
이미지 분할 마스터하기: 디지털 시대에도 기존 기술이 여전히 빛나는 이유
 검색:849
검색:849
소개
컴퓨터 비전의 가장 기본적인 절차 중 하나인 이미지 분할을 통해 시스템은 이미지 내의 다양한 영역을 분해하고 분석할 수 있습니다. 객체 인식, 의료 영상, 자율 주행 등 무엇을 다루든 분할은 이미지를 의미 있는 부분으로 나누는 것입니다.
이 작업에서 딥 러닝 모델의 인기가 계속 높아지고 있지만 디지털 이미지 처리의 기존 기술은 여전히 강력하고 실용적입니다. 이 게시물에서 검토되는 접근 방식에는 세포 이미지 분석을 위해 잘 알려진 데이터 세트인 MIVIA HEp-2 이미지 데이터 세트를 구현하여 임계값 지정, 가장자리 감지, 지역 기반 및 클러스터링이 포함됩니다.
MIVIA HEp-2 이미지 데이터세트
MIVIA HEp-2 이미지 데이터세트는 HEp-2 세포를 통해 항핵항체(ANA)의 패턴을 분석하는 데 사용되는 세포 사진 세트입니다. 형광현미경을 통해 촬영한 2D 사진으로 구성되어 있습니다. 이는 분할 작업, 특히 세포 영역 감지가 가장 중요한 의료 이미지 분석과 관련된 작업에 매우 적합합니다.
이제 F1 점수를 기준으로 성능을 비교하여 이러한 이미지를 처리하는 데 사용되는 분할 기술을 살펴보겠습니다.
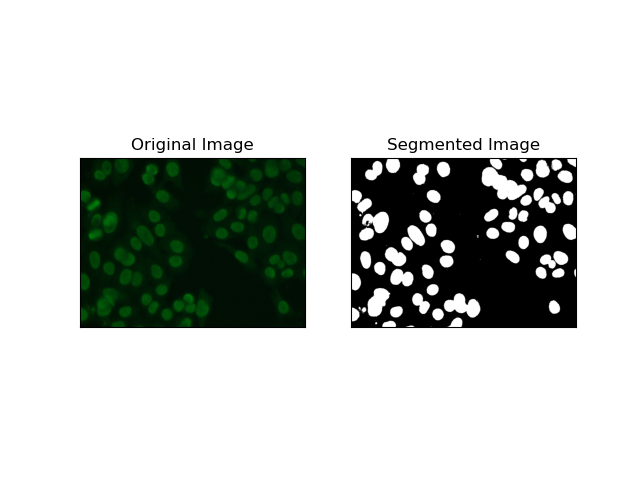
1. 임계값 분할
임계값은 회색조 이미지를 픽셀 강도에 따라 이진 이미지로 변환하는 프로세스입니다. MIVIA HEp-2 데이터세트에서 이 프로세스는 백그라운드에서 세포를 추출하는 데 유용합니다. 특히 Otsu의 방법을 사용하면 최적의 임계값을 자체 계산하므로 상대적으로 큰 수준까지 간단하고 효과적입니다.
Otsu의 방법은 자동 임계값 지정 방법으로, 클래스 내 분산을 최소화하기 위해 최상의 임계값을 찾아 전경(셀)과 배경이라는 두 클래스를 분리합니다. 이 방법은 이미지 히스토그램을 검사하고 각 클래스의 픽셀 강도 차이의 합이 최소화되는 완벽한 임계값을 계산합니다.
