
LLM 너머: 소규모 언어 모델이 AI의 미래인 이유
 검색:622
검색:622
대형 언어 모델(LLM)이 Open AI의 ChatGPT 출시로 주목을 받았습니다. 그 이후로 몇몇 회사에서도 LLM을 시작했지만 이제는 더 많은 회사가 소규모 언어 모델(SLM)로 기울고 있습니다.
SLM이 탄력을 받고 있는데 SLM이 무엇이며 LLM과 어떻게 다른가요?
작은 언어 모델이란 무엇입니까?
SLM(Small Language Model)은 매개 변수가 더 적은 일종의 인공 지능 모델입니다(이를 훈련 중에 학습된 모델의 값으로 생각하세요). 더 큰 규모의 SLM과 마찬가지로 SLM은 텍스트를 생성하고 다른 작업을 수행할 수 있습니다. 그러나 SLM은 훈련에 더 적은 데이터 세트를 사용하고 매개변수도 적으며 훈련 및 실행에 필요한 계산 능력도 더 적습니다.
SLM은 주요 기능에 중점을 두고 있으며 설치 공간이 작다는 것은 SLM이 다음을 포함한 다양한 장치에 배포될 수 있음을 의미합니다. 모바일 장치와 같은 고급 하드웨어가 없습니다. 예를 들어 Google의 Nano는 모바일 장치에서 실행되도록 처음부터 구축된 온디바이스 SLM입니다. 회사에 따르면 Nano는 크기가 작기 때문에 네트워크 연결 유무에 관계없이 로컬로 실행할 수 있습니다.
Nano 외에도 AI 분야의 선도 기업과 향후 기업의 SLM이 많이 있습니다. 일부 인기 있는 SLM에는 Microsoft의 Phi-3, OpenAI의 GPT-4o mini, Anthropic의 Claude 3 Haiku, Meta의 Llama 3 및 Mistral AI의 Mixtral 8x7B가 포함됩니다.
다른 옵션도 사용할 수 있습니다. LLM이라고 생각할 수도 있지만 실제로는 SLM. 이는 대부분의 회사가 포트폴리오에 둘 이상의 언어 모델을 출시하고 LLM과 SLM을 모두 제공하는 다중 모델 접근 방식을 취하고 있다는 점을 고려할 때 특히 그렇습니다. 한 예로 GPT-4, GPT-4o(Omni), GPT-4o mini 등 다양한 모델이 있는 GPT-4가 있습니다.
소규모 언어 모델과 대규모 언어 모델
SLM을 논의하는 동안 우리는 SLM의 큰 상대인 LLM을 무시할 수 없습니다. SLM과 LLM의 주요 차이점은 매개변수 측면에서 측정되는 모델 크기입니다.
이 글을 쓰는 시점에서 AI 업계에서는 모델이 사용하지 말아야 할 최대 매개변수 수에 대한 합의가 없습니다. SLM으로 간주되기 위한 초과 또는 LLM으로 간주되기 위해 필요한 최소 수를 초과합니다. 그러나 SLM에는 일반적으로 수백만에서 수십억 개의 매개변수가 있는 반면, LLM에는 최대 수조에 달하는 매개변수가 있습니다.
예를 들어, 2020년에 출시된 GPT-3에는 1,750억 개의 매개변수가 있습니다(그리고 GPT-4 모델에는 약 1조 7600억 개가 있다는 소문이 있습니다. 반면 Microsoft의 2024 Phi-3-mini, Phi-3-Small 및 Phi-3-medium SLM은 각각 3.8, 7, 140억 개의 매개변수를 측정합니다.
