
import streamlit as stimport numpy as npimport pandas as pdimport joblib
stremlit는 기계 학습 및 데이터 과학 프로젝트를 위한 맞춤형 웹 애플리케이션을 쉽게 만들고 공유할 수 있게 해주는 Python 라이브러리입니다.
numpy는 수치 계산을 위한 기본 Python 라이브러리입니다. 대규모 다차원 배열 및 행렬을 지원하고 이러한 배열에서 효율적으로 작동하는 수학적 함수 모음을 제공합니다.
data = { \\\"island\\\": island, \\\"bill_length_mm\\\": bill_length_mm, \\\"bill_depth_mm\\\": bill_depth_mm, \\\"flipper_length_mm\\\": flipper_length_mm, \\\"body_mass_g\\\": body_mass_g, \\\"sex\\\": sex,}input_df = pd.DataFrame(data, index=[0])encode = [\\\"island\\\", \\\"sex\\\"]input_encoded_df = pd.get_dummies(input_df, prefix=encode)입력 값은 Stremlit에서 생성된 입력 양식에서 검색되며, 범주형 변수는 모델 생성 시와 동일한 규칙을 사용하여 인코딩됩니다. 각 데이터의 순서도 모델 생성 당시와 동일해야 한다는 점에 유의하세요. 순서가 다를 경우 모델을 이용하여 예측을 실행할 때 오류가 발생합니다.
clf = joblib.load(\\\"penguin_classifier_model.pkl\\\")
\\\"penguin_classifier_model.pkl\\\"은 이전에 저장된 모델이 저장된 파일입니다. 이 파일에는 훈련된 RandomForestClassifier가 바이너리 형식으로 포함되어 있습니다. 이 코드를 실행하면 모델이 clf에 로드되어 새 데이터에 대한 예측 및 평가에 사용할 수 있습니다.
prediction = clf.predict(input_encoded_df)prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): 훈련된 모델을 사용하여 새로 인코딩된 입력 데이터에 대한 클래스를 예측하고 결과를 예측에 저장합니다.
clf.predict_proba(input_encoded_df): 각 클래스의 확률을 계산하고 결과를 예측_proba에 저장합니다.
Stremlit Community Cloud(https://streamlit.io/cloud)에 액세스하고 GitHub 저장소의 URL을 지정하여 개발된 애플리케이션을 인터넷에 게시할 수 있습니다.

@allison_horst의 작품(https://github.com/allisonhorst)
이 모델은 기계 학습 기술을 연습하기 위해 널리 알려진 데이터 세트인 Palmer Penguins 데이터 세트를 사용하여 교육되었습니다. 이 데이터 세트는 남극 팔머 군도의 세 가지 펭귄 종(Adelie, Chinstrap, Gentoo)에 대한 정보를 제공합니다. 주요 기능은 다음과 같습니다:
이 데이터 세트는 Kaggle에서 제공되며 여기에서 액세스할 수 있습니다. 특징의 다양성으로 인해 분류 모델을 구축하고 종 예측에서 각 특징의 중요성을 이해하는 데 탁월한 선택이 됩니다.
","image":"http://www.luping.net/uploads/20241006/17282217676702924713227.png","datePublished":"2024-11-02T21:56:21+08:00","dateModified":"2024-11-02T21:56:21+08:00","author":{"@type":"Person","name":"luping.net","url":"https://www.luping.net/articlelist/0_1.html"}} 검색:224
검색:224
기계 학습 모델은 기본적으로 데이터에서 예측을 하거나 패턴을 찾는 데 사용되는 규칙 또는 메커니즘의 집합입니다. 매우 간단하게 말하면(과도하게 단순화할 염려 없이) Excel에서 최소 제곱법을 사용하여 계산된 추세선도 모델입니다. 그러나 실제 응용 프로그램에 사용되는 모델은 그렇게 단순하지 않습니다. 단순한 방정식뿐만 아니라 더 복잡한 방정식과 알고리즘이 포함되는 경우가 많습니다.
이번 게시물에서는 매우 간단한 머신러닝 모델을 구축하고 이를 매우 간단한 웹 앱으로 출시하여 프로세스를 살펴보는 것부터 시작하겠습니다.
여기에서는 ML 모델 자체가 아닌 프로세스에만 중점을 두겠습니다. 또한 Streamlit 및 Streamlit Community Cloud를 사용하여 Python 웹 애플리케이션을 쉽게 출시하겠습니다.
