
K 최근접이웃 회귀, 회귀: 지도 머신러닝
 검색:300
검색:300
k-최근접이웃 회귀
k-NN(k-Nearest Neighbors) 회귀는 특징 공간에서 k-최근접 학습 데이터 포인트의 평균(또는 가중 평균)을 기반으로 출력 값을 예측하는 비모수적 방법입니다. 이 접근 방식은 특정 기능적 형태를 가정하지 않고도 데이터의 복잡한 관계를 효과적으로 모델링할 수 있습니다.
k-NN 회귀 방법은 다음과 같이 요약할 수 있습니다.
- 거리 측정법: 알고리즘은 거리 측정법(일반적으로 유클리드 거리)을 사용하여 데이터 포인트의 "가까움"을 결정합니다.
- k 이웃: 매개변수 k는 예측 시 고려해야 할 가장 가까운 이웃 수를 지정합니다.
- 예측: 새 데이터 포인트에 대한 예측 값은 k개의 최근접 이웃 값의 평균입니다.
주요 개념
비모수적: 매개변수적 모델과 달리 k-NN은 입력 특성과 대상 변수 간의 기본 관계에 대해 특정 형식을 가정하지 않습니다. 이를 통해 복잡한 패턴을 유연하게 캡처할 수 있습니다.
거리 계산: 거리 측정법의 선택은 모델 성능에 큰 영향을 미칠 수 있습니다. 일반적인 측정항목에는 유클리드, 맨해튼, 민코프스키 거리가 포함됩니다.
k 선택: 교차 검증을 기반으로 이웃 수(k)를 선택할 수 있습니다. k가 작으면 과적합이 발생할 수 있고, k가 크면 예측이 너무 평활화되어 잠재적으로 과소적합이 발생할 수 있습니다.
k-최근접이웃 회귀 예제
이 예에서는 k-NN의 비모수적 특성을 활용하면서 다항식 기능이 포함된 k-NN 회귀를 사용하여 복잡한 관계를 모델링하는 방법을 보여줍니다.
Python 코드 예
1. 라이브러리 가져오기
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import PolynomialFeatures from sklearn.neighbors import KNeighborsRegressor from sklearn.metrics import mean_squared_error, r2_score
이 블록은 데이터 조작, 플로팅 및 기계 학습에 필요한 라이브러리를 가져옵니다.
2. 샘플 데이터 생성
np.random.seed(42) # For reproducibility X = np.linspace(0, 10, 100).reshape(-1, 1) y = 3 * X.ravel() np.sin(2 * X.ravel()) * 5 np.random.normal(0, 1, 100)
이 블록은 실제 데이터 변형을 시뮬레이션하여 일부 노이즈와의 관계를 나타내는 샘플 데이터를 생성합니다.
3. 데이터세트 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
이 블록은 모델 평가를 위해 데이터 세트를 훈련 세트와 테스트 세트로 분할합니다.
4. 다항식 특징 생성
degree = 3 # Change this value for different polynomial degrees poly = PolynomialFeatures(degree=degree) X_poly_train = poly.fit_transform(X_train) X_poly_test = poly.transform(X_test)
이 블록은 교육 및 테스트 데이터 세트에서 다항식 기능을 생성하여 모델이 비선형 관계를 캡처할 수 있도록 합니다.
5. k-NN 회귀 모델 생성 및 훈련
k = 5 # Number of neighbors knn_model = KNeighborsRegressor(n_neighbors=k) knn_model.fit(X_poly_train, y_train)
이 블록은 k-NN 회귀 모델을 초기화하고 훈련 데이터 세트에서 파생된 다항식 기능을 사용하여 훈련합니다.
6. 예측하기
y_pred = knn_model.predict(X_poly_test)
이 블록은 훈련된 모델을 사용하여 테스트 세트에 대해 예측합니다.