# Thresholding Segmentation
def thresholding(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY cv.THRESH_OTSU)
return thresh
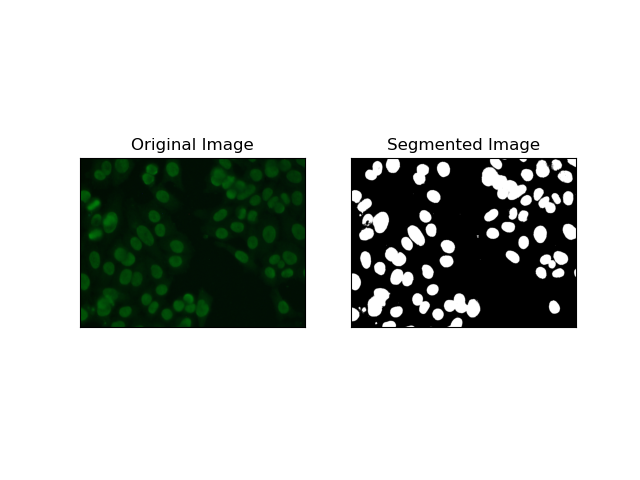
2. 가장자리 감지 분할
가장자리 감지는 MIVIA HEp-2 데이터 세트의 셀 가장자리와 같은 객체 또는 영역의 경계를 식별하는 것과 관련됩니다. 급격한 강도 변화를 감지하는 데 사용할 수 있는 많은 방법 중에서 Canny Edge Detector가 가장 좋고 따라서 셀룰러 경계를 감지하는 데 사용되는 가장 적절한 방법입니다.
Canny Edge Detector는 강도 기울기가 강한 영역을 감지하여 가장자리를 감지할 수 있는 다단계 알고리즘입니다. 이 프로세스는 가우스 필터를 사용한 평활화, 강도 기울기 계산, 가짜 응답을 제거하기 위한 비최대 억제 적용, 두드러진 가장자리만 유지하기 위한 최종 이중 임계값 연산을 구현합니다.
# Edge Detection Segmentation
def edge_detection(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Gaussian blur
gray = cv.GaussianBlur(gray, (3, 3), 0)
# Calculate lower and upper thresholds for Canny edge detection
sigma = 0.33
v = np.median(gray)
lower = int(max(0, (1.0 - sigma) * v))
upper = int(min(255, (1.0 sigma) * v))
# Apply Canny edge detection
edges = cv.Canny(gray, lower, upper)
# Dilate the edges to fill gaps
kernel = np.ones((5, 5), np.uint8)
dilated_edges = cv.dilate(edges, kernel, iterations=2)
# Clean the edges using morphological opening
cleaned_edges = cv.morphologyEx(dilated_edges, cv.MORPH_OPEN, kernel, iterations=1)
# Find connected components and filter out small components
num_labels, labels, stats, _ = cv.connectedComponentsWithStats(
cleaned_edges, connectivity=8
)
min_size = 500
filtered_mask = np.zeros_like(cleaned_edges)
for i in range(1, num_labels):
if stats[i, cv.CC_STAT_AREA] >= min_size:
filtered_mask[labels == i] = 255
# Find contours of the filtered mask
contours, _ = cv.findContours(
filtered_mask, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE
)
# Create a filled mask using the contours
filled_mask = np.zeros_like(gray)
cv.drawContours(filled_mask, contours, -1, (255), thickness=cv.FILLED)
# Perform morphological closing to fill holes
final_filled_image = cv.morphologyEx(
filled_mask, cv.MORPH_CLOSE, kernel, iterations=2
)
# Dilate the final filled image to smooth the edges
final_filled_image = cv.dilate(final_filled_image, kernel, iterations=1)
return final_filled_image
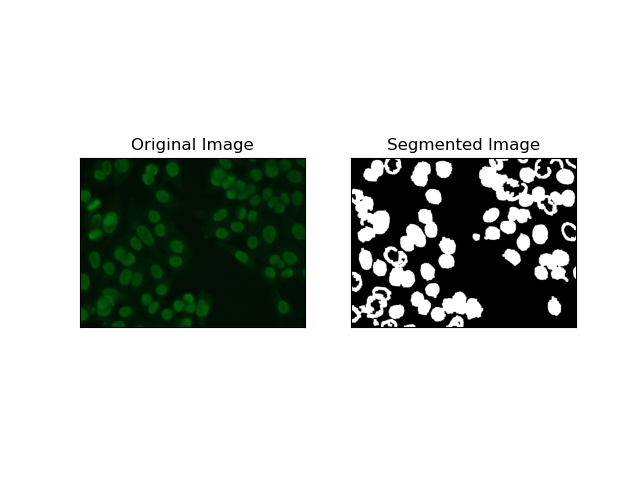
3. 지역 기반 세분화
영역 기반 분할은 강도나 색상과 같은 특정 기준에 따라 유사한 픽셀을 영역으로 그룹화합니다. 워터쉐드 분할 기술을 사용하면 HEp-2 세포 이미지를 분할하여 세포를 나타내는 영역을 감지할 수 있습니다. 픽셀 강도를 지형적 표면으로 간주하고 구별되는 영역의 윤곽을 그립니다.