머신러닝에 널리 사용되는 Python 라이브러리인 scikit-learn을 사용하면 단 몇 줄의 코드만으로 데이터를 빠르게 학습하고 모델을 생성하여 간단한 작업을 수행할 수 있습니다. 그런 다음 모델을 joblib를 사용하여 재사용 가능한 파일로 저장할 수 있습니다. 이 저장된 모델은 웹 애플리케이션의 일반 Python 라이브러리처럼 가져오거나 로드할 수 있으므로 앱이 훈련된 모델을 사용하여 예측을 할 수 있습니다!
앱 URL: https://yh-machine-learning.streamlit.app/
GitHub: https://github.com/yoshan0921/yh-machine-learning.git
이 앱을 사용하면 Palmer Penguins 데이터 세트에서 훈련된 Random Forest 모델의 예측을 검사할 수 있습니다. (훈련 데이터에 대한 자세한 내용은 이 문서의 끝부분을 참조하세요.)
구체적으로 모델은 종, 섬, 부리 길이, 지느러미 길이, 몸 크기, 성별을 포함한 다양한 특징을 기반으로 펭귄 종을 예측합니다. 사용자는 앱을 탐색하여 다양한 기능이 모델 예측에 어떤 영향을 미치는지 확인할 수 있습니다.
예측 화면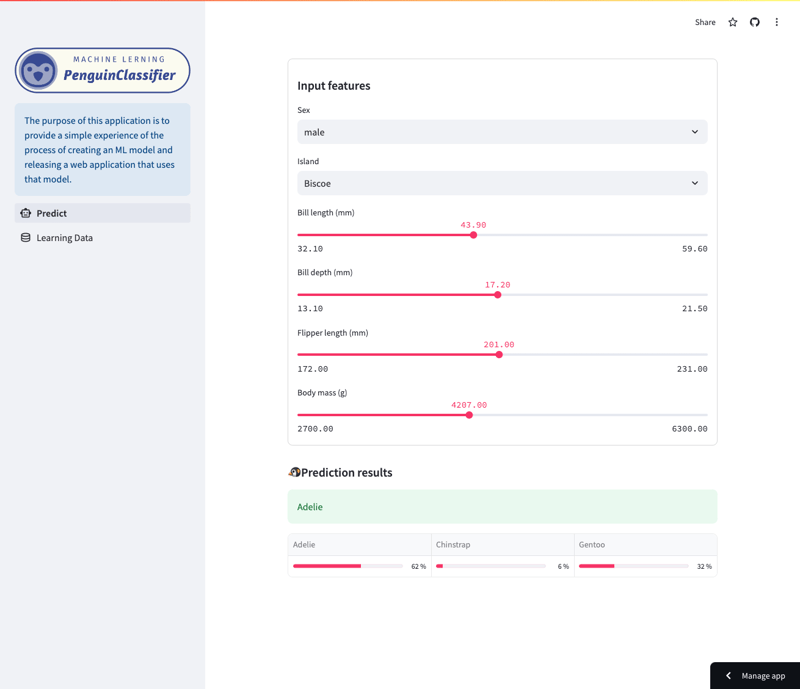
학습 데이터/시각화 화면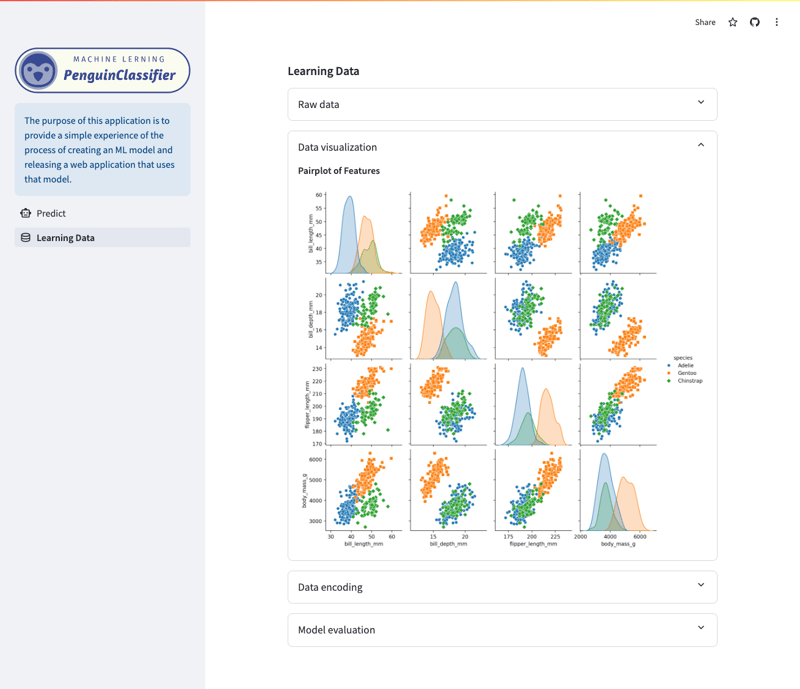
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import joblib
pandas는 데이터 조작 및 분석에 특화된 Python 라이브러리입니다. DataFrames를 사용하여 데이터 로드, 전처리 및 구조화를 지원하고 기계 학습 모델용 데이터를 준비합니다.