7. 결과 플롯
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color='blue', alpha=0.5, label='Data Points')
X_grid = np.linspace(0, 10, 1000).reshape(-1, 1)
X_poly_grid = poly.transform(X_grid)
y_grid = knn_model.predict(X_poly_grid)
plt.plot(X_grid, y_grid, color='red', linewidth=2, label=f'k-NN Regression (k={k}, Degree {degree})')
plt.title(f'k-NN Regression (Polynomial Degree {degree})')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
이 블록은 k-NN 회귀 모델의 예측 값과 실제 데이터 포인트의 산점도를 생성하여 적합 곡선을 시각화합니다.
k = 1인 출력:
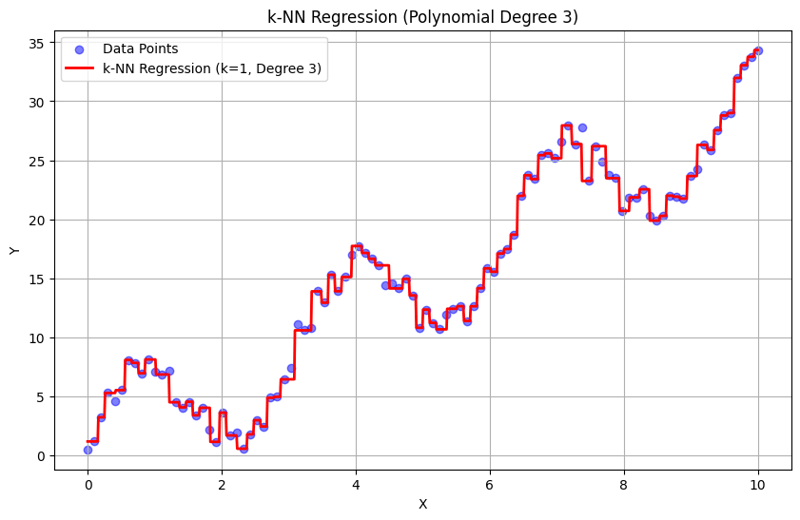
k = 10인 출력:
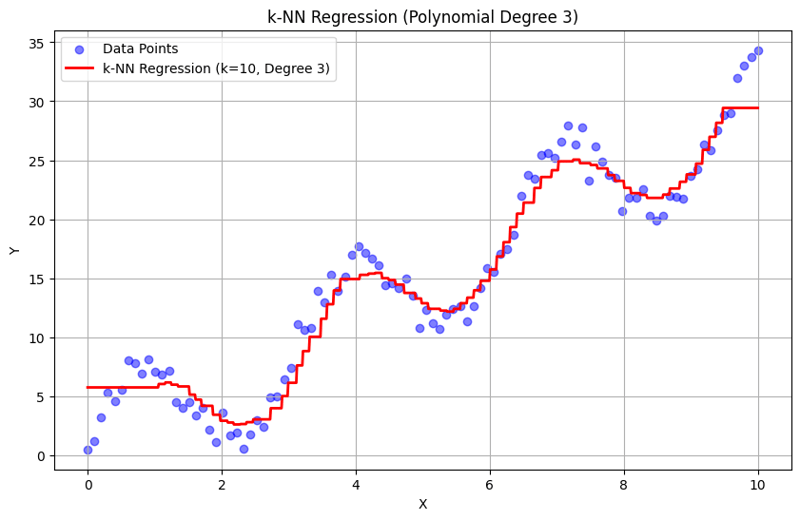
이 구조화된 접근 방식은 다항식 기능을 사용하여 k-최근접 이웃 회귀를 구현하고 평가하는 방법을 보여줍니다. k-NN 회귀는 인근 이웃의 응답 평균을 통해 로컬 패턴을 캡처함으로써 데이터의 복잡한 관계를 효과적으로 모델링하는 동시에 간단한 구현을 제공합니다. k와 다항식 차수의 선택은 모델의 성능과 기본 추세를 포착하는 유연성에 큰 영향을 미칩니다.