유역 분할은 픽셀 강도를 지형 표면으로 처리합니다. 알고리즘은 지역적 최소값을 식별한 다음 점차적으로 이러한 유역을 범람시켜 별개의 지역을 확대하는 "유역"을 식별합니다. 이 기술은 현미경 이미지 내의 세포와 같이 접촉하는 물체를 분리하려고 할 때 매우 유용하지만 노이즈에 민감할 수 있습니다. 프로세스는 마커를 통해 안내될 수 있으며 과도한 세분화를 줄일 수 있는 경우가 많습니다.
# Region-Based Segmentation
def region_based(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV cv.THRESH_OTSU)
# Apply morphological opening to remove noise
kernel = np.ones((3, 3), np.uint8)
opening = cv.morphologyEx(thresh, cv.MORPH_OPEN, kernel, iterations=2)
# Dilate the opening to get the background
sure_bg = cv.dilate(opening, kernel, iterations=3)
# Calculate the distance transform
dist_transform = cv.distanceTransform(opening, cv.DIST_L2, 5)
# Threshold the distance transform to get the foreground
_, sure_fg = cv.threshold(dist_transform, 0.2 * dist_transform.max(), 255, 0)
sure_fg = np.uint8(sure_fg)
# Find the unknown region
unknown = cv.subtract(sure_bg, sure_fg)
# Label the markers for watershed algorithm
_, markers = cv.connectedComponents(sure_fg)
markers = markers 1
markers[unknown == 255] = 0
# Apply watershed algorithm
markers = cv.watershed(img, markers)
# Create a mask for the segmented region
mask = np.zeros_like(gray, dtype=np.uint8)
mask[markers == 1] = 255
return mask
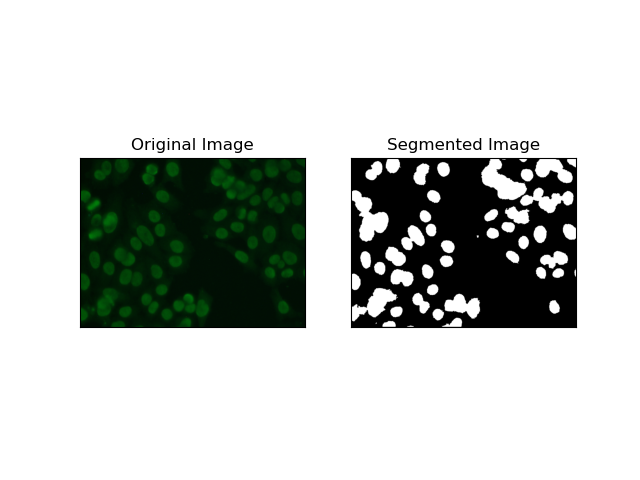
4. 클러스터링 기반 분할
K-평균과 같은 클러스터링 기술은 픽셀을 유사한 클러스터로 그룹화하는 경향이 있으며, 이는 HEp-2 세포 이미지에서 볼 수 있듯이 다색 또는 복잡한 환경에서 세포를 분할하려고 할 때 잘 작동합니다. 기본적으로 이는 셀룰러 영역 대 배경과 같은 다양한 클래스를 나타낼 수 있습니다.
K-평균은 색상이나 강도의 픽셀 유사성을 기반으로 이미지를 클러스터링하기 위한 비지도 학습 알고리즘입니다. 알고리즘은 K개의 중심을 무작위로 선택하고, 각 픽셀을 가장 가까운 중심에 할당하고, 수렴할 때까지 반복적으로 중심을 업데이트합니다. 이는 서로 매우 다른 여러 관심 영역이 있는 이미지를 분할하는 데 특히 효과적입니다.