sklearn는 훈련 및 평가 도구를 제공하는 기계 학습을 위한 포괄적인 Python 라이브러리입니다. 이번 포스팅에서는 Random Forest라는 학습방법을 이용하여 모델을 구축해보겠습니다.
joblib는 기계 학습 모델과 같은 Python 개체를 매우 효율적인 방식으로 저장하고 로드하는 데 도움이 되는 Python 라이브러리입니다.
df = pd.read_csv("./dataset/penguins_cleaned.csv")
X_raw = df.drop("species", axis=1)
y_raw = df.species
데이터세트(훈련 데이터)를 로드하고 특성(X)과 대상 변수(y)로 분리합니다.
encode = ["island", "sex"]
X_encoded = pd.get_dummies(X_raw, columns=encode)
target_mapper = {"Adelie": 0, "Chinstrap": 1, "Gentoo": 2}
y_encoded = y_raw.apply(lambda x: target_mapper[x])
범주형 변수는 원-핫 인코딩(X_encoded)을 사용하여 숫자 형식으로 변환됩니다. 예를 들어, "island"에 "Biscoe", "Dream" 및 "Torgersen" 카테고리가 포함된 경우 각 카테고리(island_Biscoe, island_Dream, island_Torgersen)에 대해 새 열이 생성됩니다. 섹스에서도 마찬가지입니다. 원본 데이터가 "Biscoe"인 경우 island_Biscoe 열은 1로 설정되고 나머지 열은 0으로 설정됩니다.
대상 변수 종은 숫자 값(y_encoded)으로 매핑됩니다.
x_train, x_test, y_train, y_test = train_test_split(
X_encoded, y_encoded, test_size=0.3, random_state=1
)
모델을 평가하려면 훈련에 사용되지 않는 데이터에 대한 모델 성능을 측정해야 합니다. 7:3은 머신러닝의 일반적인 관행으로 널리 사용됩니다.
clf = RandomForestClassifier() clf.fit(x_train, y_train)
모델을 학습하는 데 적합 방법이 사용됩니다.
x_train은 설명변수에 대한 학습 데이터를 나타내고, y_train은 목표 변수를 나타냅니다.
이 메소드를 호출하면 훈련 데이터를 기반으로 훈련된 모델이 clf.
joblib.dump(clf, "penguin_classifier_model.pkl")
joblib.dump()는 Python 객체를 바이너리 형식으로 저장하는 함수입니다. 모델을 이 형식으로 저장하면 모델을 파일에서 로드하고 다시 학습할 필요 없이 있는 그대로 사용할 수 있습니다.
import streamlit as st import numpy as np import pandas as pd import joblib
stremlit는 기계 학습 및 데이터 과학 프로젝트를 위한 맞춤형 웹 애플리케이션을 쉽게 만들고 공유할 수 있게 해주는 Python 라이브러리입니다.
numpy는 수치 계산을 위한 기본 Python 라이브러리입니다. 대규모 다차원 배열 및 행렬을 지원하고 이러한 배열에서 효율적으로 작동하는 수학적 함수 모음을 제공합니다.