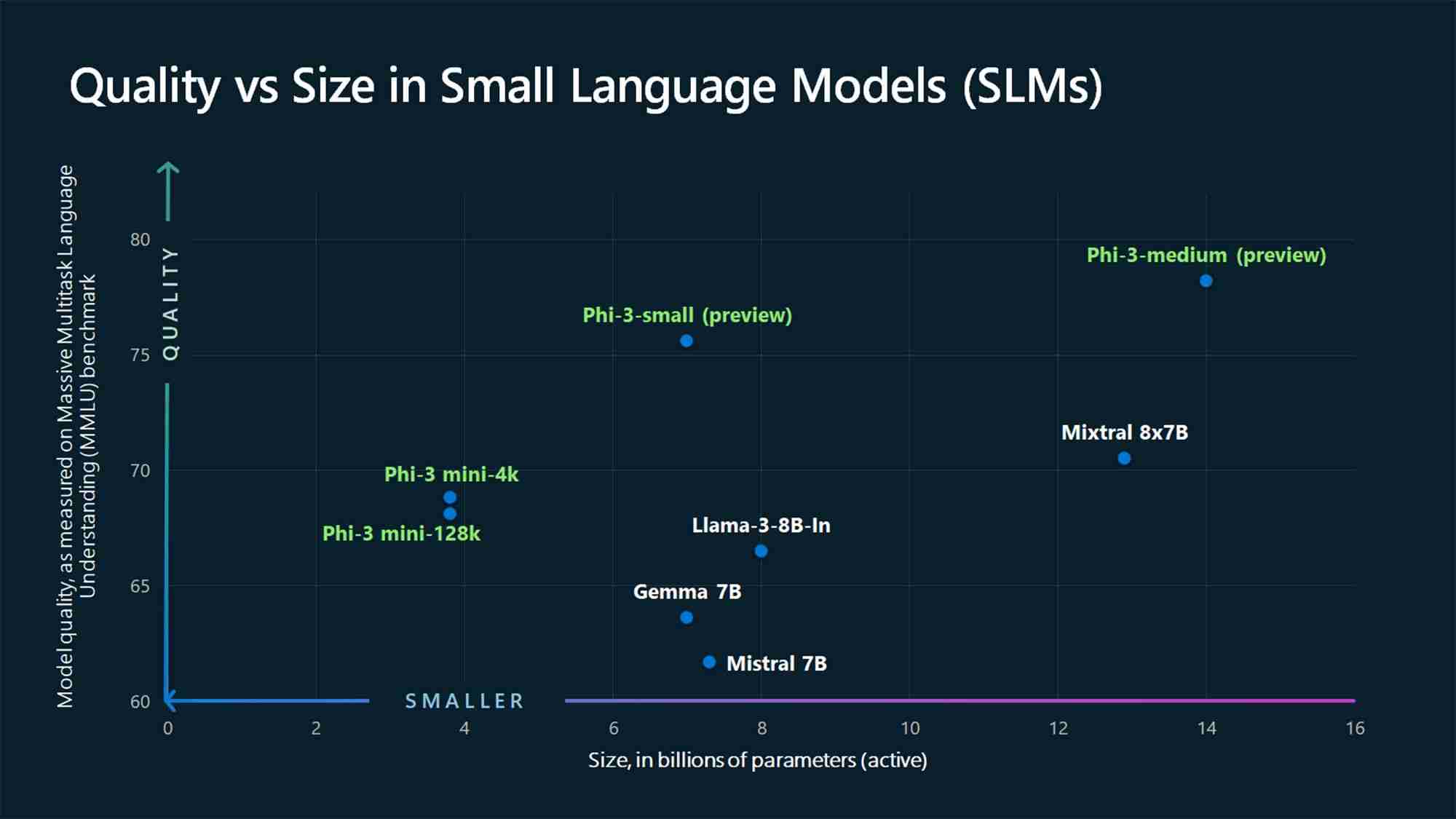
SLM과 LLM의 또 다른 차별화 요소는 교육에 사용되는 데이터의 양입니다. SLM은 더 적은 양의 데이터를 학습하는 반면, LLM은 대규모 데이터 세트를 사용합니다. 이러한 차이는 복잡한 작업을 해결하는 모델의 기능에도 영향을 미칩니다.
훈련에 사용되는 대규모 데이터로 인해 LLM은 고급 추론이 필요한 다양한 유형의 복잡한 작업을 해결하는 데 더 적합하고 SLM은 단순한 작업에 더 적합합니다. 작업. LLM과 달리 SLM은 훈련 데이터를 덜 사용하지만 작은 패키지로 LLM에서 제공하는 많은 기능을 달성하려면 사용되는 데이터의 품질이 더 높아야 합니다.