# Clustering Segmentation
def clustering(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Reshape the image
Z = gray.reshape((-1, 3))
Z = np.float32(Z)
# Define the criteria for k-means clustering
criteria = (cv.TERM_CRITERIA_EPS cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# Set the number of clusters
K = 2
# Perform k-means clustering
_, label, center = cv.kmeans(Z, K, None, criteria, 10, cv.KMEANS_RANDOM_CENTERS)
# Convert the center values to uint8
center = np.uint8(center)
# Reshape the result
res = center[label.flatten()]
res = res.reshape((gray.shape))
# Apply thresholding to the result
_, res = cv.threshold(res, 0, 255, cv.THRESH_BINARY cv.THRESH_OTSU)
return res
F1 점수를 사용한 기술 평가
F1 점수는 예측된 분할 이미지와 실제 이미지를 비교하기 위해 정밀도와 재현율을 결합한 척도입니다. 이는 정밀도와 재현율의 조화 평균으로, 의료 영상 데이터 세트와 같이 데이터 불균형이 높은 경우에 유용합니다.
실측 정보와 분할된 이미지를 모두 평면화하고 가중치 F1 점수를 계산하여 각 분할 방법에 대한 F1 점수를 계산했습니다.
def calculate_f1_score(ground_image, segmented_image):
ground_image = ground_image.flatten()
segmented_image = segmented_image.flatten()
return f1_score(ground_image, segmented_image, average="weighted")
그런 다음 간단한 막대 차트를 사용하여 다양한 방법의 F1 점수를 시각화했습니다.
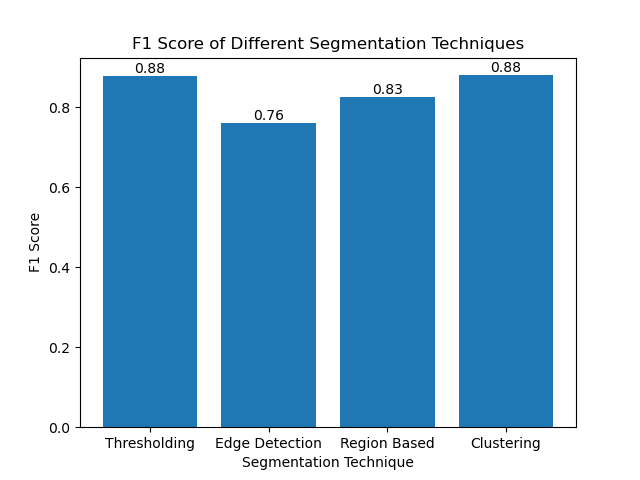
결론
이미지 분할을 위한 최근의 접근 방식이 많이 등장하고 있지만 임계값 지정, 가장자리 감지, 영역 기반 방법, 클러스터링과 같은 기존 분할 기술은 MIVIA HEp-2 이미지 데이터 세트와 같은 데이터 세트에 적용할 때 매우 유용할 수 있습니다.
각 방법에는 고유한 장점이 있습니다.
- 임계값은 간단한 이진 분할에 적합합니다.
- 가장자리 감지는 경계 감지에 이상적인 기술입니다.
- 지역 기반 분할은 연결된 구성 요소를 이웃 구성 요소와 분리하는 데 매우 유용합니다.
- 클러스터링 방법은 다중 지역 분할 작업에 매우 적합합니다.
F1 점수를 사용하여 이러한 방법을 평가함으로써 각 모델의 장단점을 이해합니다. 이러한 방법은 최신 딥 러닝 모델에서 개발된 것만큼 정교하지는 않지만 광범위한 애플리케이션에서 여전히 빠르고 해석 가능하며 서비스 가능합니다.
읽어주셔서 감사합니다! 전통적인 이미지 분할 기술에 대한 이러한 탐구가 귀하의 다음 프로젝트에 영감을 주기를 바랍니다. 아래 댓글로 여러분의 생각과 경험을 자유롭게 공유해 주세요!