-
 C ++는 어떻게 유형 삭제를 달성 할 수 있습니까? 기술 비교?가상 함수 가상 함수는 인터페이스 기반 클래스 계층 구조 내에서 클래스의 구현을 추상화하는 고전적인 기술입니다. 이 접근법은 유형 또는 거래 메커니즘을 숨기기 위해 boost.any 및 boost.shared_ptr과 같은 많은 부스트 라이브러리에 의해 채...프로그램 작성 2025-02-07에 게시되었습니다
C ++는 어떻게 유형 삭제를 달성 할 수 있습니까? 기술 비교?가상 함수 가상 함수는 인터페이스 기반 클래스 계층 구조 내에서 클래스의 구현을 추상화하는 고전적인 기술입니다. 이 접근법은 유형 또는 거래 메커니즘을 숨기기 위해 boost.any 및 boost.shared_ptr과 같은 많은 부스트 라이브러리에 의해 채...프로그램 작성 2025-02-07에 게시되었습니다 -
PHP 컬 응답에서 쿠키를 변수로 추출하려면 어떻게해야합니까?PHP CURL 응답에서 쿠키 검색 외부 API 응답은 http 헤더 내에서 쿠키로 내장 될 수 있습니다. 비누 나 휴식과 같은 기존의 통신 프로토콜을 사용하는 대신. 이 쿠키를 힘든 구문 분석에 의지하지 않고 구조화 된 배열로 추출하는 것을 촉진하...프로그램 작성 2025-02-07에 게시되었습니다
-
PHP를 사용하여 MySQL에서 블로브로 저장된 이미지를 표시하는 방법은 무엇입니까?php GD 라이브러리 사용 : $ image = imageCreatefromString ($ blob); ob_start (); ImageJpeg ($ image, null, 80); $ data = ob_get_contents (); ob...프로그램 작성 2025-02-07에 게시되었습니다
-
교체 지시문을 사용하여 GO MOD에서 모듈 경로 불일치를 해결하는 방법은 무엇입니까?[ github.com/coreos/etcd/client github.com/coreos/etcd/client에 의해 테스트 된 Echoed 메시지에 의해 입증 된 바와 같이 이로 인해 깔끔한 실패가 발생할 수 있습니다. 테스트 수입 github.com/cor...프로그램 작성 2025-02-07에 게시되었습니다
-
McRypt에서 OpenSSL로 암호화를 마이그레이션하고 OpenSSL을 사용하여 McRypt 암호화 데이터를 해제 할 수 있습니까?질문 : McRypt에서 OpenSSL로 내 암호화 라이브러리를 업그레이드 할 수 있습니까? 그렇다면 어떻게? 대답 : 예, McRypt에서 OpenSSL로 암호화 라이브러리를 업그레이드 할 수 있습니다. OpenSSL? OpenSSL을 사용하여 Mc...프로그램 작성 2025-02-07에 게시되었습니다
-
\ "(1) 대 (;;) : 컴파일러 최적화는 성능 차이를 제거합니까? \"while (1) vs. for (;;) : 속도 차이가 있습니까? question : 는 (;;) 대신에 (1)을 사용하여 사용합니다. 최신 컴파일러, (1)과 (;)와 (;). 컴파일러에서 : perl : 둘 다 (1)과 (;;)는 ...프로그램 작성 2025-02-07에 게시되었습니다
-
버전 5.6.5 이전에 MySQL의 Timestamp 열을 사용하여 current_timestamp를 사용하는 데 제한 사항은 무엇입니까?5.6.5 이전에 mySQL 버전에서 기본적으로 또는 업데이트 클로즈가있는 타임 스탬프 열에서 제한 기본적으로 current_timestamp 또는 업데이트 current_timeStamp 절을 가진 타임 스탬프 열이 하나만있는 것으로 제한되는 제한이었습니다...프로그램 작성 2025-02-07에 게시되었습니다
-
PHP를 사용하여 Blob (이미지)을 MySQL에 올바르게 삽입하는 방법은 무엇입니까?php 가있는 MySQL 데이터베이스에 블로브를 삽입하면 MySQL 데이터베이스에 이미지를 저장하려고하면 발생할 수 있습니다. 문제. 이 안내서는 이미지 데이터를 성공적으로 저장하는 솔루션을 제공합니다. ressue $ sql = &qu...프로그램 작성 2025-02-07에 게시되었습니다