소형 언어 모델이 미래인 이유
대부분의 사용 사례에서 SLM은 기업과 소비자가 다양한 작업을 수행하는 데 사용하는 주류 모델이 되기에 더 나은 위치에 있습니다. 물론 LLM에는 장점이 있으며 복잡한 작업 해결과 같은 특정 사용 사례에 더 적합합니다. 그러나 SLM은 다음과 같은 이유로 대부분의 사용 사례에서 미래입니다.
1. 낮은 교육 및 유지 관리 비용

SLM은 LLM보다 교육에 데이터가 덜 필요하므로 교육 데이터, 재정 또는 둘 모두가 제한된 개인 및 중소기업을 위한 가장 실행 가능한 옵션입니다. LLM에는 많은 양의 훈련 데이터가 필요하며, 더 나아가 훈련과 실행을 모두 위해서는 막대한 컴퓨팅 리소스가 필요합니다.
이를 관점에서 볼 때 OpenAI의 CEO인 Sam Altman은 훈련에 1억 달러 이상이 소요되었음을 확인했습니다. MIT의 한 행사에서 연설하는 동안 GPT-4(Wired 기준). 또 다른 예는 Meta의 OPT-175B LLM입니다. Meta는 CNBC에 따르면 단위당 약 $10,000의 비용이 드는 992개의 NVIDIA A100 80GB GPU를 사용하여 훈련했다고 밝혔습니다. 에너지, 급여 등과 같은 기타 비용을 제외하면 비용은 약 900만 달러에 이릅니다.
이런 수치로 볼 때 중소기업이 LLM을 교육하는 것은 실행 가능하지 않습니다. 이와 대조적으로 SLM은 리소스 측면에서 진입 장벽이 낮고 운영 비용이 저렴하므로 더 많은 기업이 SLM을 채택할 것입니다.
2. 더 나은 성능

성능도 또 다른 요소입니다. SLM이 컴팩트한 크기로 인해 LLM을 능가하는 영역입니다. SLM은 대기 시간이 짧고 실시간 애플리케이션과 같이 더 빠른 응답이 필요한 시나리오에 더 적합합니다. 예를 들어, 디지털 보조 장치와 같은 음성 응답 시스템에서는 더 빠른 응답이 선호됩니다.
기기에서 실행(자세한 내용은 나중에 설명)한다는 것은 요청이 온라인 서버를 방문했다가 다시 돌아올 필요가 없음을 의미합니다. 쿼리에 응답하면 더 빠른 응답을 얻을 수 있습니다.
3. 더 정확함

생성 AI의 경우 한 가지 변함없는 점은 쓰레기가 들어오면 쓰레기가 나온다는 것입니다. 현재 LLM은 원시 인터넷 데이터의 대규모 데이터 세트를 사용하여 교육되었습니다. 따라서 모든 상황에서 정확하지 않을 수도 있습니다. 이는 ChatGPT 및 유사 모델의 문제점 중 하나이며 AI 챗봇이 말하는 모든 것을 신뢰해서는 안되는 이유입니다. 반면, SLM은 LLM보다 고품질 데이터를 사용하여 훈련되므로 정확도가 더 높습니다.
SLM은 특정 작업이나 영역에 대한 집중적인 훈련을 통해 더욱 세부적으로 조정할 수 있으므로 해당 작업의 정확도가 높아집니다. 더 크고 일반화된 모델에 비해 영역이 넓습니다.
4. 온디바이스 실행 가능

SLM은 LLM보다 컴퓨팅 성능이 덜 필요하므로 엣지 컴퓨팅 사례에 이상적입니다. 이는 큰 컴퓨팅 성능이나 리소스가 없는 스마트폰 및 자율주행차와 같은 엣지 장치에 배포될 수 있습니다. Google의 Nano 모델은 기기에서 실행될 수 있으므로 인터넷에 연결되어 있지 않아도 작동할 수 있습니다.
이 기능은 기업과 소비자 모두에게 윈윈(win-win) 상황을 제시합니다. 첫째, 사용자 데이터가 클라우드로 전송되지 않고 로컬로 처리되므로 개인 정보 보호 측면에서 승리합니다. 이는 우리에 대한 거의 모든 세부 정보를 담고 있는 스마트폰에 더 많은 AI가 통합됨에 따라 중요합니다. AI 작업을 처리하기 위해 대규모 서버를 배포하고 실행할 필요가 없기 때문에 기업에게도 유리합니다.