-
 익명의 JavaScript 이벤트 처리기를 깨끗하게 제거하는 방법은 무엇입니까?익명 이벤트 리스너를 제거하는 데 익명의 이벤트 리스너 추가 요소를 추가하면 유연성과 단순성을 제공하지만 유연성과 단순성을 제공하지만 제거 할 시간이되면 요소 자체를 교체하지 않고 도전 할 수 있습니다. 요소? element.addeventListene...프로그램 작성 2025-04-03에 게시되었습니다
익명의 JavaScript 이벤트 처리기를 깨끗하게 제거하는 방법은 무엇입니까?익명 이벤트 리스너를 제거하는 데 익명의 이벤트 리스너 추가 요소를 추가하면 유연성과 단순성을 제공하지만 유연성과 단순성을 제공하지만 제거 할 시간이되면 요소 자체를 교체하지 않고 도전 할 수 있습니다. 요소? element.addeventListene...프로그램 작성 2025-04-03에 게시되었습니다 -
자바 스크립트 객체의 키를 알파벳순으로 정렬하는 방법은 무엇입니까?object.keys (...) . .sort () . 정렬 된 속성을 보유 할 새 개체를 만듭니다. 정렬 된 키 어레이를 반복하고 리소셔 함수를 사용하여 원래 객체에서 새 객체에 해당 값과 함께 각 키를 추가합니다. 다음 코드는 프로세...프로그램 작성 2025-04-03에 게시되었습니다
-
regex를 사용하여 PHP에서 괄호 안에서 텍스트를 추출하는 방법$ fullstring = "이 (텍스트)을 제외한 모든 것을 무시하는 것"; $ start = strpos ( ', $ fullstring); $ fullString); $ shortstring = substr ($ fulls...프로그램 작성 2025-04-03에 게시되었습니다
-
PHP를 사용하여 Blob (이미지)을 MySQL에 올바르게 삽입하는 방법은 무엇입니까?문제 $ sql = "삽입 ImagesTore (imageId, image) 값 ( '$ this- & gt; image_id', 'file_get_contents ($ tmp_image)'; 결과적으로 실제 이...프로그램 작성 2025-04-03에 게시되었습니다
-
버전 5.6.5 이전에 MySQL의 Timestamp 열을 사용하여 current_timestamp를 사용하는 데 제한 사항은 무엇입니까?5.6.5 이전에 mysql 버전의 기본적으로 또는 업데이트 클로즈가있는 타임 스탬프 열의 제한 사항 5.6.5 5.6.5 이전에 mySQL 버전에서 Timestamp Holumn에 전적으로 기본적으로 한 제한 사항이 있었는데, 이는 제한적으로 전혀 ...프로그램 작성 2025-04-03에 게시되었습니다
-
PHP \의 기능 재정의 제한을 극복하는 방법은 무엇입니까?return $ a * $ b; } 그러나 PHP 도구 벨트에는 숨겨진 보석이 있습니다. runkit_function_rename () runkit_function_rename ( 'this', 'that'); run...프로그램 작성 2025-04-03에 게시되었습니다
-
SQLALCHEMY 필터 조항에서 'Flake8'플래킹 부울 비교가 된 이유는 무엇입니까?데이터베이스 테이블의 부울 필드 (Obsoleted)는 비 초소형 테스트 사례의 수를 결정하는 데 사용됩니다. 이 코드는 필터 절에서 테스트 케이스를 사용합니다. casenum = session.query (testcase) .filter (testcas...프로그램 작성 2025-04-03에 게시되었습니다
-
선형 구배 배경에 줄무늬가있는 이유는 무엇이며 어떻게 고칠 수 있습니까?수직 지향적 구배의 경우, 신체 요소의 마진은 HTML 요소로 전파되어 8px 키가 큰 영역을 초래합니다. 그 후, 선형 등급은이 전체 높이에 걸쳐 확장되어 반복 패턴을 생성합니다. 솔루션 : 이 문제를 해결하기 위해 신체 요소에 충분한 높이가 있는지...프로그램 작성 2025-04-03에 게시되었습니다
-