data = {
"island": island,
"bill_length_mm": bill_length_mm,
"bill_depth_mm": bill_depth_mm,
"flipper_length_mm": flipper_length_mm,
"body_mass_g": body_mass_g,
"sex": sex,
}
input_df = pd.DataFrame(data, index=[0])
encode = ["island", "sex"]
input_encoded_df = pd.get_dummies(input_df, prefix=encode)
입력 값은 Stremlit에서 생성된 입력 양식에서 검색되며, 범주형 변수는 모델 생성 시와 동일한 규칙을 사용하여 인코딩됩니다. 각 데이터의 순서도 모델 생성 당시와 동일해야 한다는 점에 유의하세요. 순서가 다를 경우 모델을 이용하여 예측을 실행할 때 오류가 발생합니다.
clf = joblib.load("penguin_classifier_model.pkl")
"penguin_classifier_model.pkl"은 이전에 저장된 모델이 저장된 파일입니다. 이 파일에는 훈련된 RandomForestClassifier가 바이너리 형식으로 포함되어 있습니다. 이 코드를 실행하면 모델이 clf에 로드되어 새 데이터에 대한 예측 및 평가에 사용할 수 있습니다.
prediction = clf.predict(input_encoded_df) prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): 훈련된 모델을 사용하여 새로 인코딩된 입력 데이터에 대한 클래스를 예측하고 결과를 예측에 저장합니다.
clf.predict_proba(input_encoded_df): 각 클래스의 확률을 계산하고 결과를 예측_proba에 저장합니다.
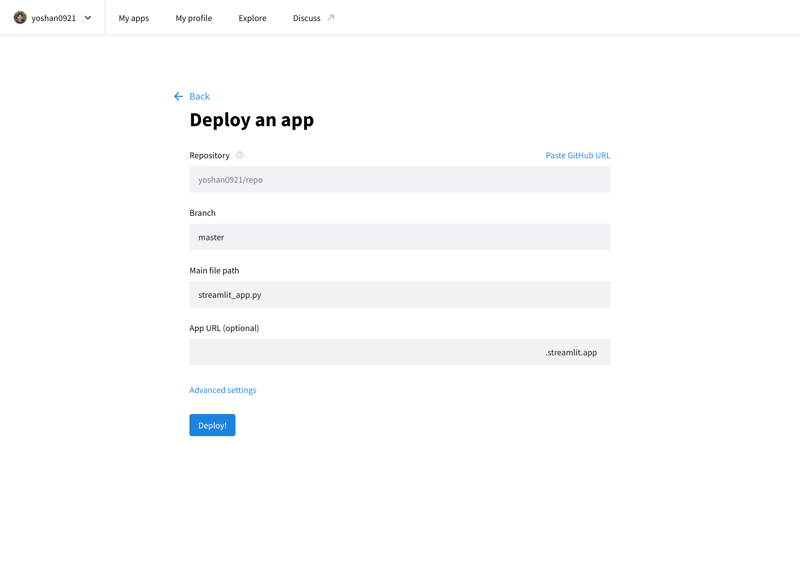
Stremlit Community Cloud(https://streamlit.io/cloud)에 액세스하고 GitHub 저장소의 URL을 지정하여 개발된 애플리케이션을 인터넷에 게시할 수 있습니다.

@allison_horst의 작품(https://github.com/allisonhorst)
이 모델은 기계 학습 기술을 연습하기 위해 널리 알려진 데이터 세트인 Palmer Penguins 데이터 세트를 사용하여 교육되었습니다. 이 데이터 세트는 남극 팔머 군도의 세 가지 펭귄 종(Adelie, Chinstrap, Gentoo)에 대한 정보를 제공합니다. 주요 기능은 다음과 같습니다:
이 데이터 세트는 Kaggle에서 제공되며 여기에서 액세스할 수 있습니다. 특징의 다양성으로 인해 분류 모델을 구축하고 종 예측에서 각 특징의 중요성을 이해하는 데 탁월한 선택이 됩니다.







![[일일 패키지] ms](http://www.luping.net/uploads/20241006/17282235656702994dea8b1.jpg)






부인 성명: 제공된 모든 리소스는 부분적으로 인터넷에서 가져온 것입니다. 귀하의 저작권이나 기타 권리 및 이익이 침해된 경우 자세한 이유를 설명하고 저작권 또는 권리 및 이익에 대한 증거를 제공한 후 이메일([email protected])로 보내주십시오. 최대한 빨리 처리해 드리겠습니다.
Copyright© 2022 湘ICP备2022001581号-3