SLM은 Open AI, Google, Microsoft, Anthropic, Meta 등이 이러한 모델을 출시하고 있습니다. 이러한 모델은 우리 대부분이 LLM을 사용하는 간단한 작업에 더 적합합니다. 그러므로 그들은 미래입니다.
하지만 LLM은 아무데도 가지 않습니다. 대신, 의학 연구와 같이 다양한 영역의 정보를 결합하여 새로운 것을 창조하는 고급 애플리케이션에 사용됩니다.
-
 8 LLM에 대한 필수 무료 및 유료 API 권장 사항LLM의 힘을 활용 : 대형 언어 모델을위한 API에 대한 안내서 오늘날의 동적 비즈니스 환경에서 API (Application Programming Interfaces)는 AI 기능을 통합하고 활용하는 방법에 혁명을 일으키고 있습니다. 그들은 필수 다리 역할을...일체 포함 2025-04-21에 게시되었습니다
8 LLM에 대한 필수 무료 및 유료 API 권장 사항LLM의 힘을 활용 : 대형 언어 모델을위한 API에 대한 안내서 오늘날의 동적 비즈니스 환경에서 API (Application Programming Interfaces)는 AI 기능을 통합하고 활용하는 방법에 혁명을 일으키고 있습니다. 그들은 필수 다리 역할을...일체 포함 2025-04-21에 게시되었습니다 -
사용자 안내서 : Falcon 3-7B Instruct 모델Tii의 Falcon 3 : 오픈 소스 AI의 혁명적 인 도약 Tii의 야심 찬 재정의 AI 추구는 Advanced Falcon 3 모델로 새로운 높이에 도달합니다. 이 최신 반복은 새로운 성능 벤치 마크를 설정하여 오픈 소스 AI의 기능을 크게 발전시킵니다. ...일체 포함 2025-04-20에 게시되었습니다
-
DeepSeek-V3 vs. GPT-4O 및 LLAMA 3.3 70B : 가장 강력한 AI 모델 공개The evolution of AI language models has set new standards, especially in the coding and programming landscape. Leading the c...일체 포함 2025-04-18에 게시되었습니다
-
상위 5 개 AI 지능형 예산 도구AI로 재무 자유 잠금 해제 : 인도 최고의 예산 앱 돈이 어디로 가는지 궁금해하는 것에 지쳤습니까? 청구서는 수입을 삼키는 것처럼 보입니까? 인공 지능 (AI)은 강력한 솔루션을 제공합니다. AI 예산 책정 도구는 실시간 재무 통찰력, 개인화 된 권장 사항 ...일체 포함 2025-04-17에 게시되었습니다
-
Excel SumProduct 기능에 대한 자세한 설명 - 데이터 분석 학교Excel의 SumProduct 기능 : 데이터 분석 강국 간소화 된 데이터 분석을 위해 Excel의 SumProduct 기능의 힘을 잠금 해제합니다. 이 다재다능한 기능은 합산 및 곱셈 기능을 쉽게 결합하여 해당 범위 또는 배열에 걸쳐 추가, 뺄셈 및 분할까지 ...일체 포함 2025-04-16에 게시되었습니다
-
심층적 인 연구는 완전히 개방적이며 Chatgpt와 사용자 혜택이 있습니다Openai의 깊은 연구 : AI Research의 게임 체인저 Openai는 모든 Chatgpt Plus 가입자에 대한 깊은 연구를 시작하여 연구 효율성이 크게 향상되었습니다. Gemini, Grok 3 및 Perplexity와 같은 경쟁사들로부터 유사한 기능...일체 포함 2025-04-16에 게시되었습니다
-
Amazon Nova 오늘 실제 경험 및 검토 - 분석 VidhyaAmazon은 Nova : 향상된 AI 및 컨텐츠 제작을위한 최첨단 기초 모델을 공개합니다 Amazon의 최근 Re : Invent 2024 이벤트는 AI 및 컨텐츠 제작에 혁명을 일으키기 위해 고안된 가장 진보 된 기초 모델 인 Nova를 선보였습니다. 이 기사...일체 포함 2025-04-16에 게시되었습니다
-