교체 지시문을 사용하여 GO MOD에서 모듈 경로 불일치를 해결하는 방법은 무엇입니까?[ github.com/coreos/coreos/client github.com/coreos/etcd/client.test imports github.com/coreos/etcd/integration에 의해 테스트 된 Echoed 메시지에 의해 입증 된 바와...프로그램 작성 2025-04-03에 게시되었습니다
-
열의 열이 다른 데이터베이스 테이블을 어떻게 통합하려면 어떻게해야합니까?다른 열이있는 결합 테이블 ] 는 데이터베이스 테이블을 다른 열로 병합하려고 할 때 도전에 직면 할 수 있습니다. 간단한 방법은 열이 적은 테이블의 누락 된 열에 null 값을 추가하는 것입니다. 예를 들어, 표 B보다 더 많은 열이있는 두 개의 테이블을...프로그램 작성 2025-04-03에 게시되었습니다
-
\ "(1) 대 (;;) : 컴파일러 최적화는 성능 차이를 제거합니까? \"대답 : 대부분의 최신 컴파일러에는 (1)과 (;;). 컴파일러 : s-> 7 8 v-> 4를 풀립니다 -e syntax ok gcc : GCC에서 두 루프는 다음과 같이 동일한 어셈블리 코드로 컴파일합니다. . t_while : ...프로그램 작성 2025-04-03에 게시되었습니다
-
유효한 코드에도 불구하고 PHP의 입력을 캡처하는 사후 요청이없는 이유는 무엇입니까?post request 오작동 주소 php action='' action = "프로그램 작성 2025-04-03에 게시되었습니다
-
Visual Studio 2012의 DataSource 대화 상자에 MySQL 데이터베이스를 추가하는 방법은 무엇입니까?MySQL 커넥터 v.6.5.4가 설치되어 있지만 Entity 프레임 워크의 DataSource 대화 상자에 MySQL 데이터베이스를 추가 할 수 없습니다. 이를 해결하기 위해 MySQL 용 공식 Visual Studio 2012 통합은 MySQL 커넥터 v.6....프로그램 작성 2025-04-03에 게시되었습니다
-
Point-In-Polygon 감지에 더 효율적인 방법 : Ray Tracing 또는 Matplotlib \ 's Path.contains_points?Ray Tracing MethodThe ray tracing method intersects a horizontal ray from the point under examination with the polygon's sides. 교차로의 수를 계산하고 지점이 패...프로그램 작성 2025-04-03에 게시되었습니다
-
PHP 배열 키-값 이상 : 07 및 08의 호기심 사례 이해이 문제는 PHP의 주요 제로 해석에서 비롯됩니다. 숫자가 0 (예 : 07 또는 08)으로 접두사를 넣으면 PHP는 소수점 값이 아닌 옥탈 값 (기본 8)으로 해석합니다. 설명 : echo 07; // 인쇄 7 (10 월 07 = 10 진수 7) ...프로그램 작성 2025-04-03에 게시되었습니다















중국어 공부
- 1 "걷다"를 중국어로 어떻게 말하나요? 走路 중국어 발음, 走路 중국어 학습
- 2 "비행기를 타다"를 중국어로 어떻게 말하나요? 坐飞机 중국어 발음, 坐飞机 중국어 학습
- 3 "기차를 타다"를 중국어로 어떻게 말하나요? 坐火车 중국어 발음, 坐火车 중국어 학습
- 4 "버스를 타다"를 중국어로 어떻게 말하나요? 坐车 중국어 발음, 坐车 중국어 학습
- 5 운전을 중국어로 어떻게 말하나요? 开车 중국어 발음, 开车 중국어 학습
- 6 수영을 중국어로 뭐라고 하나요? 游泳 중국어 발음, 游泳 중국어 학습
- 7 자전거를 타다 중국어로 뭐라고 하나요? 骑自行车 중국어 발음, 骑自行车 중국어 학습
- 8 중국어로 안녕하세요를 어떻게 말해요? 你好중국어 발음, 你好중국어 학습
- 9 감사합니다를 중국어로 어떻게 말하나요? 谢谢중국어 발음, 谢谢중국어 학습
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









