. 가져 오기 re text = codecs.decode ( '이 개 \ u0001f602'.encode ('utf-8 '),'utf-8 ') 인쇄 (텍스트) # 이모티콘으로 emoji_patter...프로그램 작성 2025-04-20에 게시되었습니다
-
Sprite Group의 클릭 객체 감지 및 "AttributeError : Group이 속성이 없습니다"오류를 해결합니다.솔루션 솔루션 이 문제를 해결하기 위해 마우스 그룹의 스프라이트를 통해 반복하고 각 스프라이트의 rect 속성에 대해 마우스 클릭을 확인할 수 있습니다 : pygame # 마우스 커서 위치를 얻습니다 mouse_pos = pygame.mouse.get_...프로그램 작성 2025-04-20에 게시되었습니다
-
파이썬 멀티 프로세스 풀에서 키보드 인터럽트를 처리하는 방법은 무엇입니까?문제 : 주어진 Python 코드에서 풀이 생성되고 시도 노출 블록을 사용하여 키보드 인터럽트를 처리하려고 시도합니다. 그러나 제외 블록 내의 해당 코드는 절대 실행되지 않아 프로그램이 매달려 있습니다. try : results = pool...프로그램 작성 2025-04-20에 게시되었습니다
-
인라인 블록 열을 수직으로 정렬하는 방법은 무엇입니까?. cont span { 디스플레이 : 인라인 블록; 수직 정상 : 상단; 높이 : 100%; 라인 높이 : 100%; 너비 : 33.33%; 개요 : 1px 점선 빨간색; / * 데모 만용 */ } 대체 접근 방식 ...프로그램 작성 2025-04-20에 게시되었습니다
-
자바 스크립트 객체의 키를 알파벳순으로 정렬하는 방법은 무엇입니까?object.keys (...) . .sort () . 정렬 된 속성을 보유 할 새 개체를 만듭니다. 정렬 된 키 어레이를 반복하고 리소셔 함수를 사용하여 원래 객체에서 새 객체에 해당 값과 함께 각 키를 추가합니다. 다음 코드는 프로세...프로그램 작성 2025-04-20에 게시되었습니다















중국어 공부
- 1 "걷다"를 중국어로 어떻게 말하나요? 走路 중국어 발음, 走路 중국어 학습
- 2 "비행기를 타다"를 중국어로 어떻게 말하나요? 坐飞机 중국어 발음, 坐飞机 중국어 학습
- 3 "기차를 타다"를 중국어로 어떻게 말하나요? 坐火车 중국어 발음, 坐火车 중국어 학습
- 4 "버스를 타다"를 중국어로 어떻게 말하나요? 坐车 중국어 발음, 坐车 중국어 학습
- 5 운전을 중국어로 어떻게 말하나요? 开车 중국어 발음, 开车 중국어 학습
- 6 수영을 중국어로 뭐라고 하나요? 游泳 중국어 발음, 游泳 중국어 학습
- 7 자전거를 타다 중국어로 뭐라고 하나요? 骑自行车 중국어 발음, 骑自行车 중국어 학습
- 8 중국어로 안녕하세요를 어떻게 말해요? 你好중국어 발음, 你好중국어 학습
- 9 감사합니다를 중국어로 어떻게 말하나요? 谢谢중국어 발음, 谢谢중국어 학습
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