-
\ "일반 오류 : 2006 MySQL Server가 사라졌습니다 \"데이터를 삽입 할 때?] MySQL 데이터베이스에 삽입하면 때때로 "일반 오류 : 2006 MySQL 서버가 사라졌습니다."오류가 발생할 수 있습니다. 이 오류는 일반적으로 MySQL 구성의 두 변수 중 하나로 인해 서버에 대한 연결이 손실 될 때 발생합니다. 솔루션...프로그램 작성 2025-02-07에 게시되었습니다
-
MySQL에서 데이터를 피벗하여 그룹을 어떻게 사용할 수 있습니까?를 사용하여 데이터 시각화를 향상시키기 위해 행과 열의 재 배열을 나타냅니다. . 여기서 우리는 공통 도전에 접근합니다. 그룹 by. 합 또는 사례와 같은 조건부 응집 기능과 함께 절에 의해. 다음 쿼리를 고려해 봅시다 :...프로그램 작성 2025-02-07에 게시되었습니다
-
Object-Fit : IE 및 Edge에서 표지가 실패, 수정 방법?이 문제를 해결하기 위해 문제를 해결하는 영리한 CSS 솔루션을 사용합니다. > 위치 : 절대; 상단 : 50%; 왼쪽 : 50%; 변환 : 번역 (-50%, -50%); 높이 : 100%; 너비 : 자동; // 수직 블록의 경우 높이 : 자동; 너비 ...프로그램 작성 2025-02-07에 게시되었습니다
-
Firefox Back 버튼을 사용할 때 JavaScript 실행이 중단되는 이유는 무엇입니까?탐색 기록 문제 : javaScript가 Firefox 뒤로 버튼을 사용한 후 실행을 중단합니다 Firefox 사용자 뒤로 버튼을 통해 이전에 방문한 페이지로 돌아갑니다. 이 문제는 Chrome 및 Internet Explorer와 같은 다른 브라우저에...프로그램 작성 2025-02-07에 게시되었습니다
-
FormData ()로 여러 파일 업로드를 처리하려면 어떻게해야합니까?JavaScript에서 일반적인 접근 방식은 다음과 같습니다. fd.append ( "filetoupload", document.getElementById ( 'FiletOUPload'). [0]); ] 그러나이 코드는 첫 번째...프로그램 작성 2025-02-07에 게시되었습니다
-
열의 열이 다른 데이터베이스 테이블을 어떻게 통합하려면 어떻게해야합니까?다른 열이있는 결합 테이블 ] 는 데이터베이스 테이블을 다른 열로 병합하려고 할 때 도전에 직면 할 수 있습니다. 간단한 방법은 열이 적은 테이블의 누락 된 열에 null 값을 추가하는 것입니다. 예를 들어 예를 들어, 표 A와 표 B의 두 테이블을 고려...프로그램 작성 2025-02-07에 게시되었습니다
-
PHP를 사용하여 XML 파일에서 속성 값을 효율적으로 검색하려면 어떻게해야합니까?옵션> 1 목표는 데이터를 추출하는 전통적인 메소드가 당신을 괴롭힐 수있는 "varnum"속성 값을 검색하는 것일 수 있습니다. 이를 해결하려면 PHP simplexmlelement :: attributes () 함수를 사용...프로그램 작성 2025-02-07에 게시되었습니다















중국어 공부
- 1 "걷다"를 중국어로 어떻게 말하나요? 走路 중국어 발음, 走路 중국어 학습
- 2 "비행기를 타다"를 중국어로 어떻게 말하나요? 坐飞机 중국어 발음, 坐飞机 중국어 학습
- 3 "기차를 타다"를 중국어로 어떻게 말하나요? 坐火车 중국어 발음, 坐火车 중국어 학습
- 4 "버스를 타다"를 중국어로 어떻게 말하나요? 坐车 중국어 발음, 坐车 중국어 학습
- 5 운전을 중국어로 어떻게 말하나요? 开车 중국어 발음, 开车 중국어 학습
- 6 수영을 중국어로 뭐라고 하나요? 游泳 중국어 발음, 游泳 중국어 학습
- 7 자전거를 타다 중국어로 뭐라고 하나요? 骑自行车 중국어 발음, 骑自行车 중국어 학습
- 8 중국어로 안녕하세요를 어떻게 말해요? 你好중국어 발음, 你好중국어 학습
- 9 감사합니다를 중국어로 어떻게 말하나요? 谢谢중국어 발음, 谢谢중국어 학습
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