chatgpt 타이밍 작업 기능을 사용하는 5 가지 방법Chatgpt의 새로운 예정된 작업 : ai 로 하루를 자동화하십시오. Chatgpt는 최근 게임 변화 기능을 소개했습니다 : 예약 된 작업. 이를 통해 사용자는 반복적 인 프롬프트를 자동화하여 오프라인에서도 미리 정해진 시간에 알림이나 응답을받을 수 있습니다. ...일체 포함 2025-04-16에 게시되었습니다
-
세 개의 AI 챗봇 중 어느 것이 동일한 프롬프트에 응답하는 것이 가장 좋습니까?여기에 내가 찾은 것이 있습니다. 가 잘 생산되는 프롬프트를 만들어냅니다. 모든 도구와 마찬가지로 출력은 사용하는 사람의 기술만큼이나 좋습니다. ai 챗봇은 다르지 않습니다. 이 이해를 통해 각 모델에 개인 금융에 중점을 둔 기본 안내서...일체 포함 2025-04-15에 게시되었습니다
-
chatgpt는 충분하고 전용 AI 채팅 기계가 필요하지 않습니다.새로운 AI 챗봇이 매일 시작되는 세상에서 어느 것이 "하나"인지 결정하는 것이 압도적 일 수 있습니다. 그러나 내 경험상, Chatgpt는 약간의 신속한 엔지니어링으로 플랫폼간에 전환 할 필요없이 내가 던지는 거의 모든 것을 처리합니다. 전...일체 포함 2025-04-14에 게시되었습니다
-
Indian AI Moment : Generative AI에서 중국 및 미국과의 경쟁인도의 AI 야망 : 2025 업데이트 중국과 미국이 생성 AI에 많은 투자를하면서 인도는 자체 Genai 이니셔티브를 가속화하고 있습니다. 인도의 다양한 언어 및 문화 환경을 수용하는 토착민 대형 언어 모델 (LLM)과 AI 도구에 대한 긴급한 필요성은 부인할...일체 포함 2025-04-13에 게시되었습니다
-
Airflow 및 Docker를 사용하여 CSV의 CSV 가져 오기이 튜토리얼은 CSV 파일에서 데이터베이스로 데이터 전송을 자동화하기 위해 Apache Airflow, Docker 및 PostgreSQL을 사용하여 강력한 데이터 파이프 라인을 구축하는 것을 보여줍니다. 효율적인 워크 플로 관리를위한 DAG, 작업 및 운영자와 같은...일체 포함 2025-04-12에 게시되었습니다
-
Swarm Intelligence 알고리즘 : 세 가지 파이썬 구현Imagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...일체 포함 2025-03-24에 게시되었습니다
-
래그 및 미세 조정으로 LLM을 더 정확하게 만드는 방법Imagine studying a module at university for a semester. At the end, after an intensive learning phase, you take an exam – and you can recall th...일체 포함 2025-03-24에 게시되었습니다
-
Google Gemini는 무엇입니까? Google의 Chatgpt 라이벌에 대해 알아야 할 모든 것Google recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members ...일체 포함 2025-03-23에 게시되었습니다















중국어 공부
- 1 "걷다"를 중국어로 어떻게 말하나요? 走路 중국어 발음, 走路 중국어 학습
- 2 "비행기를 타다"를 중국어로 어떻게 말하나요? 坐飞机 중국어 발음, 坐飞机 중국어 학습
- 3 "기차를 타다"를 중국어로 어떻게 말하나요? 坐火车 중국어 발음, 坐火车 중국어 학습
- 4 "버스를 타다"를 중국어로 어떻게 말하나요? 坐车 중국어 발음, 坐车 중국어 학습
- 5 운전을 중국어로 어떻게 말하나요? 开车 중국어 발음, 开车 중국어 학습
- 6 수영을 중국어로 뭐라고 하나요? 游泳 중국어 발음, 游泳 중국어 학습
- 7 자전거를 타다 중국어로 뭐라고 하나요? 骑自行车 중국어 발음, 骑自行车 중국어 학습
- 8 중국어로 안녕하세요를 어떻게 말해요? 你好중국어 발음, 你好중국어 학습
- 9 감사합니다를 중국어로 어떻게 말하나요? 谢谢중국어 발음, 谢谢중국어 학습
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









